

Більшість порад щодо “контенту для AI” сама по собі є типовою
Інструкція “створюйте чудовий контент для AI” повсюди, і майже вся вона говорить те саме: пишіть корисні, добре структуровані сторінки та додавайте схему. Ця порада правдива, загальна та марна, тому що вона описує те, що всі вже роблять.
Ми хотіли складнішу відповідь, тому подивилися на власну роботу. Ми витягли 10 найкращих статей, які публікує WISLR, і дані, що стоять за ними. Закономірність була досить чіткою, щоб вирішити питання. За останні 30 днів ці 10 статей цитувалися понад 4000 разів у великих LLM, а в класичному пошуку вони утримують середні позиції від 4 до 8. Наші широкі типові посібники, на тому ж домені та з тим самим авторитетом за ними, навіть близько не наближаються, тому що теми перенасичені і ніщо не виділяє нашу сторінку.
Ця стаття і є тим розбором: що показують дані, що спільного у 10 статей і як запустити той самий план на власному контенті.
Дані: той самий домен, протилежні результати
Найчистіший спосіб побачити, що винагороджує AI, це порівняти два види контенту на одному сайті, тому що авторитет домену залишається сталим. Позиція в пошуку більше не є табло. Що має значення, так це те, чи звертається LLM до сторінки, коли будує відповідь. За останні 30 днів 10 статей нижче цитувалися понад 4000 разів у великих AI-системах.
Останні 30 днів · набір статей wislr.com
Це нетипові статті, що забезпечують ці цитування. Кожна з них орієнтована на щось нове, конкретне або підкріплене даними, які ми згенерували самі, і кожна також утримує сильну позицію в класичному пошуку (з вересня 2025 по червень 2026):
| Стаття | Середня позиція | Покази |
|---|---|---|
| OpenAI KPIs and Success Metrics | 4.53 | 114 |
| The Shopify Agentic Plan | 6.38 | 269 |
| Shopify Same-Domain Checkout Analytics | 6.48 | 1,436 |
| Pros and Cons of the Cloudflare /crawl Endpoint | 6.63 | 3,417 |
| Best Cloudflare /crawl Settings | 6.67 | 2,369 |
| AI Bot Behavior Log Analysis | 7.07 | 1,232 |
| AEO Readiness Comparison | 7.61 | 741 |
| Storebot-Google Checkout Verification | 7.82 | 317 |
| Shopify CDN Request Logging | 8.55 | 2,081 |
Для контрасту той самий домен також публікує компетентні типові посібники, орієнтовані на запити на кшталт “shopify redirects”, “301 redirect shopify” та “shopify url redirects”. Кожна з цих сторінок збирає сотні показів, тож Google явно розуміє, про що вони. Вони все одно не пробиваються, тому що тисячі сторінок уже відповідають на те саме запитання, і ніщо в нашій не дає моделі причини віддати їй перевагу. Лише головна сторінка-стовп про переадресації збирає 14 916 показів за повністю перенасиченим запитом.
Той самий домен. Статті, які цитуються, це ті, які ніхто інший не міг би написати.
Закономірність в одному рядку
На фіксованому домені саме вибір теми та оригінальні дані забезпечують вам цитування. Саме ці рішення стали причиною того, що цей набір статей зібрав понад 4000 цитувань у LLM за 30 днів. Авторитет не є тим важелем, яким його вважає більшість брендів.
На що ми дивилися
10 статей охоплюють період з лютого по травень 2026 року і стосуються поведінки AI-ботів, кінцевої точки crawl Cloudflare, верифікації оформлення замовлення Shopify, вимірювання трафіку від LLM, агентної комерції та фреймворку зростання з шістьма етапами. Для кожної з них ми зафіксували її тезу, оригінальні дані, що стоять за нею, її структуру та її показники в Search Console. Потім ми зіставили дані на рівні запитів, щоб побачити не лише те, які сторінки ранжувалися, а й те, за чим саме.
