

Die meisten Ratschläge zu “Inhalten für KI” sind selbst Massenware
Die Aufforderung, “großartige Inhalte für KI zu erstellen”, ist überall zu finden, und fast alle sagen dasselbe: Schreiben Sie hilfreiche, gut strukturierte Seiten und fügen Sie Schema hinzu. Dieser Rat ist wahr, generisch und nutzlos, weil er genau das beschreibt, was bereits alle tun.
Wir wollten eine schwerere Antwort, also haben wir uns unsere eigene Arbeit angesehen. Wir haben die 10 besten Artikel, die WISLR veröffentlicht, und die Daten dahinter ausgewertet. Das Muster war scharf genug, um die Frage zu klären. In den letzten 30 Tagen wurden diese 10 Artikel über 4.000 Mal in den großen LLMs zitiert, und in der klassischen Suche halten sie durchschnittliche Positionen von 4 bis 8. Unsere breiten Massenware-Ratgeber, auf derselben Domain und mit derselben Autorität im Rücken, kommen nicht annähernd heran, weil die Themen gesättigt sind und nichts unsere Seite hervorhebt.
Dieser Artikel ist die Analyse: was die Daten zeigen, was die 10 Artikel gemeinsam haben und wie Sie dasselbe Playbook auf Ihre eigenen Inhalte anwenden.
Die Daten: Gleiche Domain, gegensätzliche Ergebnisse
Der sauberste Weg, um zu erkennen, was KI belohnt, ist der Vergleich zweier Arten von Inhalten auf einer Website, denn so bleibt die Domain-Autorität konstant. Die Suchposition ist nicht mehr die Anzeigetafel. Was zählt, ist, ob ein LLM nach der Seite greift, wenn es eine Antwort aufbaut. In den letzten 30 Tagen wurden die 10 Artikel unten über 4.000 Mal in den großen KI-Engines zitiert.
Letzte 30 Tage · wislr.com Artikel-Set
Dies sind die Nicht-Massenware-Artikel, die diese Zitate antreiben. Jeder zielt auf etwas Neues, Spezifisches oder durch Daten Gestütztes, die wir selbst erzeugt haben, und jeder hält zugleich eine starke klassische Suchposition (September 2025 bis Juni 2026):
| Artikel | Durchschn. Position | Impressionen |
|---|---|---|
| OpenAI KPIs and Success Metrics | 4.53 | 114 |
| The Shopify Agentic Plan | 6.38 | 269 |
| Shopify Same-Domain Checkout Analytics | 6.48 | 1,436 |
| Pros and Cons of the Cloudflare /crawl Endpoint | 6.63 | 3,417 |
| Best Cloudflare /crawl Settings | 6.67 | 2,369 |
| AI Bot Behavior Log Analysis | 7.07 | 1,232 |
| AEO Readiness Comparison | 7.61 | 741 |
| Storebot-Google Checkout Verification | 7.82 | 317 |
| Shopify CDN Request Logging | 8.55 | 2,081 |
Zum Kontrast: Dieselbe Domain veröffentlicht auch kompetente Massenware-Ratgeber, die auf Suchanfragen wie “shopify redirects”, “301 redirect shopify” und “shopify url redirects” abzielen. Diese Seiten sammeln jeweils Hunderte von Impressionen, sodass Google klar versteht, worum es geht. Sie brechen dennoch nicht durch, weil bereits Tausende Seiten dieselbe Frage beantworten und nichts an unserer einem Modell einen Grund gibt, sie zu bevorzugen. Allein die Redirect-Pillar-Seite sammelt 14.916 Impressionen zu einer vollständig gesättigten Suchanfrage.
Gleiche Domain. Die Artikel, die zitiert werden, sind die, die sonst niemand hätte schreiben können.
Das Muster in einem Satz
Bei fester Domain entscheiden Themenauswahl und Originaldaten darüber, ob Sie zitiert werden. Diese Entscheidungen sind der Grund, warum dieses Artikel-Set in 30 Tagen über 4.000 LLM-Zitate erzielte. Autorität ist nicht der Hebel, für den die meisten Marken sie halten.
