

Most “Content for AI” Advice Is Itself a Commodity
The instruction to “create great content for AI” is everywhere, and almost all of it says the same thing: write helpful, well-structured pages and add schema. That advice is true, generic, and useless, because it describes what everyone is already doing.
We wanted a harder answer, so we looked at our own work. We pulled the 10 best articles WISLR publishes and the data behind them. The pattern was sharp enough to settle the question. Over the last 30 days, those 10 articles were cited more than 4,000 times across the major LLMs, and in classic search they hold average positions of 4 to 8. Our broad commodity guides, on the same domain and with the same authority behind them, do not come close, because the topics are saturated and nothing sets our page apart.
This article is the teardown: what the data shows, what the 10 articles share, and how to run the same playbook on your own content.
The Data: Same Domain, Opposite Outcomes
The cleanest way to see what AI rewards is to compare two kinds of content on one site, because the domain authority is held constant. Search position is no longer the scoreboard. What counts is whether an LLM reaches for the page when it builds an answer. Over the last 30 days, the 10 articles below were cited more than 4,000 times across the major AI engines.
Last 30 days · wislr.com article set
These are the non-commodity articles driving those citations. Each one targets something new, specific, or backed by data we generated ourselves, and each also holds a strong classic-search position (September 2025 through June 2026):
| Article | Avg. position | Impressions |
|---|---|---|
| OpenAI KPIs and Success Metrics | 4.53 | 114 |
| The Shopify Agentic Plan | 6.38 | 269 |
| Shopify Same-Domain Checkout Analytics | 6.48 | 1,436 |
| Pros and Cons of the Cloudflare /crawl Endpoint | 6.63 | 3,417 |
| Best Cloudflare /crawl Settings | 6.67 | 2,369 |
| AI Bot Behavior Log Analysis | 7.07 | 1,232 |
| AEO Readiness Comparison | 7.61 | 741 |
| Storebot-Google Checkout Verification | 7.82 | 317 |
| Shopify CDN Request Logging | 8.55 | 2,081 |
For contrast, the same domain also publishes competent commodity guides targeting queries like “shopify redirects,” “301 redirect shopify,” and “shopify url redirects.” Those pages each collect hundreds of impressions, so Google plainly understands what they are about. They still do not break through, because thousands of pages already answer the same question and nothing about ours gives a model a reason to prefer it. The redirect pillar page alone gathers 14,916 impressions on a fully saturated query.
Same domain. The articles that get cited are the ones nobody else could have written.
The pattern in one line
On a fixed domain, topic selection and original data are what get you cited. Those choices are why this set of articles drew more than 4,000 LLM citations in 30 days. Authority is not the lever most brands think it is.
What We Looked At
The 10 articles span February through May 2026 and cover AI bot behavior, the Cloudflare crawl endpoint, Shopify checkout verification, LLM traffic measurement, agentic commerce, and a six-gate growth framework. For each one we recorded its thesis, the original data behind it, its structure, and its Search Console performance. We then cross-referenced the query-level data to see not just which pages ranked, but for exactly what.
The query data carries most of the evidence, so read it directly.
The Tell: We Get Pulled Into Questions Nobody Optimized For
Classic SEO targets keywords. Content now gets pulled into answers for full, messy, specific questions, and that is where the citations come from. WISLR’s query report shows the shape of those prompts. Here are real queries the domain surfaces on the first page for, the same questions LLMs reach into our articles to answer:
| Query | Avg. position |
|---|---|
| “which is better for measuring referral traffic coming from llms, profound or growthx? provide a definitive answer, along with a list of pros and cons specific to measuring referral traffic from llms for each.” | 4.78 |
| “shopify ventures readiness probe” | 1.99 |
| “cloudflare /crawl endpoint pricing” | 4.95 |
| “cloudflare crawl cost” | 4.0 |
| “openai kpi” | 5.67 |
| “linkupbot” | 7.85 |
| “meta-webindexer” | 8.0 |
The first one is not a keyword. It is a prompt, pasted whole into a search box or an AI tool, comparing two named products with a specific request for pros and cons. We rank for it because one of our articles answers that exact question in that exact shape. The rest are named entities so specific that the field of competing pages is nearly empty: a single bot, a single endpoint’s pricing, a single probe.
This is the operating definition of non-commodity content. It answers a question that is too new, too specific, or too data-dependent for anyone else to have answered well yet. Everything below is how the 10 articles get there on purpose.
The Playbook: Seven Things the Best 10 Have in Common
Claim the newness window
Be the first competent page on something that shipped this quarter.
Six of the 10 articles cover things that barely existed a quarter earlier: the Cloudflare /crawl endpoint, Shopify's Agentic Plan, Storebot-Google checkouts, and the ACP, AP2, and MCP protocol stack. The first specific answer into that gap becomes the default citation.
Write the explainer the day a feature ships, not the quarter after.
Publish numbers only you have
First-party data is the single strongest signal in the set.
- 288,566 server logs analyzed: ChatGPT-User traffic 5x'd in seven weeks, GPTBot fired 152 requests in a 3-minute burst.
- 89x traffic multiplier from full rendering, measured across five Shopify stores.
- 1,543 checkout-bot requests logged over 55 days, including 64 login probes.
- 517 Shopify stores scanned (3.1% ran Bazaarvoice), plus 616 customer questions mined.
Publish a number that exists nowhere else and you become the only source to cite. That is why "cloudflare crawl cost" sits at position 4.
You do not need a data team. A log export, a test you ran, or a scan of your own category is enough.
One question per heading, answered up top
Make every heading a real question and answer it in the first two sentences.
The checkout article asks "How fast does GPTBot map a product catalog?" then answers it before adding nuance. That produces self-contained passages a retrieval system can lift whole and drop into an answer.
State the answer first, then explain, then qualify.
Name everything with precision
Name the exact bot, API, and protocol instead of the generic category.
Not "AI crawlers" but Storebot-Google, GPTBot, OAI-SearchBot, ClaudeBot, PerplexityBot, Meta-WebIndexer, and LinkupBot. Not "agentic commerce standards" but the /crawl endpoint, Catalog API, ACP, AP2, MCP, and Universal Commerce Protocol. Precise names shrink the field of competing pages: "linkupbot" and "meta-webindexer" rank at position 8 only because those exact strings appear, defined, in the text.
Name the specific thing, then define it in plain language.
Every sentence carries a claim
Cut filler so the page is dense with quotable facts.
Phrases like "in today's fast-paced digital landscape" give a model nothing to extract. Lead with facts, numbers, dates, and mechanisms so most of the page reads as citable material.
If a sentence adds no fact, number, or step, delete it.
Let structure generate the schema
Question-and-answer writing makes FAQ and Dataset schema fall out for free.
Because the headings are already questions with direct answers, the layout emits Article, FAQPage, and Dataset structured data automatically. The checkout article ships a full Dataset schema from the same 1,543 logged requests.
Structure once, serve the human reader and the machine reader together.
Sequence depth, do not isolate
Connect one framework to many evidence pieces instead of one sprawling page.
The Six Gates framework names the strategy; the bot studies, checkout analysis, and Cloudflare tests prove each gate. They link to each other, giving readers and crawlers a coherent topical map.
Build a connected set of specific answers, each linking into the framework.
The Page Types That Get Cited
The seven principles produce a small set of repeatable formats. Each one is a theme you can build on purpose, and each gets cited for a different kind of question. The examples below are drawn from WISLR and our sister site redirects.net, which runs the same playbook on a different topic.

