
Was ist der Cloudflare /crawl Endpoint?
Cloudflares /crawl Endpoint ist Teil ihrer Browser Rendering API, die sich derzeit in der offenen Beta befindet. Er scrapt Inhalte von einer Start-URL, folgt Links ueber die gesamte Website bis zu einer konfigurierbaren Tiefe oder Seitenlimit und gibt die Ergebnisse als HTML, Markdown oder strukturiertes JSON zurueck, angetrieben von Workers AI. Cloudflare positioniert ihn als Werkzeug fuer das Training von Modellen, den Aufbau von RAG-Pipelines und die Recherche oder Ueberwachung von Inhalten ueber eine Website hinweg.
Der Endpoint arbeitet als signierter Agent, der standardmaessig robots.txt und Cloudflares AI Crawl Control respektiert, was eine bemerkenswerte Design-Entscheidung ist. Er soll es Entwicklern erleichtern, Website-Regeln einzuhalten, und es Crawlern erschweren, die Anweisungen von Website-Betreibern zu ignorieren.
Der Endpoint befindet sich unter:
https://api.cloudflare.com/client/v4/accounts/<account_id>/browser-rendering/crawl
Sie benoetigen ein Cloudflare-API-Token mit Browser Rendering Edit-Berechtigung, um ihn zu nutzen.
So funktioniert es
Der Crawl laeuft als asynchroner Job in zwei Schritten:
- Starten Sie den Crawl mit einem POST-Request, der eine Start-URL enthaelt. Die API gibt sofort eine Job-ID zurueck.
- Abfrage der Ergebnisse mit GET-Requests unter Verwendung dieser Job-ID. Wenn der Job-Status von
runningzucompletedwechselt, sind Ihre gecrawlten Daten bereit.
Jobs koennen bis zu sieben Tage laufen. Ergebnisse werden 14 Tage nach Abschluss gespeichert.
Was Sie senden
Mindestens senden Sie eine URL:
curl -X POST 'https://api.cloudflare.com/client/v4/accounts/{account_id}/browser-rendering/crawl' \
-H 'Authorization: Bearer <apiToken>' \
-H 'Content-Type: application/json' \
-d '{
"url": "https://example.com"
}'
Wichtige Parameter
| Parameter | Standard | Funktion |
|---|---|---|
limit |
10 | Max. zu crawlende Seiten (bis zu 100.000) |
depth |
100.000 | Max. Link-Tiefe ab Start-URL |
source |
all |
Wo URLs entdeckt werden: all, sitemaps oder links |
formats |
HTML | Antwortformat: html, markdown oder json |
render |
true | JavaScript ausfuehren (true) oder schneller HTML-Abruf (false) |
maxAge |
86.400 | Cache-TTL in Sekunden (max. 604.800) |
modifiedSince |
keiner | Unix-Zeitstempel: nur Seiten crawlen, die nach diesem Zeitpunkt geaendert wurden |
options.includePatterns |
keiner | Nur URLs crawlen, die diesen Wildcard-Mustern entsprechen |
options.excludePatterns |
keiner | URLs ueberspringen, die diesen Mustern entsprechen |
Was Sie zurueckbekommen
Jede gecrawlte Seite wird als Datensatz mit der URL, dem Status, dem Inhalt im gewaehlten Format und grundlegenden Metadaten (HTTP-Statuscode, Seitentitel, finale URL nach Weiterleitungen) zurueckgegeben. Mit render: true erhalten Sie auch Open-Graph-Tags. Die Antwort enthaelt ausserdem browserSecondsUsed fuer Abrechnungstransparenz und einen cursor fuer die Paginierung von Ergebnissen, die 10 MB ueberschreiten.
Hier ist die tatsaechliche Job-Level-Antwort eines 24-seitigen gerenderten Crawls eines Live-Shopify-Stores:
{
"job_id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890",
"status": "completed",
"total": 24,
"finished": 24,
"browserSecondsUsed": 58.38,
"record_count": 24,
"records": [
{
"url": "https://www.example-store.com/products/premium-widget-bundle",
"status": "completed",
"metadata": {
"status": 200,
"title": "Premium Widget Bundle | Example Store",
"url": "https://www.example-store.com/products/premium-widget-bundle",
"lastModified": "",
"og:type": "product",
"og:site_name": "Example Store",
"og:title": "Premium Widget Bundle | Example Store",
"og:image": "https://www.example-store.com/cdn/shop/files/product-image.jpg",
"og:description": "Our best-selling bundle with everything you need..."