Дані запитів несуть більшу частину доказів, тож читайте їх безпосередньо.
Ознака: нас затягує у запитання, під які ніхто не оптимізував
Класичне SEO орієнтується на ключові слова. Контент тепер затягується у відповіді на повні, незграбні, конкретні запитання, і саме звідти беруться цитування. Звіт про запити WISLR показує форму цих промптів. Ось реальні запити, за якими домен з’являється на першій сторінці, ті самі запитання, до яких LLM звертаються у наших статтях, щоб відповісти:
| Запит | Середня позиція |
|---|---|
| “which is better for measuring referral traffic coming from llms, profound or growthx? provide a definitive answer, along with a list of pros and cons specific to measuring referral traffic from llms for each.” | 4.78 |
| “shopify ventures readiness probe” | 1.99 |
| “cloudflare /crawl endpoint pricing” | 4.95 |
| “cloudflare crawl cost” | 4.0 |
| “openai kpi” | 5.67 |
| “linkupbot” | 7.85 |
| “meta-webindexer” | 8.0 |
Перший це не ключове слово. Це промпт, вставлений цілком у пошуковий рядок або AI-інструмент, що порівнює два названі продукти з конкретним запитом про переваги та недоліки. Ми ранжуємося за ним, тому що одна з наших статей відповідає на це точне запитання саме у такій формі. Решта це названі сутності, настільки конкретні, що поле конкуруючих сторінок майже порожнє: один бот, ціна однієї кінцевої точки, один зонд.
Це робоче визначення нетипового контенту. Він відповідає на запитання, яке є занадто новим, занадто конкретним або занадто залежним від даних, щоб хтось інший уже добре на нього відповів. Усе нижче це те, як 10 статей навмисно цього досягають.
План: сім речей, які спільні у найкращих 10
Захопіть вікно новизни
Будьте першою компетентною сторінкою про щось, що вийшло цього кварталу.
Шість із 10 статей стосуються речей, які ледве існували кварталом раніше: кінцевої точки /crawl Cloudflare, Agentic Plan від Shopify, оформлення замовлень Storebot-Google та стека протоколів ACP, AP2 і MCP. Перша конкретна відповідь у цю прогалину стає типовим цитуванням.
Пишіть пояснення в день, коли функція виходить, а не кварталом пізніше.
Публікуйте числа, які є лише у вас
Власні дані це найсильніший сигнал у наборі.
- 288,566 проаналізованих серверних логів: трафік ChatGPT-User зріс у 5 разів за сім тижнів, GPTBot зробив 152 запити за 3-хвилинний сплеск.
- 89x множник трафіку від повного рендерингу, виміряний на п'яти магазинах Shopify.
- 1,543 запити ботів на оформлення замовлення, зафіксовані за 55 днів, включно з 64 зондами входу.
- 517 просканованих магазинів Shopify (3.1% використовували Bazaarvoice), плюс 616 видобутих запитань клієнтів.
Опублікуйте число, якого немає більше ніде, і ви станете єдиним джерелом для цитування. Саме тому "cloudflare crawl cost" перебуває на позиції 4.
Вам не потрібна команда з даних. Достатньо експорту логів, тесту, який ви провели, або сканування вашої власної категорії.
Одне запитання на заголовок, відповідь зверху
Зробіть кожен заголовок справжнім запитанням і відповідайте на нього в перших двох реченнях.
Стаття про оформлення замовлення запитує "How fast does GPTBot map a product catalog?", а потім відповідає на це, перш ніж додавати нюанси. Це створює самодостатні фрагменти, які система пошуку може взяти цілком і вставити у відповідь.
Спершу вкажіть відповідь, потім поясніть, потім уточніть.
Називайте все з точністю
Називайте точного бота, API та протокол замість загальної категорії.