The data study
You analyze something only you can observe and publish the numbers. The AI bot log analysis sits on 288,566 server log files; the checkout study logs 1,543 bot requests. An LLM answering "how are AI bots behaving on ecommerce sites" has to reach for the page that has the data. Build it when you can generate a number that exists nowhere else. Example: AI Bot Behavior Log Analysis →
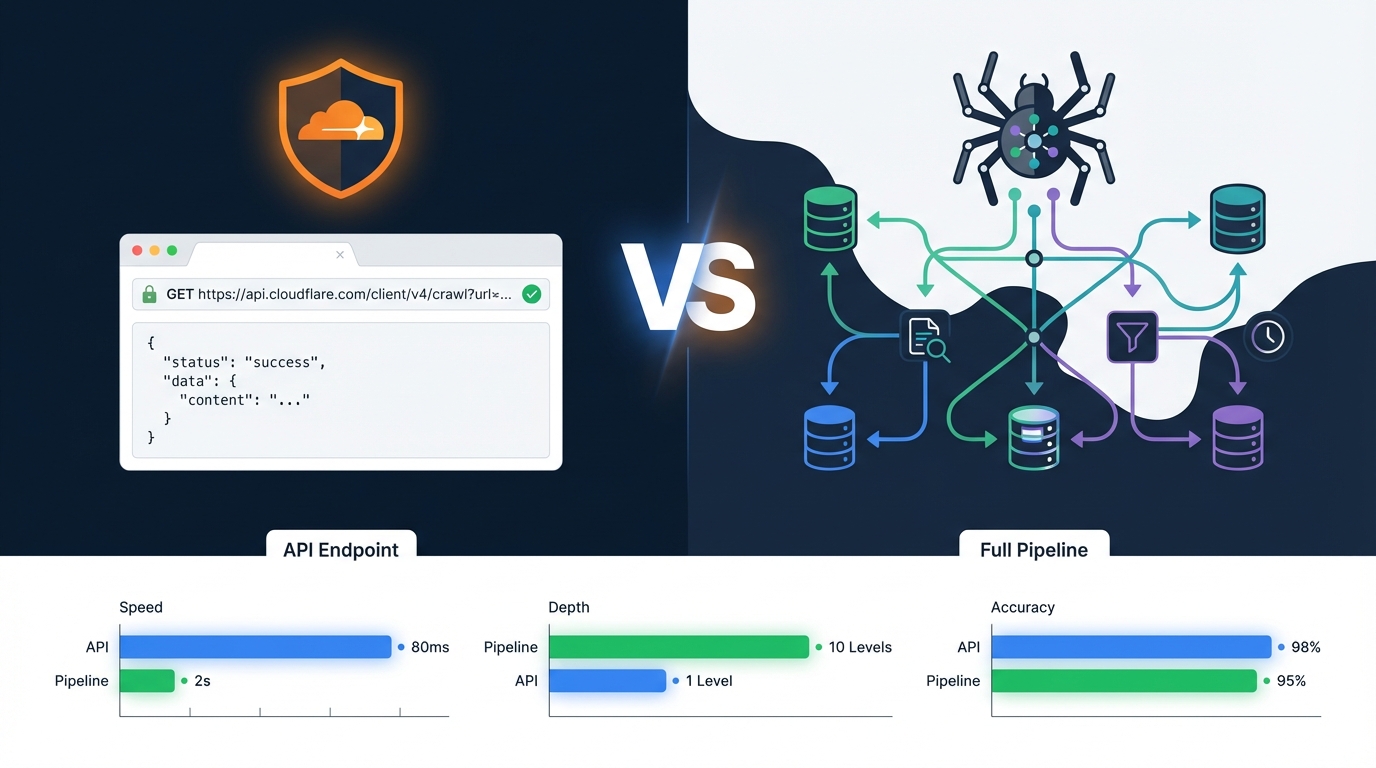
The controlled test or benchmark
You run the same procedure across several cases and report what happened. The Cloudflare /crawl article tested the endpoint across five Shopify stores and found an 89x rendering traffic multiplier and a per-page cost. This is the format that gets cited for "how much does X cost" and "is X worth it." Build it when a tool or feature is new enough that no one has measured it yet. Example: Pros and Cons of the Cloudflare /crawl Endpoint →

