

La mayoría de los consejos sobre “contenido para IA” son en sí mismos genéricos
La instrucción de “crear contenido excelente para la IA” está por todas partes, y casi todos dicen lo mismo: escribe páginas útiles y bien estructuradas y añade esquema. Ese consejo es cierto, genérico e inútil, porque describe lo que todos ya están haciendo.
Queríamos una respuesta más difícil, así que examinamos nuestro propio trabajo. Extrajimos los 10 mejores artículos que publica WISLR y los datos que los respaldan. El patrón fue lo bastante nítido para zanjar la cuestión. En los últimos 30 días, esos 10 artículos fueron citados más de 4.000 veces en los principales LLM, y en la búsqueda clásica ocupan posiciones medias de 4 a 8. Nuestras guías genéricas y amplias, en el mismo dominio y con la misma autoridad detrás, no se acercan, porque los temas están saturados y nada distingue a nuestra página.
Este artículo es el análisis: lo que muestran los datos, lo que comparten los 10 artículos y cómo ejecutar el mismo manual en tu propio contenido.
Los datos: mismo dominio, resultados opuestos
La forma más clara de ver qué recompensa la IA es comparar dos tipos de contenido en un mismo sitio, porque la autoridad del dominio se mantiene constante. La posición en la búsqueda ya no es el marcador. Lo que cuenta es si un LLM recurre a la página cuando construye una respuesta. En los últimos 30 días, los 10 artículos siguientes fueron citados más de 4.000 veces en los principales motores de IA.
Últimos 30 días · conjunto de artículos de wislr.com
Estos son los artículos no genéricos que impulsan esas citas. Cada uno apunta a algo nuevo, específico o respaldado por datos que generamos nosotros mismos, y cada uno también mantiene una posición sólida en la búsqueda clásica (de septiembre de 2025 a junio de 2026):
| Artículo | Posición media | Impresiones |
|---|---|---|
| OpenAI KPIs and Success Metrics | 4.53 | 114 |
| The Shopify Agentic Plan | 6.38 | 269 |
| Shopify Same-Domain Checkout Analytics | 6.48 | 1,436 |
| Pros and Cons of the Cloudflare /crawl Endpoint | 6.63 | 3,417 |
| Best Cloudflare /crawl Settings | 6.67 | 2,369 |
| AI Bot Behavior Log Analysis | 7.07 | 1,232 |
| AEO Readiness Comparison | 7.61 | 741 |
| Storebot-Google Checkout Verification | 7.82 | 317 |
| Shopify CDN Request Logging | 8.55 | 2,081 |
A modo de contraste, el mismo dominio también publica guías genéricas competentes que apuntan a consultas como “shopify redirects”, “301 redirect shopify” y “shopify url redirects”. Esas páginas reúnen cientos de impresiones cada una, así que Google entiende claramente de qué tratan. Aun así no logran abrirse paso, porque miles de páginas ya responden la misma pregunta y nada en la nuestra le da a un modelo una razón para preferirla. La página pilar sobre redirecciones por sí sola reúne 14.916 impresiones en una consulta totalmente saturada.
Mismo dominio. Los artículos que se citan son los que nadie más podría haber escrito.
El patrón en una línea
En un dominio fijo, la selección del tema y los datos originales son lo que te hace ser citado. Esas decisiones son la razón por la que este conjunto de artículos obtuvo más de 4.000 citas de LLM en 30 días. La autoridad no es la palanca que la mayoría de las marcas creen que es.
Qué examinamos
Los 10 artículos abarcan de febrero a mayo de 2026 y cubren el comportamiento de los bots de IA, el endpoint de crawl de Cloudflare, la verificación de checkout de Shopify, la medición del tráfico de LLM, el comercio agéntico y un marco de crecimiento de seis puertas. Para cada uno registramos su tesis, los datos originales que lo respaldan, su estructura y su rendimiento en Search Console. Luego cruzamos los datos a nivel de consulta para ver no solo qué páginas se posicionaban, sino para qué exactamente.