Was wir untersucht haben
Die 10 Artikel erstrecken sich über Februar bis Mai 2026 und behandeln das Verhalten von KI-Bots, den Cloudflare-Crawl-Endpunkt, die Shopify-Checkout-Verifizierung, die Messung von LLM-Traffic, den agentischen Handel und ein Wachstumsframework aus sechs Toren. Für jeden haben wir seine These, die Originaldaten dahinter, seine Struktur und seine Search-Console-Leistung erfasst. Anschließend haben wir die Daten auf Anfrageebene abgeglichen, um nicht nur zu sehen, welche Seiten rankten, sondern wofür genau.
Die Anfragedaten tragen den größten Teil der Belege, also lesen Sie sie direkt.
Das Indiz: Wir werden in Fragen gezogen, für die niemand optimiert hat
Klassisches SEO zielt auf Keywords. Inhalte werden nun in Antworten auf vollständige, unsaubere, spezifische Fragen gezogen, und genau daher kommen die Zitate. WISLRs Anfragebericht zeigt die Form dieser Prompts. Hier sind echte Suchanfragen, für die die Domain auf der ersten Seite erscheint, dieselben Fragen, in die LLMs greifen, um sie aus unseren Artikeln zu beantworten:
| Suchanfrage | Durchschn. Position |
|---|---|
| “which is better for measuring referral traffic coming from llms, profound or growthx? provide a definitive answer, along with a list of pros and cons specific to measuring referral traffic from llms for each.” | 4.78 |
| “shopify ventures readiness probe” | 1.99 |
| “cloudflare /crawl endpoint pricing” | 4.95 |
| “cloudflare crawl cost” | 4.0 |
| “openai kpi” | 5.67 |
| “linkupbot” | 7.85 |
| “meta-webindexer” | 8.0 |
Die erste ist kein Keyword. Sie ist ein Prompt, vollständig in ein Suchfeld oder ein KI-Tool eingefügt, der zwei benannte Produkte vergleicht, mit einer spezifischen Aufforderung nach Vor- und Nachteilen. Wir ranken dafür, weil einer unserer Artikel genau diese Frage in genau dieser Form beantwortet. Der Rest sind benannte Entitäten, die so spezifisch sind, dass das Feld konkurrierender Seiten nahezu leer ist: ein einzelner Bot, die Preisgestaltung eines einzelnen Endpunkts, eine einzelne Probe.
Dies ist die praktische Definition von Nicht-Massenware-Inhalten. Sie beantworten eine Frage, die für alle anderen zu neu, zu spezifisch oder zu datenabhängig ist, um sie bislang gut beantwortet zu haben. Alles Folgende beschreibt, wie die 10 Artikel gezielt dorthin gelangen.
Das Playbook: Sieben Dinge, die die besten 10 gemeinsam haben
Besetzen Sie das Neuheitsfenster
Seien Sie die erste kompetente Seite zu etwas, das in diesem Quartal veröffentlicht wurde.
Sechs der 10 Artikel behandeln Dinge, die ein Quartal zuvor kaum existierten: den Cloudflare-/crawl-Endpunkt, Shopifys Agentic Plan, Storebot-Google-Checkouts und den Protokoll-Stack aus ACP, AP2 und MCP. Die erste spezifische Antwort in diese Lücke wird zum Standardzitat.
Schreiben Sie die Erklärung am Tag, an dem ein Feature veröffentlicht wird, nicht ein Quartal später.
Veröffentlichen Sie Zahlen, die nur Sie haben
Eigene Daten sind das mit Abstand stärkste Signal im Set.
- 288.566 analysierte Server-Logs: ChatGPT-User-Traffic verfünffachte sich in sieben Wochen, GPTBot feuerte 152 Anfragen in einem 3-minütigen Schub ab.
- 89x Traffic-Multiplikator durch vollständiges Rendering, gemessen über fünf Shopify-Stores.