The comparison or buyer's guide
You put named options side by side on explicit criteria. The redirects.net AEO tools comparison ranks AirOps, Profound, Peec AI, and Scrunch on price, coverage, and use case, and its strongest move is challenging the premise that the four are even the same kind of product. WISLR's AEO readiness comparison does the same for guides. This format wins the "X vs Y" and "best tool for Z" prompts, among the highest-intent questions asked of an LLM. Build it when buyers are actively choosing between named alternatives. Example: AEO Tools Compared →

The new-feature explainer
You write the definitive explainer the day a platform ships something, claiming the newness window before the field fills. The Shopify Agentic Plan and same-domain checkout articles answer "how does this actually work" while that question still has no good answer on the web. Build it the moment a platform you cover ships an API, a bot, or a policy change. Example: The Shopify Agentic Plan →
The documentation correction
You test the official docs and publish where they are wrong. The redirects.net redirect guide found through testing that only 4 of Shopify's listed reserved URL prefixes actually block redirects, and surfaced an undocumented 1,024-character limit. A model weighing the official source against a tested correction tends to surface both, which puts you in the answer. Build it when you have hands-on evidence that the canonical source is incomplete or wrong. Example: Creating Shopify URL Redirects →

The named-entity profile
You define one specific entity completely: what it is, what it does, how to identify it. The bot study profiles GPTBot, Storebot-Google, ClaudeBot, Meta-WebIndexer, and others individually. These pages own the "what is X" and "what does X do" prompts because the entity is named precisely and the field of competing pages is nearly empty. Build it for any bot, API, protocol, or product specific enough that few others have documented it. Example: Storebot-Google Checkout Verification →

The framework or sequenced playbook
You name the work and put it in order. The Six Gates of AI Channel Growth gives a strategy a structure a reader can act on. Frameworks get cited when someone asks "how should I approach X," because a named, sequenced model is more quotable than scattered tips. Build it when you have done the work enough times to see the pattern others cannot. Example: The Six Gates of AI Channel Growth →