},
"markdown": "Store\n\nexample-store\n\nURL\n\nhttps://www.example-store.com\n\nCurrency\n\nUSD\n\n# Premium Widget Bundle\n\nOur best-selling bundle with everything you need..."
}
]
}
Mit render: true enthaelt das Metadaten-Objekt den vollstaendigen Satz an Open-Graph-Feldern: Typ, Site-Name, Titel, Bild-URL und Beschreibung. Diese werden waehrend des Browser-Renderings aus den OG-Meta-Tags der Seite gezogen. Mit render: false enthalten die Metadaten nur den HTTP-Statuscode, den Seitentitel und die finale URL. Es werden keine Open-Graph-Felder extrahiert.
Das Markdown-Feld enthaelt die gesamte Seitenausgabe, nicht nur den Hauptinhalt. Navigationsmenues, Mega-Menues, Footer und sich wiederholende Template-Bloecke sind in jedem Datensatz enthalten. In unseren Tests gab die durchschnittliche Seite etwa 158 KB Markdown zurueck, wobei ca. 90% davon wiederholter Boilerplate-Inhalt war. Wenn Sie dies in ein LLM oder eine RAG-Pipeline einspeisen, benoetigen Sie Ihre eigene Content-Extraktionslogik, um das Template zu entfernen und den tatsaechlichen Seiteninhalt zu isolieren.
Hier ist, was derselbe Store zurueckgab, als wir render: false ausfuehrten:
{
"job_id": "f9e8d7c6-b5a4-3210-fedc-ba9876543210",
"status": "completed",
"total": 266,
"finished": 266,
"browserSecondsUsed": 0,
"record_count": 256,
"records": [
{
"url": "https://www.example-store.com/products/classic-knit-sweater",
"status": "completed",
"metadata": {
"status": 200,
"title": "Classic Knit Sweater | Example Store",
"url": "https://www.example-store.com/products/classic-knit-sweater",
"lastModified": ""
},
"markdown": "Skip to content\n\nFree Shipping $150+\n\n# Classic Knit Sweater\n\nOur best-selling sweater made from premium natural fibers..."
}
]
}
Null Browser-Sekunden, 256 Datensaetze von 266 Seiten. Die Metadaten sind im Vergleich zur gerenderten Version minimal: keine Open-Graph-Felder, nur der HTTP-Status, der Seitentitel und die URL. Aber das Markdown enthaelt weiterhin den vollstaendigen Seiteninhalt einschliesslich Navigation, Produktdetails und Footer. Fuer servergerenderte Shopify Stores ist im statischen HTML bereits alles vorhanden, was Sie brauchen.
URL-Erkennung
Der Crawler entdeckt URLs ueber drei Quellen (wenn source auf all gesetzt ist):
- Die Start-URL, die Sie angeben
- Sitemap-Links, die auf der Domain gefunden werden
- Interne Links, die auf gecrawlten Seiten gefunden werden
Sie koennen dies mit dem source-Parameter auf nur Sitemaps oder nur Seitenlinks beschraenken. excludePatterns hat immer Vorrang vor includePatterns, sodass Sie ein weites Netz auswerfen und dann Bereiche ausschliessen koennen, die Sie nicht benoetigen.
Rendering vs. Schneller Abruf
render: true (Standardeinstellung) startet einen Headless-Browser, fuehrt JavaScript aus und wartet, bis die Seite vollstaendig geladen ist. Dies ist notwendig fuer Single-Page-Applikationen und JavaScript-gerenderte Inhalte, verbraucht aber Browser-Sekunden, die abgerechnet werden.
render: false fuehrt einen schnellen HTML-Abruf ohne JavaScript-Ausfuehrung durch. Waehrend der Beta werden diese Abrufe nicht berechnet. Dies ist die richtige Wahl fuer statische Websites oder servergerenderte Seiten, bei denen der Inhalt bereits im initialen HTML enthalten ist.