- 1.543 Checkout-Bot-Anfragen über 55 Tage protokolliert, darunter 64 Login-Proben.
- 517 gescannte Shopify-Stores (3,1 % nutzten Bazaarvoice), plus 616 ausgewertete Kundenfragen.
Veröffentlichen Sie eine Zahl, die sonst nirgends existiert, und Sie werden zur einzigen zitierbaren Quelle. Deshalb steht "cloudflare crawl cost" auf Position 4.
Sie brauchen kein Datenteam. Ein Log-Export, ein durchgeführter Test oder ein Scan Ihrer eigenen Kategorie reicht.
Eine Frage pro Überschrift, oben beantwortet
Machen Sie jede Überschrift zu einer echten Frage und beantworten Sie sie in den ersten beiden Sätzen.
Der Checkout-Artikel fragt "Wie schnell erfasst GPTBot einen Produktkatalog?" und beantwortet es dann, bevor Nuancen folgen. So entstehen in sich geschlossene Passagen, die ein Retrieval-System als Ganzes übernehmen und in eine Antwort einfügen kann.
Nennen Sie zuerst die Antwort, dann erklären Sie, dann schränken Sie ein.
Benennen Sie alles mit Präzision
Benennen Sie den genauen Bot, die API und das Protokoll statt der generischen Kategorie.
Nicht "KI-Crawler", sondern Storebot-Google, GPTBot, OAI-SearchBot, ClaudeBot, PerplexityBot, Meta-WebIndexer und LinkupBot. Nicht "Standards des agentischen Handels", sondern der /crawl-Endpunkt, die Catalog API, ACP, AP2, MCP und das Universal Commerce Protocol. Präzise Namen verkleinern das Feld konkurrierender Seiten: "linkupbot" und "meta-webindexer" ranken nur auf Position 8, weil genau diese Zeichenketten, definiert, im Text vorkommen.
Benennen Sie die spezifische Sache, dann definieren Sie sie in einfacher Sprache.
Jeder Satz trägt eine Aussage
Streichen Sie Füllwörter, damit die Seite dicht mit zitierfähigen Fakten ist.
Phrasen wie "in der heutigen schnelllebigen digitalen Welt" geben einem Modell nichts zum Extrahieren. Führen Sie mit Fakten, Zahlen, Daten und Mechanismen, damit der Großteil der Seite als zitierfähiges Material liest.
Wenn ein Satz keinen Fakt, keine Zahl und keinen Schritt hinzufügt, löschen Sie ihn.
Lassen Sie die Struktur das Schema erzeugen
Schreiben in Frage und Antwort lässt FAQ- und Dataset-Schema von selbst entstehen.
Weil die Überschriften bereits Fragen mit direkten Antworten sind, gibt das Layout automatisch Article-, FAQPage- und Dataset-Strukturdaten aus. Der Checkout-Artikel liefert aus denselben 1.543 protokollierten Anfragen ein vollständiges Dataset-Schema.
Strukturieren Sie einmal, bedienen Sie den menschlichen und den maschinellen Leser zugleich.
Tiefe verketten, nicht isolieren
Verbinden Sie ein Framework mit vielen Belegstücken statt einer ausufernden Seite.
Das Six-Gates-Framework benennt die Strategie; die Bot-Studien, die Checkout-Analyse und die Cloudflare-Tests belegen jedes Tor. Sie verlinken untereinander und geben Lesern und Crawlern eine kohärente thematische Landkarte.
Bauen Sie ein verknüpftes Set spezifischer Antworten, von denen jede in das Framework verlinkt.
Die Seitentypen, die zitiert werden
Die sieben Prinzipien erzeugen eine kleine Menge wiederholbarer Formate. Jedes ist ein Thema, das Sie gezielt aufbauen können, und jedes wird für eine andere Art von Frage zitiert. Die folgenden Beispiele stammen von WISLR und unserer Schwesterseite redirects.net, die dasselbe Playbook auf ein anderes Thema anwendet.