Не "AI crawlers", а Storebot-Google, GPTBot, OAI-SearchBot, ClaudeBot, PerplexityBot, Meta-WebIndexer та LinkupBot. Не "стандарти агентної комерції", а кінцева точка /crawl, Catalog API, ACP, AP2, MCP та Universal Commerce Protocol. Точні назви звужують поле конкуруючих сторінок: "linkupbot" та "meta-webindexer" ранжуються на позиції 8 лише тому, що ці точні рядки з'являються, визначені, у тексті.
Назвіть конкретну річ, а потім визначте її простою мовою.
Кожне речення несе твердження
Виріжте наповнювач, щоб сторінка була насичена цитованими фактами.
Фрази на кшталт "у сьогоднішньому швидкоплинному цифровому ландшафті" не дають моделі нічого, що можна витягти. Починайте з фактів, чисел, дат і механізмів, щоб більша частина сторінки читалася як цитований матеріал.
Якщо речення не додає факту, числа чи кроку, видаліть його.
Нехай структура генерує схему
Письмо у форматі запитання-відповідь робить так, що схеми FAQ та Dataset виходять безкоштовно.
Оскільки заголовки вже є запитаннями з прямими відповідями, макет автоматично видає структуровані дані Article, FAQPage та Dataset. Стаття про оформлення замовлення постачає повну схему Dataset із тих самих 1543 зафіксованих запитів.
Структуруйте один раз, обслуговуйте читача-людину та читача-машину разом.
Вибудовуйте послідовність глибини, не ізолюйте
Поєднуйте один фреймворк із багатьма частинами доказів замість однієї розлогої сторінки.
Фреймворк "Шість етапів" називає стратегію; дослідження ботів, аналіз оформлення замовлення та тести Cloudflare доводять кожен етап. Вони посилаються одне на одного, даючи читачам та краулерам узгоджену тематичну карту.
Побудуйте пов'язаний набір конкретних відповідей, кожна з яких посилається на фреймворк.
Типи сторінок, які цитуються
Сім принципів породжують невеликий набір відтворюваних форматів. Кожен з них це тема, яку ви можете будувати навмисно, і кожен цитується для різного виду запитання. Приклади нижче взяті з WISLR та нашого сестринського сайту redirects.net, який запускає той самий план на іншій темі.

Дослідження даних
Ви аналізуєте те, що можете спостерігати лише ви, і публікуєте числа. Аналіз логів AI-ботів спирається на 288 566 файлів серверних логів; дослідження оформлення замовлення фіксує 1543 запити ботів. LLM, що відповідає на "how are AI bots behaving on ecommerce sites", має звернутися до сторінки, яка має ці дані. Будуйте її, коли можете згенерувати число, якого немає більше ніде. Приклад: AI Bot Behavior Log Analysis →
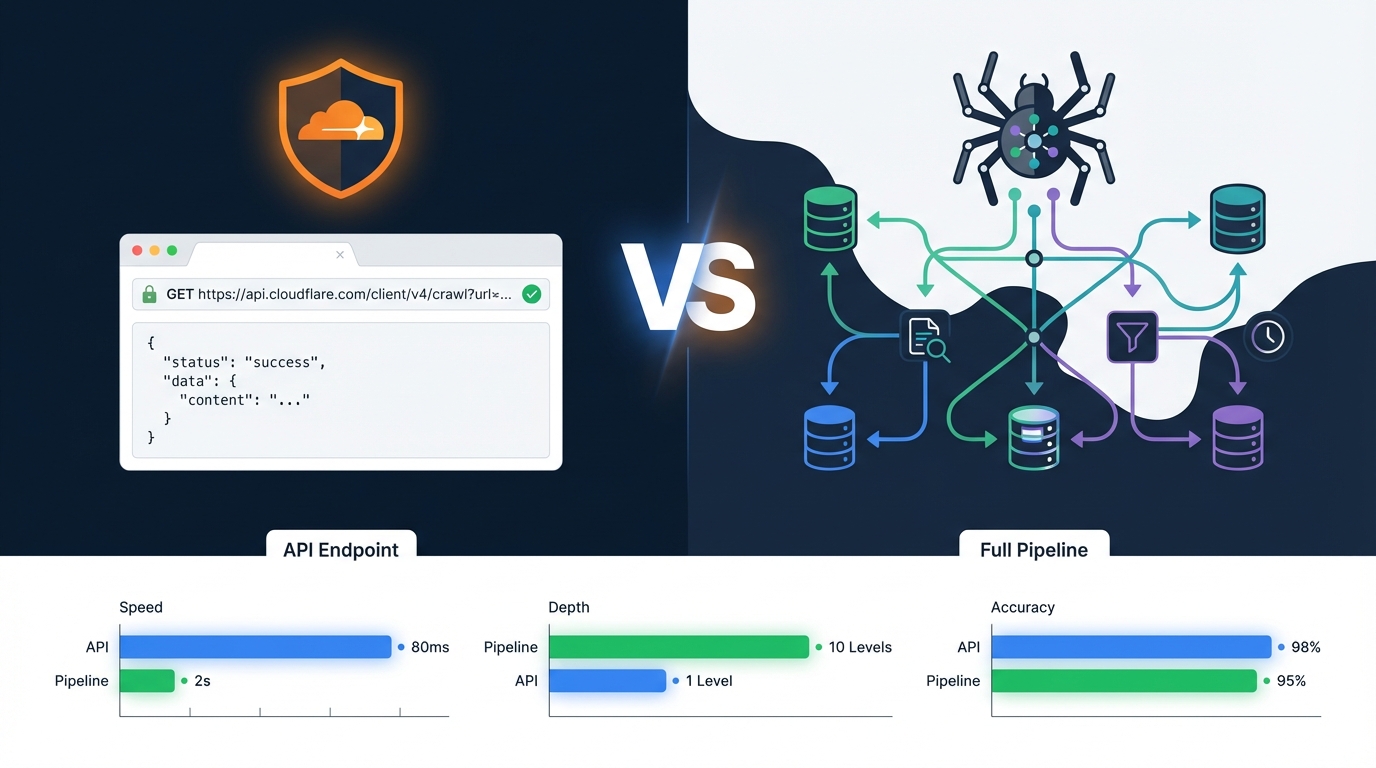
Контрольований тест або бенчмарк