Los datos de consultas contienen la mayor parte de la evidencia, así que léelos directamente.
La pista: nos arrastran hacia preguntas que nadie optimizó
El SEO clásico apunta a palabras clave. Ahora el contenido es arrastrado hacia respuestas para preguntas completas, desordenadas y específicas, y ahí es de donde vienen las citas. El informe de consultas de WISLR muestra la forma de esos prompts. Aquí hay consultas reales para las que el dominio aparece en la primera página, las mismas preguntas hacia las que los LLM recurren a nuestros artículos para responder:
| Consulta | Posición media |
|---|---|
| “which is better for measuring referral traffic coming from llms, profound or growthx? provide a definitive answer, along with a list of pros and cons specific to measuring referral traffic from llms for each.” | 4.78 |
| “shopify ventures readiness probe” | 1.99 |
| “cloudflare /crawl endpoint pricing” | 4.95 |
| “cloudflare crawl cost” | 4.0 |
| “openai kpi” | 5.67 |
| “linkupbot” | 7.85 |
| “meta-webindexer” | 8.0 |
La primera no es una palabra clave. Es un prompt, pegado entero en un cuadro de búsqueda o una herramienta de IA, que compara dos productos nombrados con una petición específica de pros y contras. Nos posicionamos para ella porque uno de nuestros artículos responde esa pregunta exacta en esa forma exacta. Las demás son entidades nombradas tan específicas que el campo de páginas competidoras está casi vacío: un solo bot, los precios de un solo endpoint, una sola probe.
Esta es la definición operativa del contenido no genérico. Responde a una pregunta que es demasiado nueva, demasiado específica o demasiado dependiente de datos como para que alguien más la haya respondido bien todavía. Todo lo que sigue es cómo los 10 artículos llegan ahí a propósito.
El manual: siete cosas que los 10 mejores tienen en común
Reclama la ventana de novedad
Sé la primera página competente sobre algo que se lanzó este trimestre.
Seis de los 10 artículos cubren cosas que apenas existían un trimestre antes: el endpoint de crawl /crawl de Cloudflare, el Agentic Plan de Shopify, los checkouts de Storebot-Google y la pila de protocolos ACP, AP2 y MCP. La primera respuesta específica en ese hueco se convierte en la cita por defecto.
Escribe la explicación el día en que se lanza una función, no el trimestre siguiente.
Publica cifras que solo tú tienes
Los datos de origen propio son la señal más fuerte por sí sola del conjunto.
- 288,566 registros de servidor analizados: el tráfico de ChatGPT-User se multiplicó por 5 en siete semanas, GPTBot disparó 152 solicitudes en una ráfaga de 3 minutos.
- 89x multiplicador de tráfico por el renderizado completo, medido en cinco tiendas Shopify.
- 1,543 solicitudes de bots de checkout registradas durante 55 días, incluidas 64 sondas de inicio de sesión.
- 517 tiendas Shopify escaneadas (el 3,1% usaba Bazaarvoice), más 616 preguntas de clientes extraídas.
Publica una cifra que no exista en ningún otro sitio y te conviertes en la única fuente que citar. Por eso "cloudflare crawl cost" se sitúa en la posición 4.
No necesitas un equipo de datos. Una exportación de registros, una prueba que realizaste o un escaneo de tu propia categoría es suficiente.
Una pregunta por encabezado, respondida arriba
Haz que cada encabezado sea una pregunta real y respóndela en las dos primeras frases.
El artículo de checkout pregunta "¿Con qué rapidez mapea GPTBot un catálogo de productos?" y luego lo responde antes de añadir matices. Eso produce pasajes autocontenidos que un sistema de recuperación puede extraer enteros e insertar en una respuesta.
Expón la respuesta primero, luego explica, luego matiza.
Nombra todo con precisión
Nombra el bot, la API y el protocolo exactos en lugar de la categoría genérica.