Die Datenstudie
Sie analysieren etwas, das nur Sie beobachten können, und veröffentlichen die Zahlen. Die KI-Bot-Log-Analyse stützt sich auf 288.566 Server-Logdateien; die Checkout-Studie protokolliert 1.543 Bot-Anfragen. Ein LLM, das "wie verhalten sich KI-Bots auf E-Commerce-Seiten" beantwortet, muss nach der Seite greifen, die die Daten hat. Bauen Sie sie, wenn Sie eine Zahl erzeugen können, die sonst nirgends existiert. Beispiel: AI Bot Behavior Log Analysis →
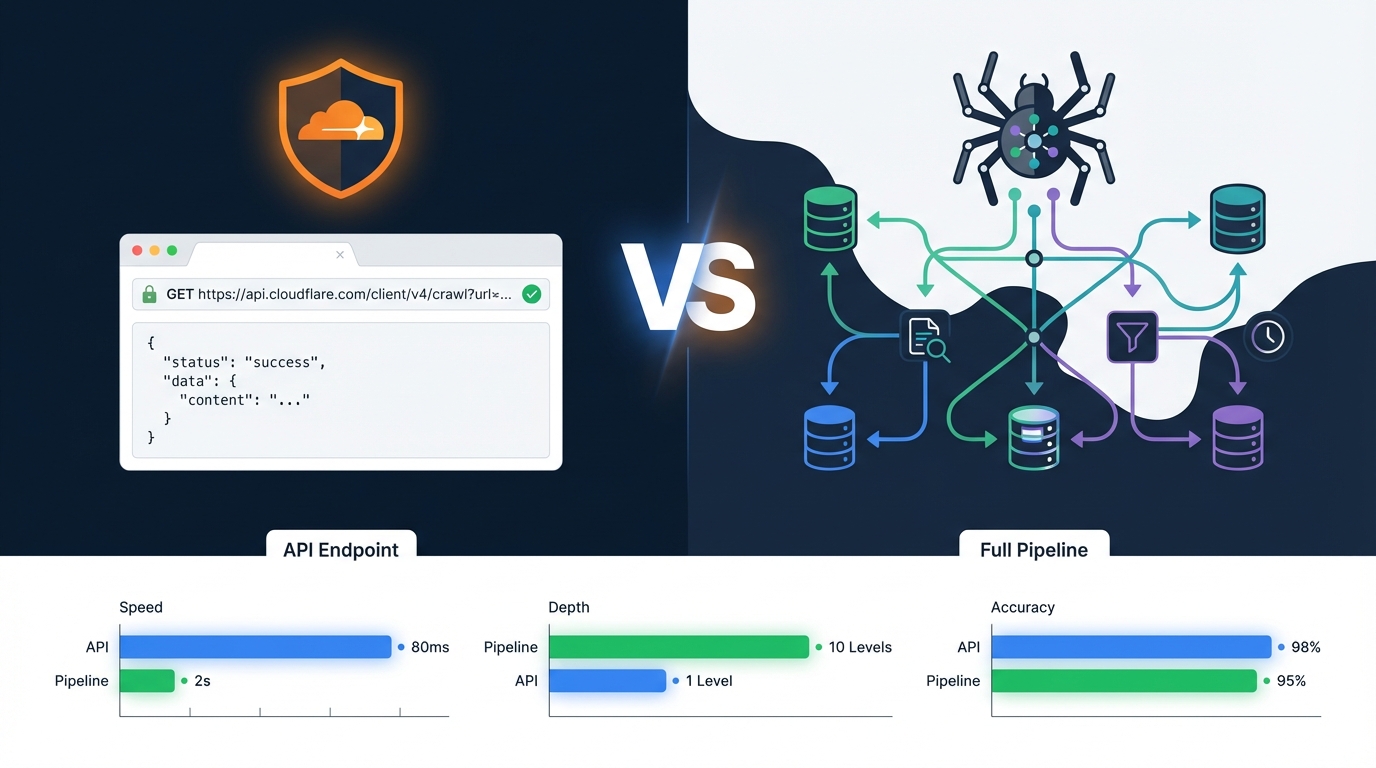
Der kontrollierte Test oder Benchmark
Sie führen dasselbe Verfahren über mehrere Fälle durch und berichten, was geschah. Der Cloudflare-/crawl-Artikel testete den Endpunkt über fünf Shopify-Stores und fand einen 89x-Rendering-Traffic-Multiplikator und Kosten pro Seite. Dies ist das Format, das für "wie viel kostet X" und "lohnt sich X" zitiert wird. Bauen Sie es, wenn ein Tool oder Feature neu genug ist, dass es noch niemand gemessen hat. Beispiel: Pros and Cons of the Cloudflare /crawl Endpoint →

Der Vergleich oder Kaufratgeber
Sie stellen benannte Optionen anhand expliziter Kriterien nebeneinander. Der AEO-Tools-Vergleich von redirects.net bewertet AirOps, Profound, Peec AI und Scrunch nach Preis, Abdeckung und Anwendungsfall, und sein stärkster Zug ist, die Prämisse infrage zu stellen, dass die vier überhaupt dieselbe Art von Produkt sind. WISLRs AEO-Readiness-Vergleich macht dasselbe für Ratgeber. Dieses Format gewinnt die "X vs. Y"- und "bestes Tool für Z"-Prompts, zu den absichtsstärksten Fragen, die einem LLM gestellt werden. Bauen Sie es, wenn Käufer aktiv zwischen benannten Alternativen wählen. Beispiel: AEO Tools Compared →

Der Erklärer zu neuen Features
Sie schreiben den definitiven Erklärer an dem Tag, an dem eine Plattform etwas veröffentlicht, und besetzen das Neuheitsfenster, bevor sich das Feld füllt. Die Artikel zum Shopify Agentic Plan und zum Same-Domain-Checkout beantworten "wie funktioniert das eigentlich", während diese Frage im Web noch keine gute Antwort hat. Bauen Sie es in dem Moment, in dem eine Plattform, die Sie behandeln, eine API, einen Bot oder eine Richtlinienänderung veröffentlicht. Beispiel: The Shopify Agentic Plan →
Die Dokumentationskorrektur