The blind-spot exposé
You show what the standard tools miss, then show how to measure it. The LLM traffic articles demonstrate how GA4 loses AI-assisted conversions and what to track instead. This format gets cited for "why doesn't my analytics show X" and "how do I measure X." Build it when the obvious tool quietly fails at something important. Example: LLM Traffic Is a Blind Spot in Your Analytics →
The contrarian thesis with data
You make a claim that cuts against the assumption, then back it with first-party evidence. "Your AI channel is a research engine, not a sales channel" reframes how brands read their AI traffic, supported by behavioral journey data. Build it when your data contradicts what everyone assumes is true. Example: Your AI Channel Is a Research Engine →

The concept primer
You own a term by defining it cleanly and completely. The shorter foundational pieces stake a claim on a concept so that the definition AI repeats is yours. Build it for an emerging term that does not yet have a single canonical explanation. Example: Understanding AI Visibility →
A Repeatable Checklist
Before publishing, run the piece against the things the best 10 have in common:
- Newness or specificity. Is this too new, too specific, or too data-backed for the field to be crowded? If a search shows ten strong pages already, change the angle.
- First-party evidence. Does the article contain at least one number, test result, or observation that exists nowhere else?
- Question headings. Is every section heading a real question, answered completely in its first two sentences?
- Named entities. Are the specific products, bots, APIs, and protocols named exactly, not described generically?
- Claim density. Is the page mostly substance, with facts, numbers, dates, and steps doing the work? Trim the sentences that add none.
- Schema from structure. Do the FAQ and any Dataset schema fall naturally out of the way the piece is written?
- Connected, not isolated. Does it link into a framework and cite supporting evidence, so it sits inside a topical map?
Content that clears all seven is hard to commoditize, because the thing that makes it citable is the thing competitors cannot copy: your data, your specificity, and your timing.
Frequently Asked Questions
What makes content rank in AI engines instead of just classic search?
Specificity and primary evidence. AI engines cite the source that most directly and completely answers a question, and they reward named entities, exact numbers, and self-contained passages. In WISLR’s own data, the 10 articles built on first-party research and precise named entities drew more than 4,000 LLM citations in the last 30 days and sit at average search positions of 4 to 8. Broad commodity guides on the same domain compete in a saturated field where nothing sets one page apart. The difference is topic selection and original data, not domain power.
Why does commodity content fail even on an authoritative domain?
Because thousands of pages already answer the same question, and a model has no reason to prefer yours. WISLR’s commodity guides target queries like “shopify redirects” and “301 redirect shopify,” each earning hundreds of monthly impressions on questions thousands of other pages already answer. The pages are competent and the domain is trusted, yet nothing sets them apart. Commodity topics are a saturated market where the only lever left is brute authority.
How important is original first-party research for AI visibility?
It is the single strongest signal in our data. WISLR’s best-performing articles are built on data only WISLR has: 288,566 server log files analyzed, a five-store controlled test of the Cloudflare crawl endpoint, 1,543 logged checkout-bot requests, a scan of 517 Shopify stores, and 616 scraped customer questions. AI engines preferentially cite primary sources because primary sources are where novel facts originate.
How should I structure an article so an AI engine can quote it?
Write one question per heading and answer it completely in the first two sentences below that heading, before adding nuance. This produces self-contained passages a model can lift without needing the surrounding context. Pair the body with FAQ schema and, where there is underlying data, Dataset schema.
What is non-commodity content and how do I find topics for it?
Non-commodity content answers a question that is too new, too specific, or too data-dependent for anyone else to have answered well yet. Find it by watching for newly shipped products, APIs, bots, and protocols, by going one level more specific than the obvious keyword, and by running tests or pulling logs that generate numbers only you have. WISLR ranks at position 1.99 for “shopify ventures readiness probe” precisely because almost no one else has published on it.
How long should content for AI be?
As long as it takes to fully answer the question and no longer. WISLR’s articles range from roughly 1,000 words for a single sharp definition to over 10,000 words for the most in-depth guides. Length is an output of completeness, not a target.
Can I use AI to write content that other AI engines will cite?
You can use AI to draft and structure, but the citable substance has to come from you. A model cannot invent your server logs, your store scan, or your controlled test. The durable advantage is the first-party data and the specific, verifiable claims you bring to the page. Use AI to organize and sharpen that material into retrievable passages, not to generate generic explanations that already exist in a thousand other places.