Abrechnung und Verfuegbarkeit
Der Endpoint ist sowohl auf Workers Free als auch auf Paid Plans verfuegbar. Gerenderte Crawls werden nach Cloudflares Browser Rendering-Preisen mit 0,09 $ pro Browser-Stunde ueber Ihre enthaltene Zuteilung hinaus abgerechnet.
Workers Free: 10 Minuten Browser-Zeit pro Tag. Der /crawl Endpoint ist auf 5 Jobs pro Tag, 100 Seiten pro Crawl und 6 API-Anfragen pro Minute begrenzt.
Workers Paid (5 $/Monat): 10 Stunden Browser-Zeit pro Monat inklusive. Keine Crawl-Seitenlimits. 600 API-Anfragen pro Minute. Zusaetzliche Browser-Stunden kosten je 0,09 $.
render: false Crawls verbrauchen null Browser-Zeit. Sie sind waehrend der Beta kostenlos, werden aber letztendlich unter die Standard-Workers-Preise fallen.
Was ist Wall-Clock-Zeit?
Wall-Clock-Zeit ist die gesamte verstrichene Zeit vom Start eines Crawls bis zu seinem Abschluss, gemessen so, wie Sie es mit einer Stoppuhr messen wuerden. Sie umfasst alles: Netzwerklatenz, Cloudflares interne Warteschlangenzeit, DNS-Lookups, Server-Antwortzeit und (wenn Rendering aktiviert ist) Browser-Ausfuehrungszeit.
Wall-Clock-Zeit unterscheidet sich von Browser-Zeit. Browser-Zeit zaehlt nur die Sekunden, die Cloudflares Headless-Browser aktiv mit dem Rendern von Seiten verbringt. Ein Crawl koennte 22 Minuten Browser-Zeit verbrauchen, aber 25 Minuten Wall-Clock-Zeit benoetigten, wegen Warteschlangen- und Netzwerk-Overhead. Crawls ohne Rendering verbrauchen null Browser-Zeit, haben aber dennoch Wall-Clock-Zeit durch den Abruf- und Warteschlangenprozess.
In unseren Benchmarks berichten wir beide Zahlen, damit Sie sehen koennen, wofuer Sie bezahlen (Browser-Zeit) im Vergleich dazu, wie lange Sie tatsaechlich warten (Wall-Clock-Zeit).
Das Kleingedruckte
Der Endpoint respektiert robots.txt-Direktiven einschliesslich crawl-delay. Er identifiziert sich als CloudflareBrowserRenderingCrawler/1.0. Er umgeht keine CAPTCHAs, Turnstile-Challenges oder anderen Bot-Schutz. Wenn Sie Ihre eigene Website crawlen und blockiert werden, muessen Sie eine WAF-Skip-Regel erstellen, um den Crawler auf die Allowlist zu setzen.
Wie sich Cloudflare /crawl ueber fuenf Shopify Stores hinweg verhaelt
Wir haben den /crawl Endpoint gegen fuenf Live-Shopify-Stores laufen lassen, um Geschwindigkeit, Erfolgsrate, Kosten und die Interaktion des Crawlers mit jedem Store zu messen. Jeder Store-Name ist anonymisiert. Dies sind echte Zahlen aus echten Crawls. Wall-Clock-Zeiten sind ungefaehre Schaetzungen. Einige fruehe Tests verwendeten Skripte mit eingeschraenkter Fehlerbehandlung, was die berichteten Erfolgsraten bei bestimmten Stores beeinflusst haben koennte. Wo dies zutrifft, vermerken wir es unten.
Dies ist kein Endpoint, den man einfach einrichtet und vergisst. Jeder Store reagierte unterschiedlich auf Endpoint-Anfragen. Einige benoetigten Resource-Blocking, um einen gerenderten Crawl abzuschliessen. Andere gaben bei einem Modus 429-Fehler zurueck, funktionierten aber im anderen einwandfrei. Crawl-Delay-Direktiven, Seitenanzahl und Store-Architektur beeinflussten alle das Ergebnis. Planen Sie ein, die Einstellungen fuer jede Website, die Sie crawlen, zu testen und anzupassen.
Test 1: Grosser E-Commerce-Katalog (Store A)
Wir haben den /crawl Endpoint auf einen grossen Shopify Store mit fast 3.000 Seiten gerichtet. Inhalte kamen schnell zurueck, das Markdown war brauchbar, und der Endpoint hatte keine Probleme beim Abrufen von Produktseiten, Kollektionsseiten und Blog-Inhalten. Keine Proxy-Probleme, keine Blockaden, kein Rate-Limiting.