Sie testen die offizielle Dokumentation und veröffentlichen, wo sie falsch ist. Der Redirect-Ratgeber von redirects.net fand durch Tests heraus, dass nur 4 der von Shopify gelisteten reservierten URL-Präfixe tatsächlich Redirects blockieren, und deckte ein undokumentiertes Limit von 1.024 Zeichen auf. Ein Modell, das die offizielle Quelle gegen eine getestete Korrektur abwägt, neigt dazu, beide anzuzeigen, was Sie in die Antwort bringt. Bauen Sie es, wenn Sie praktische Belege haben, dass die kanonische Quelle unvollständig oder falsch ist. Beispiel: Creating Shopify URL Redirects →

Das Profil einer benannten Entität
Sie definieren eine spezifische Entität vollständig: was sie ist, was sie tut, wie man sie identifiziert. Die Bot-Studie profiliert GPTBot, Storebot-Google, ClaudeBot, Meta-WebIndexer und andere einzeln. Diese Seiten besitzen die "was ist X"- und "was macht X"-Prompts, weil die Entität präzise benannt ist und das Feld konkurrierender Seiten nahezu leer ist. Bauen Sie es für jeden Bot, jede API, jedes Protokoll oder Produkt, das spezifisch genug ist, dass es kaum jemand sonst dokumentiert hat. Beispiel: Storebot-Google Checkout Verification →

Das Framework oder das verkettete Playbook
Sie benennen die Arbeit und bringen sie in eine Reihenfolge. Die Six Gates of AI Channel Growth geben einer Strategie eine Struktur, nach der ein Leser handeln kann. Frameworks werden zitiert, wenn jemand fragt "wie sollte ich X angehen", weil ein benanntes, verkettetes Modell zitierfähiger ist als verstreute Tipps. Bauen Sie es, wenn Sie die Arbeit oft genug gemacht haben, um das Muster zu erkennen, das andere nicht sehen. Beispiel: The Six Gates of AI Channel Growth →

Die Enthüllung eines blinden Flecks
Sie zeigen, was die Standardwerkzeuge übersehen, und dann, wie man es misst. Die LLM-Traffic-Artikel zeigen, wie GA4 KI-gestützte Conversions verliert und was man stattdessen verfolgen sollte. Dieses Format wird für "warum zeigt meine Analytics X nicht" und "wie messe ich X" zitiert. Bauen Sie es, wenn das naheliegende Werkzeug bei etwas Wichtigem still versagt. Beispiel: LLM Traffic Is a Blind Spot in Your Analytics →
Die konträre These mit Daten
Sie stellen eine Behauptung auf, die der Annahme widerspricht, und untermauern sie dann mit eigenen Belegen. "Ihr KI-Kanal ist eine Recherche-Engine, kein Verkaufskanal" verändert, wie Marken ihren KI-Traffic deuten, gestützt auf Daten zur Verhaltensreise. Bauen Sie es, wenn Ihre Daten dem widersprechen, was alle für wahr halten. Beispiel: Your AI Channel Is a Research Engine →

Die Konzept-Einführung