No "AI crawlers", sino Storebot-Google, GPTBot, OAI-SearchBot, ClaudeBot, PerplexityBot, Meta-WebIndexer y LinkupBot. No "estándares de comercio agéntico", sino el endpoint /crawl, Catalog API, ACP, AP2, MCP y Universal Commerce Protocol. Los nombres precisos reducen el campo de páginas competidoras: "linkupbot" y "meta-webindexer" se posicionan en la posición 8 solo porque esas cadenas exactas aparecen, definidas, en el texto.
Nombra la cosa específica y luego defínela en lenguaje sencillo.
Cada frase lleva una afirmación
Elimina el relleno para que la página esté densa de hechos citables.
Frases como "en el vertiginoso panorama digital de hoy" no le dan a un modelo nada que extraer. Lidera con hechos, cifras, fechas y mecanismos para que la mayor parte de la página se lea como material citable.
Si una frase no añade un hecho, una cifra o un paso, elimínala.
Deja que la estructura genere el esquema
La escritura de pregunta y respuesta hace que el esquema de FAQ y Dataset salga gratis.
Como los encabezados ya son preguntas con respuestas directas, el diseño emite automáticamente datos estructurados de Article, FAQPage y Dataset. El artículo de checkout incluye un esquema de Dataset completo a partir de las mismas 1.543 solicitudes registradas.
Estructura una vez, sirve al lector humano y al lector máquina juntos.
Secuencia la profundidad, no la aísles
Conecta un marco a muchas piezas de evidencia en lugar de una página enorme.
El marco de las Seis Puertas nombra la estrategia; los estudios de bots, el análisis de checkout y las pruebas de Cloudflare prueban cada puerta. Se enlazan entre sí, dando a lectores y rastreadores un mapa temático coherente.
Construye un conjunto conectado de respuestas específicas, cada una enlazando con el marco.
Los tipos de página que se citan
Los siete principios producen un pequeño conjunto de formatos repetibles. Cada uno es un tema que puedes construir a propósito, y cada uno se cita para un tipo de pregunta distinto. Los ejemplos siguientes provienen de WISLR y de nuestro sitio hermano redirects.net, que ejecuta el mismo manual sobre un tema diferente.

El estudio de datos
Analizas algo que solo tú puedes observar y publicas las cifras. El análisis de registros de bots de IA se apoya en 288.566 archivos de registro de servidor; el estudio de checkout registra 1.543 solicitudes de bots. Un LLM que responde "cómo se comportan los bots de IA en sitios de ecommerce" tiene que recurrir a la página que tiene los datos. Construyelo cuando puedas generar una cifra que no exista en ningún otro sitio. Ejemplo: AI Bot Behavior Log Analysis →
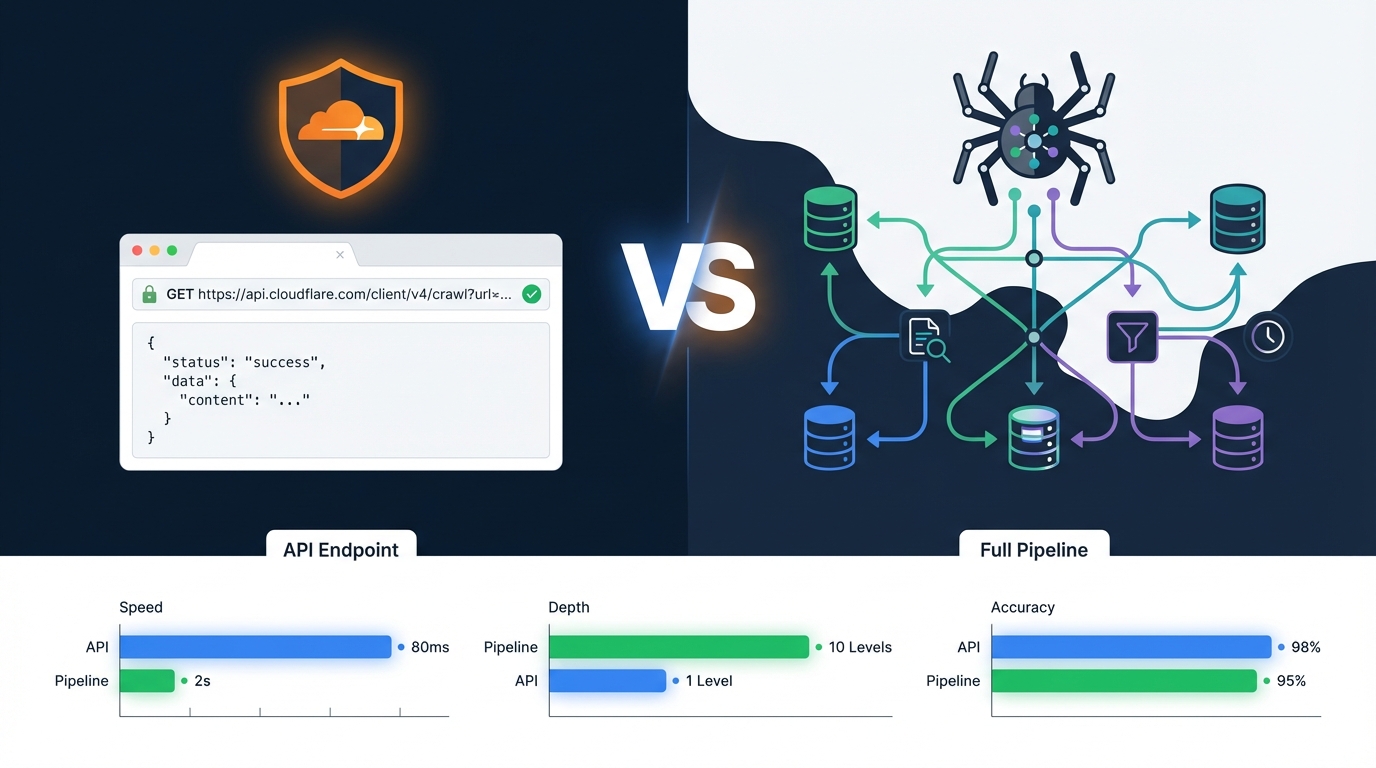
La prueba controlada o benchmark