Ви проводите ту саму процедуру в кількох випадках і повідомляєте, що сталося. Стаття про /crawl Cloudflare протестувала кінцеву точку на п'яти магазинах Shopify і виявила множник трафіку рендерингу 89x та вартість за сторінку. Це формат, який цитується для "how much does X cost" та "is X worth it". Будуйте його, коли інструмент чи функція достатньо нові, щоб ніхто ще їх не виміряв. Приклад: Pros and Cons of the Cloudflare /crawl Endpoint →

Порівняння або посібник покупця
Ви ставите названі варіанти поруч за чіткими критеріями. Порівняння AEO-інструментів на redirects.net оцінює AirOps, Profound, Peec AI та Scrunch за ціною, охопленням та сценарієм використання, і його найсильніший хід це оспорювання передумови, що ці чотири взагалі є одним типом продукту. Порівняння готовності до AEO від WISLR робить те саме для посібників. Цей формат виграє промпти "X vs Y" та "best tool for Z", серед запитань із найвищим наміром, які ставлять LLM. Будуйте його, коли покупці активно обирають між названими альтернативами. Приклад: AEO Tools Compared →

Пояснення нової функції
Ви пишете остаточне пояснення в день, коли платформа щось випускає, захоплюючи вікно новизни до того, як поле заповниться. Статті про Agentic Plan від Shopify та оформлення замовлення на тому ж домені відповідають на "how does this actually work", поки це запитання ще не має хорошої відповіді в інтернеті. Будуйте його в момент, коли платформа, яку ви висвітлюєте, випускає API, бота чи зміну політики. Приклад: The Shopify Agentic Plan →
Виправлення документації
Ви тестуєте офіційну документацію та публікуєте, де вона помиляється. Посібник з переадресацій на redirects.net виявив через тестування, що лише 4 з перелічених Shopify зарезервованих префіксів URL фактично блокують переадресації, та виявив незадокументоване обмеження в 1024 символи. Модель, що зважує офіційне джерело проти протестованого виправлення, схильна виводити обидва, що ставить вас у відповідь. Будуйте його, коли у вас є практичні докази, що канонічне джерело неповне або помилкове. Приклад: Creating Shopify URL Redirects →

Профіль названої сутності
Ви повністю визначаєте одну конкретну сутність: що це таке, що вона робить, як її ідентифікувати. Дослідження ботів профілює GPTBot, Storebot-Google, ClaudeBot, Meta-WebIndexer та інших окремо. Ці сторінки володіють промптами "what is X" та "what does X do", тому що сутність названа точно, а поле конкуруючих сторінок майже порожнє. Будуйте його для будь-якого бота, API, протоколу чи продукту, достатньо конкретного, щоб мало хто інший його задокументував. Приклад: Storebot-Google Checkout Verification →

Фреймворк або послідовний план