Sie besitzen einen Begriff, indem Sie ihn sauber und vollständig definieren. Die kürzeren Grundlagenstücke beanspruchen ein Konzept, sodass die Definition, die KI wiederholt, Ihre ist. Bauen Sie es für einen aufkommenden Begriff, der noch keine einzelne kanonische Erklärung hat. Beispiel: Understanding AI Visibility →
Eine wiederholbare Checkliste
Bevor Sie veröffentlichen, prüfen Sie den Beitrag gegen die Dinge, die die besten 10 gemeinsam haben:
- Neuheit oder Spezifität. Ist dies zu neu, zu spezifisch oder zu datengestützt, als dass das Feld überfüllt wäre? Wenn eine Suche bereits zehn starke Seiten zeigt, ändern Sie den Blickwinkel.
- Eigene Belege. Enthält der Artikel mindestens eine Zahl, ein Testergebnis oder eine Beobachtung, die sonst nirgends existiert?
- Frage-Überschriften. Ist jede Abschnittsüberschrift eine echte Frage, vollständig in ihren ersten beiden Sätzen beantwortet?
- Benannte Entitäten. Sind die spezifischen Produkte, Bots, APIs und Protokolle exakt benannt und nicht generisch beschrieben?
- Aussagendichte. Ist die Seite überwiegend Substanz, in der Fakten, Zahlen, Daten und Schritte die Arbeit leisten? Streichen Sie die Sätze, die keine hinzufügen.
- Schema aus Struktur. Folgen das FAQ- und ein etwaiges Dataset-Schema natürlich aus der Art, wie der Beitrag geschrieben ist?
- Verknüpft, nicht isoliert. Verlinkt er in ein Framework und zitiert er stützende Belege, sodass er innerhalb einer thematischen Landkarte sitzt?
Inhalte, die alle sieben bestehen, lassen sich schwer zur Massenware machen, weil das, was sie zitierfähig macht, genau das ist, was Wettbewerber nicht kopieren können: Ihre Daten, Ihre Spezifität und Ihr Timing.
Häufig gestellte Fragen
Was macht Inhalte aus, die in KI-Engines ranken statt nur in der klassischen Suche?
Spezifität und primäre Belege. KI-Engines zitieren die Quelle, die eine Frage am direktesten und vollständigsten beantwortet, und sie belohnen benannte Entitäten, exakte Zahlen und in sich geschlossene Passagen. In WISLRs eigenen Daten erzielten die 10 Artikel, die auf eigener Forschung und präzise benannten Entitäten aufbauen, in den letzten 30 Tagen über 4.000 LLM-Zitate und liegen bei durchschnittlichen Suchpositionen von 4 bis 8. Breite Massenware-Ratgeber auf derselben Domain konkurrieren in einem gesättigten Feld, in dem nichts eine Seite hervorhebt. Der Unterschied liegt in der Themenauswahl und den Originaldaten, nicht in der Domain-Stärke.