Wir haben mehrere Crawls in verschiedenen Groessen durchgefuehrt:
| Crawl-Groesse | Zurueckgegebene Seiten | Modus | Browser-Zeit | Wall Clock |
|---|---|---|---|---|
| 20-Seiten-Stichprobe | 20 / 20 (100%) | no-render | 0s | ~1 Min. |
| 500-Seiten-Crawl | 500 / 500 (100%) | no-render | 0s | ~18 Min. |
| 5-Seiten gerendert | 4 / 5 (80%) | render: true | 0,9s | ~10s |
Crawling ohne JavaScript-Rendering erreichte 100% Erfolg in beiden Groessen. Vollstaendiges Browser-Rendering gab 4 von 5 Seiten in einem kleinen Stichprobentest zurueck. Bei einer so kleinen Stichprobe koennte die einzelne fehlende Seite ein Browser-Timeout, ein voruebergehender Fehler oder ein Skript-seitiges Problem sein.
Test 2: Kleiner Shopify Store (Store D, 24 Seiten)
Ein kleinerer Store, an dem wir den vollstaendigen Workflow getestet haben:
Crawling ohne Rendering gab Fehler zurueck. Unser erster Test ergab 429-Antworten beim einfachen HTML-Abruf. Wir haben diesen Store nicht erneut mit verbesserter Fehlerbehandlung getestet, daher koennen wir nicht bestaetigen, ob die 429er vom Rate-Limiting des Stores oder von voruebergehenden Problemen waehrend des Tests stammten.
Vollstaendiges Rendering mit Sitemap-basierter Erkennung war ein kompletter Erfolg. 24 von 24 Seiten gecrawlt, 100% Abschluss.
| Seitentyp | Anzahl |
|---|---|
| Produkte | 9 |
| Kollektionen | 4 |
| Seiten | 3 |
| Blogs/News | 5 |
| Sonstige (Startseite, Blog-Index) | 3 |
Eine wichtige Entdeckung: Der Standard-URL-Erkennungsmodus fand nur 1 Seite, weil die Startseite fast keine internen Links hatte. Der Wechsel zur Sitemap-basierten Erkennung fand alle 24. Wenn Ihre Startseite minimal oder JavaScript-lastig ist, findet der Crawler moeglicherweise keine Seiten allein durch Links.
Test 3: Mittelgrosser Bekleidungs-Store (Store B, 256 Seiten), mit und ohne Rendering
Unser detailliertester Test. Ein mittelgrosser Bekleidungs-Store mit 256 indexierbaren Seiten: Produkte, Kollektionen, Blog-Beitraege und Informationsseiten. Wir haben beide Modi auf der gesamten Website ausgefuehrt, um den tatsaechlichen Unterschied zu messen.
| Metrik | render: false | render: true | Unterschied |
|---|---|---|---|
| Gecrawlte Seiten | 256 / 266 | 256 / 266 | Gleich |
| Gesamte Markdown-Ausgabe | 11,0 MB | 12,5 MB | +14% |
| Browser-Zeit | 0s | 1.338s (22 Min.) | +22 Min. |
| Geschaetzte Kosten | 0 $ (Beta) | ~0,03 $ | +0,03 $ |
| Wall-Clock-Zeit | ~5 Min. | ~25 Min. | 5x langsamer |
Test 4: Gesundheits- und Nahrungsergaenzungsmittel-Haendler (Store C), teilweiser Erfolg im grossen Massstab
Ein grosser Gesundheitsprodukte-Haendler mit einem riesigen Katalog. Wir haben zwei Crawls ohne Rendering in verschiedenen Groessen durchgefuehrt:
| Crawl-Groesse | Zurueckgegebene Seiten | Erfolgsrate | Wall Clock |
|---|---|---|---|
| 5-Seiten-Stichprobe | 2 / 5 | 40% | ~25s |
| 100-Seiten-Crawl | 89 / 100 | 89% | ~3,5 Min. |
Die teilweise Erfolgsrate koennte darauf hindeuten, dass die Infrastruktur dieses Stores einige Nicht-Browser-Anfragen ablehnt, aber unser erster Test hatte keine robuste Fehlerbehebung, sodass einige dieser Fehlschlaege mit besserer Retry-Behandlung auf unserer Seite behebbar gewesen sein koennten. Die Erfolgsrate verbesserte sich von 40% auf 89% bei groesserem Massstab. Wir haben diesen Store nicht erneut mit verbesserter Fehlerbehandlung getestet, um die Ursache zu isolieren.