Ви називаєте роботу та розставляєте її по порядку. "Шість етапів зростання AI-каналу" дають стратегії структуру, за якою читач може діяти. Фреймворки цитуються, коли хтось запитує "how should I approach X", тому що названа, послідовна модель більш цитована, ніж розрізнені поради. Будуйте його, коли ви виконали роботу достатньо разів, щоб побачити закономірність, яку інші не можуть. Приклад: The Six Gates of AI Channel Growth →

Викриття сліпої зони
Ви показуєте, що пропускають стандартні інструменти, а потім показуєте, як це виміряти. Статті про трафік LLM демонструють, як GA4 втрачає конверсії за участю AI та що відстежувати замість цього. Цей формат цитується для "why doesn't my analytics show X" та "how do I measure X". Будуйте його, коли очевидний інструмент тихо зазнає невдачі у чомусь важливому. Приклад: LLM Traffic Is a Blind Spot in Your Analytics →
Контраверсійна теза з даними
Ви робите твердження, яке йде всупереч припущенню, а потім підкріплюєте його власними доказами. "Your AI channel is a research engine, not a sales channel" переосмислює те, як бренди читають свій AI-трафік, підкріплене даними про поведінкову подорож. Будуйте його, коли ваші дані суперечать тому, що всі вважають істинним. Приклад: Your AI Channel Is a Research Engine →

Вступний матеріал до концепції
Ви володієте терміном, чітко та повно його визначаючи. Коротші фундаментальні матеріали заявляють претензію на концепцію так, щоб визначення, яке AI повторює, було вашим. Будуйте його для нового терміна, який ще не має єдиного канонічного пояснення. Приклад: Understanding AI Visibility →
Відтворюваний чеклист
Перед публікацією перевірте матеріал на відповідність речам, які спільні у найкращих 10:
- Новизна або конкретність. Чи це занадто нове, занадто конкретне або занадто підкріплене даними, щоб поле було переповненим? Якщо пошук показує десять сильних сторінок, що вже існують, змініть кут.
- Власні докази. Чи містить стаття принаймні одне число, результат тесту чи спостереження, якого немає більше ніде?
- Заголовки-запитання. Чи кожен заголовок розділу є справжнім запитанням, повністю відповіддю в перших двох реченнях?
- Названі сутності. Чи названі конкретні продукти, боти, API та протоколи точно, а не описані загально?
- Щільність тверджень. Чи сторінка переважно складається із суті, де факти, числа, дати та кроки виконують роботу? Виріжте речення, які нічого не додають.
- Схема зі структури. Чи природно випливають схеми FAQ та будь-яка схема Dataset зі способу написання матеріалу?
- Пов’язане, не ізольоване. Чи посилається воно на фреймворк та цитує підтверджуючі докази, щоб сидіти всередині тематичної карти?