Warum scheitern Massenware-Inhalte selbst auf einer autoritativen Domain?
Weil bereits Tausende Seiten dieselbe Frage beantworten und ein Modell keinen Grund hat, Ihre zu bevorzugen. WISLRs Massenware-Ratgeber zielen auf Suchanfragen wie “shopify redirects” und “301 redirect shopify”, die jeweils Hunderte monatliche Impressionen zu Fragen erzielen, die bereits Tausende anderer Seiten beantworten. Die Seiten sind kompetent und die Domain genießt Vertrauen, doch nichts hebt sie hervor. Massenware-Themen sind ein gesättigter Markt, in dem der einzig verbleibende Hebel rohe Autorität ist.
Wie wichtig ist eigene Erstforschung für die KI-Sichtbarkeit?
Sie ist das mit Abstand stärkste Signal in unseren Daten. WISLRs leistungsstärkste Artikel bauen auf Daten auf, die nur WISLR hat: 288.566 analysierte Server-Logdateien, ein kontrollierter Test des Cloudflare-Crawl-Endpunkts in fünf Stores, 1.543 protokollierte Checkout-Bot-Anfragen, ein Scan von 517 Shopify-Stores und 616 erfasste Kundenfragen. KI-Engines zitieren bevorzugt Primärquellen, weil Primärquellen der Ursprung neuer Fakten sind.
Wie sollte ich einen Artikel strukturieren, damit eine KI-Engine ihn zitieren kann?
Schreiben Sie eine Frage pro Überschrift und beantworten Sie sie vollständig in den ersten beiden Sätzen unter dieser Überschrift, bevor Sie Nuancen hinzufügen. So entstehen in sich geschlossene Passagen, die ein Modell übernehmen kann, ohne den umgebenden Kontext zu benötigen. Ergänzen Sie den Text durch FAQ-Schema und, wo zugrundeliegende Daten vorliegen, Dataset-Schema.
Was sind Nicht-Massenware-Inhalte und wie finde ich Themen dafür?
Nicht-Massenware-Inhalte beantworten eine Frage, die für alle anderen zu neu, zu spezifisch oder zu datenabhängig ist, um sie bislang gut beantwortet zu haben. Finden Sie sie, indem Sie auf neu veröffentlichte Produkte, APIs, Bots und Protokolle achten, indem Sie eine Ebene spezifischer werden als das naheliegende Keyword und indem Sie Tests durchführen oder Logs auswerten, die Zahlen erzeugen, die nur Sie haben. WISLR rankt auf Position 1.99 für “shopify ventures readiness probe”, gerade weil kaum jemand sonst dazu veröffentlicht hat.
Wie lang sollten Inhalte für KI sein?
So lang, wie es nötig ist, um die Frage vollständig zu beantworten, und keinen Satz länger. WISLRs Artikel reichen von etwa 1.000 Wörtern für eine einzelne präzise Definition bis über 10.000 Wörter für die ausführlichsten Ratgeber. Die Länge ist ein Ergebnis der Vollständigkeit, kein Ziel.
Kann ich KI nutzen, um Inhalte zu schreiben, die andere KI-Engines zitieren?
Sie können KI zum Entwerfen und Strukturieren nutzen, aber die zitierfähige Substanz muss von Ihnen kommen. Ein Modell kann Ihre Server-Logs, Ihren Store-Scan oder Ihren kontrollierten Test nicht erfinden. Der dauerhafte Vorteil sind die eigenen Daten und die spezifischen, überprüfbaren Aussagen, die Sie auf die Seite bringen. Nutzen Sie KI, um dieses Material in abrufbare Passagen zu ordnen und zu schärfen, nicht um generische Erklärungen zu erzeugen, die bereits an tausend anderen Stellen existieren.