Ejecutas el mismo procedimiento en varios casos e informas de lo que sucedió. El artículo del /crawl de Cloudflare probó el endpoint en cinco tiendas Shopify y encontró un multiplicador de tráfico de renderizado de 89x y un coste por página. Este es el formato que se cita para "cuánto cuesta X" y "vale la pena X". Construyelo cuando una herramienta o función sea lo bastante nueva como para que nadie la haya medido todavía. Ejemplo: Pros and Cons of the Cloudflare /crawl Endpoint →

La comparación o guía de compra
Pones opciones nombradas lado a lado con criterios explícitos. La comparación de herramientas AEO de redirects.net clasifica a AirOps, Profound, Peec AI y Scrunch por precio, cobertura y caso de uso, y su movimiento más fuerte es cuestionar la premisa de que las cuatro sean siquiera el mismo tipo de producto. La comparación de preparación AEO de WISLR hace lo mismo para las guías. Este formato gana los prompts "X vs Y" y "mejor herramienta para Z", entre las preguntas de mayor intención que se le hacen a un LLM. Construyelo cuando los compradores estén eligiendo activamente entre alternativas nombradas. Ejemplo: AEO Tools Compared →

La explicación de una función nueva
Escribes la explicación definitiva el día en que una plataforma lanza algo, reclamando la ventana de novedad antes de que se llene el campo. Los artículos del Shopify Agentic Plan y del checkout de mismo dominio responden "cómo funciona esto realmente" mientras esa pregunta todavía no tiene una buena respuesta en la web. Construyelo en el momento en que una plataforma que cubres lance una API, un bot o un cambio de política. Ejemplo: The Shopify Agentic Plan →
La corrección de la documentación
Pruebas la documentación oficial y publicas dónde se equivoca. La guía de redirecciones de redirects.net descubrió mediante pruebas que solo 4 de los prefijos de URL reservados que enumera Shopify realmente bloquean las redirecciones, y sacó a la luz un límite no documentado de 1.024 caracteres. Un modelo que sopesa la fuente oficial frente a una corrección probada tiende a mostrar ambas, lo que te pone en la respuesta. Construyelo cuando tengas evidencia práctica de que la fuente canónica es incompleta o errónea. Ejemplo: Creating Shopify URL Redirects →

El perfil de entidad nombrada
Defines una entidad específica por completo: qué es, qué hace, cómo identificarla. El estudio de bots perfila a GPTBot, Storebot-Google, ClaudeBot, Meta-WebIndexer y otros individualmente. Estas páginas dominan los prompts "qué es X" y "qué hace X" porque la entidad está nombrada con precisión y el campo de páginas competidoras está casi vacío. Construyelo para cualquier bot, API, protocolo o producto lo bastante específico como para que pocos otros lo hayan documentado. Ejemplo: Storebot-Google Checkout Verification →

El marco o manual secuenciado