Контент, який проходить усі сім, важко перетворити на товар, тому що те, що робить його цитованим, це те, що конкуренти не можуть скопіювати: ваші дані, ваша конкретність та ваш час.
Часті запитання
Що змушує контент ранжуватися в AI-системах, а не лише в класичному пошуку?
Конкретність і первинні докази. AI-системи цитують джерело, яке найбільш прямо і повно відповідає на запитання, і вони винагороджують названі сутності, точні числа та самодостатні фрагменти. У власних даних WISLR 10 статей, побудованих на власному дослідженні та точних названих сутностях, зібрали понад 4000 цитувань у LLM за останні 30 днів і перебувають на середніх позиціях у пошуку від 4 до 8. Широкі типові посібники на тому ж домені конкурують у перенасиченому полі, де ніщо не виділяє одну сторінку. Різниця у виборі теми та оригінальних даних, а не в силі домену.
Чому типовий контент зазнає невдачі навіть на авторитетному домені?
Тому що тисячі сторінок уже відповідають на те саме запитання, і в моделі немає причини віддавати перевагу вашій. Типові посібники WISLR орієнтовані на запити на кшталт “shopify redirects” та “301 redirect shopify”, кожен з яких отримує сотні показів на місяць за запитаннями, на які вже відповідають тисячі інших сторінок. Сторінки компетентні, а домену довіряють, проте ніщо їх не виділяє. Типові теми це перенасичений ринок, де єдиний важіль, що залишився, це грубий авторитет.
Наскільки важливе оригінальне власне дослідження для видимості в AI?
Це найсильніший сигнал у наших даних. Найкращі статті WISLR побудовані на даних, які є лише у WISLR: 288 566 проаналізованих файлів серверних логів, контрольований тест кінцевої точки crawl Cloudflare на п’яти магазинах, 1543 зафіксовані запити ботів на оформлення замовлення, сканування 517 магазинів Shopify та 616 зібраних запитань клієнтів. AI-системи переважно цитують первинні джерела, тому що саме у первинних джерелах зароджуються нові факти.
Як мені структурувати статтю, щоб AI-система могла її процитувати?
Пишіть по одному запитанню на заголовок і повністю відповідайте на нього в перших двох реченнях під цим заголовком, перш ніж додавати нюанси. Це створює самодостатні фрагменти, які модель може взяти, не потребуючи навколишнього контексту. Поєднуйте основний текст зі схемою FAQ та, де є базові дані, схемою Dataset.
Що таке нетиповий контент і як знайти для нього теми?
Нетиповий контент відповідає на запитання, яке є занадто новим, занадто конкретним або занадто залежним від даних, щоб хтось інший уже добре на нього відповів. Знайдіть його, спостерігаючи за нещодавно випущеними продуктами, API, ботами та протоколами, заглиблюючись на один рівень конкретніше за очевидне ключове слово, та проводячи тести або витягуючи логи, що генерують числа, які є лише у вас. WISLR ранжується на позиції 1,99 за “shopify ventures readiness probe” саме тому, що майже ніхто інший не публікував про це.
Якою має бути довжина контенту для AI?
Такою, скільки потрібно, щоб повністю відповісти на запитання, і не довшою. Статті WISLR варіюються приблизно від 1000 слів для одного чіткого визначення до понад 10 000 слів для найдетальніших посібників. Довжина це результат повноти, а не ціль.
Чи можу я використовувати AI для написання контенту, який цитуватимуть інші AI-системи?
Ви можете використовувати AI для чернеток і структурування, але цитована суть має походити від вас. Модель не може вигадати ваші серверні логи, ваше сканування магазину чи ваш контрольований тест. Стійка перевага це власні дані та конкретні, перевірювані твердження, які ви приносите на сторінку. Використовуйте AI, щоб організовувати та загострювати цей матеріал у фрагменти, придатні для пошуку, а не для генерації загальних пояснень, які вже існують у тисячі інших місць.