Nombras el trabajo y lo pones en orden. Las Seis Puertas del crecimiento del canal de IA le dan a una estrategia una estructura sobre la que un lector puede actuar. Los marcos se citan cuando alguien pregunta "cómo debería abordar X", porque un modelo nombrado y secuenciado es más citable que consejos dispersos. Construyelo cuando hayas hecho el trabajo suficientes veces como para ver el patrón que otros no pueden. Ejemplo: The Six Gates of AI Channel Growth →

La exposicién del punto ciego
Muestras lo que las herramientas estándar pasan por alto y luego muestras cómo medirlo. Los artículos de tráfico de LLM demuestran cómo GA4 pierde conversiones asistidas por IA y qué hay que rastrear en su lugar. Este formato se cita para "por qué mi analítica no muestra X" y "cómo mido X". Construyelo cuando la herramienta obvia falla silenciosamente en algo importante. Ejemplo: LLM Traffic Is a Blind Spot in Your Analytics →
La tesis contraintuitiva con datos
Haces una afirmación que contradice la suposición y luego la respaldas con evidencia de origen propio. "Tu canal de IA es un motor de investigación, no un canal de ventas" replantea cómo las marcas interpretan su tráfico de IA, respaldado por datos de recorrido conductual. Construyelo cuando tus datos contradigan lo que todos suponen que es cierto. Ejemplo: Your AI Channel Is a Research Engine →

El manual introductorio del concepto
Te apropias de un término definiéndolo de forma limpia y completa. Las piezas fundacionales más cortas reclaman un concepto para que la definición que la IA repite sea la tuya. Construyelo para un término emergente que todavía no tiene una única explicación canónica. Ejemplo: Understanding AI Visibility →
Una lista de verificación repetible
Antes de publicar, contrasta la pieza con las cosas que los 10 mejores tienen en común:
- Novedad o especificidad. ¿Es esto demasiado nuevo, demasiado específico o demasiado respaldado por datos como para que el campo esté abarrotado? Si una búsqueda muestra diez páginas fuertes ya existentes, cambia el ángulo.
- Evidencia de origen propio. ¿Contiene el artículo al menos una cifra, un resultado de prueba o una observación que no exista en ningún otro sitio?
- Encabezados con preguntas. ¿Es cada encabezado de sección una pregunta real, respondida por completo en sus dos primeras frases?
- Entidades nombradas. ¿Están nombrados con exactitud los productos, bots, API y protocolos específicos, y no descritos de forma genérica?
- Densidad de afirmaciones. ¿Es la página mayormente sustancia, con hechos, cifras, fechas y pasos haciendo el trabajo? Recorta las frases que no añaden ninguno.
- Esquema a partir de la estructura. ¿Salen el esquema de FAQ y cualquier esquema de Dataset de forma natural a partir de la manera en que está escrita la pieza?
- Conectada, no aislada. ¿Enlaza con un marco y cita evidencia de apoyo, de modo que se sitúe dentro de un mapa temático?
El contenido que supera las siete es difícil de convertir en genérico, porque lo que lo hace citable es lo que los competidores no pueden copiar: tus datos, tu especificidad y tu momento.
Preguntas frecuentes
¿Qué hace que el contenido se posicione en los motores de IA en lugar de solo en la búsqueda clásica?
Especificidad y evidencia primaria. Los motores de IA citan la fuente que responde de forma más directa y completa a una pregunta, y recompensan las entidades nombradas, las cifras exactas y los pasajes autocontenidos. En los propios datos de WISLR, los 10 artículos basados en investigación de origen propio y entidades nombradas precisas obtuvieron más de 4.000 citas de LLM en los últimos 30 días y se sitúan en posiciones medias de búsqueda de 4 a 8. Las guías genéricas y amplias del mismo dominio compiten en un campo saturado donde nada distingue a una página. La diferencia es la selección del tema y los datos originales, no el poder del dominio.
¿Por qué el contenido genérico falla incluso en un dominio con autoridad?
Porque miles de páginas ya responden la misma pregunta, y un modelo no tiene razón para preferir la tuya. Las guías genéricas de WISLR apuntan a consultas como “shopify redirects” y “301 redirect shopify”, cada una obteniendo cientos de impresiones mensuales en preguntas que miles de otras páginas ya responden. Las páginas son competentes y el dominio es de confianza, pero nada las distingue. Los temas genéricos son un mercado saturado donde la única palanca que queda es la autoridad bruta.
¿Qué importancia tiene la investigación original de origen propio para la visibilidad en la IA?
Es la señal más fuerte por sí sola en nuestros datos. Los artículos de mejor rendimiento de WISLR se basan en datos que solo WISLR tiene: 288.566 archivos de registro de servidor analizados, una prueba controlada en cinco tiendas del endpoint de crawl de Cloudflare, 1.543 solicitudes de bots de checkout registradas, un escaneo de 517 tiendas Shopify y 616 preguntas de clientes extraídas. Los motores de IA citan preferentemente las fuentes primarias porque las fuentes primarias son donde se originan los hechos novedosos.
¿Cómo debo estructurar un artículo para que un motor de IA pueda citarlo?
Escribe una pregunta por encabezado y respóndela por completo en las dos primeras frases debajo de ese encabezado, antes de añadir matices. Esto produce pasajes autocontenidos que un modelo puede extraer sin necesitar el contexto circundante. Combina el cuerpo con esquema de FAQ y, cuando hay datos subyacentes, esquema de Dataset.
¿Qué es el contenido no genérico y cómo encuentro temas para él?
El contenido no genérico responde a una pregunta que es demasiado nueva, demasiado específica o demasiado dependiente de datos como para que alguien más la haya respondido bien todavía. Encuéntralo vigilando productos, API, bots y protocolos recién lanzados, yendo un nivel más específico que la palabra clave obvia y realizando pruebas o extrayendo registros que generen cifras que solo tú tienes. WISLR se posiciona en la posición 1,99 para “shopify ventures readiness probe” precisamente porque casi nadie más ha publicado sobre ello.
¿Qué extensión debe tener el contenido para la IA?
Tan largo como sea necesario para responder por completo la pregunta y no más. Los artículos de WISLR van desde aproximadamente 1.000 palabras para una sola definición precisa hasta más de 10.000 palabras para las guías más detalladas. La extensión es un resultado de la exhaustividad, no un objetivo.
¿Puedo usar IA para escribir contenido que otros motores de IA citarán?
Puedes usar IA para redactar y estructurar, pero la sustancia citable tiene que venir de ti. Un modelo no puede inventar tus registros de servidor, tu escaneo de tiendas ni tu prueba controlada. La ventaja duradera son los datos de origen propio y las afirmaciones específicas y verificables que aportas a la página. Usa la IA para organizar y afinar ese material en pasajes recuperables, no para generar explicaciones genéricas que ya existen en otros mil lugares.