Test 5: Grosser Multi-Kategorie-Store (Store E, ~1.200 Seiten)
Unser groesster und aufschlussreichster Test. Ein Shopify Store mit etwa 1.200 URLs, verteilt auf vier Sitemaps: 521 Produkte, 626 Kollektionen, 22 Seiten und 31 Blog-Beitraege.
| Metrik | render: false | render: true (optimiert) |
|---|---|---|
| Gecrawlte Seiten | 1.200 / 1.200 | 100 / 100 |
| Gesamte Markdown-Ausgabe | 148,5 MB | 11,3 MB |
| Browser-Zeit | 0s | 475s (~8 Min.) |
| Geschaetzte Kosten | 0 $ (Beta) | ~0,012 $ |
| Wall-Clock-Zeit | ~55 Min. | ~12 Min. |
Der No-Render-Crawl erreichte 100% Erfolg ueber alle 1.200 Seiten bei null Browser-Kosten. Der gerenderte Crawl wurde auf einer 100-Seiten-Stichprobe mit aktivierten Resource-Blocking-Optimierungen ausgefuehrt.
Resource-Blocking machte den Unterschied zwischen einem haengenden und einem sauberen Crawl. Ohne Resource-Blocking hing der gerenderte Crawl auf unbestimmte Zeit bei 99 von 100 Seiten und verbrauchte 649 Sekunden Browser-Zeit fuer diese 99 Seiten. Das Aktivieren von Resource-Blocking (Bilder, Medien, Fonts, Stylesheets) mit einer domcontentloaded-Wartebedingung schloss alle 100 Seiten in 475 Sekunden ab, eine 27%ige Reduzierung der Browser-Zeit ohne Haengenbleiben.
Crawl-Delay in robots.txt verursachte sichtbare Stillstaende. Die robots.txt von Store E gibt einen 10-Sekunden-Crawl-Delay fuer bestimmte Bots an. In unseren No-Render-Polling-Daten zeigte sich dies als mehrminuetige Plateaus, bei denen die Seitenzahl stagnierte, bevor sie wieder anstieg. Der Cloudflare-Crawler respektiert Crawl-Delay-Direktiven, was die Wall-Clock-Zeit bei Websites, die diese setzen, direkt verlaengert.
Was der /crawl Endpoint tatsaechlich akzeptiert
Der Endpoint nimmt eine Start-URL entgegen, keine Liste. Er entdeckt Seiten durch Spidering von dieser URL aus ueber Sitemaps, Seitenlinks oder beides. Wenn Sie bereits eine URL-Liste aus einem Scrapy-Crawl haben und Cloudflare fuer die Markdown-Konvertierung nutzen moechten, muessten Sie stattdessen die separaten /markdown- oder /scrape-Endpoints einzeln pro URL aufrufen.
Was macht Cloudflare /crawl tatsaechlich auf der Serverseite?
Wir haben die vollstaendigen Server-Logs waehrend eines vollstaendig gerenderten Crawls von Store D (25 Seiten) ausgewertet, um den tatsaechlichen Traffic-Fussabdruck zu analysieren. Die Ergebnisse offenbaren grundlegende Unterschiede zwischen browsergerendertem Crawling und traditionellem Bot-Crawling, mit unbeabsichtigten Nebenwirkungen fuer Analytics, Serverlast und Bot-Traffic-Monitoring.
| Metrik | Wert |
|---|---|
| User-Agent | CloudflareBrowserRenderingCrawler/1.0 (100% der Zugriffe) |
| Crawl-Fenster | 134 Sekunden (~2 Minuten) |
| Spitzendurchsatz | 82 Anfragen/Sekunde |
| Einzigartige IPs | 23, ueber 5 Cloudflare-Rechenzentren |
| GET-Anfragen | 2.071 |
| POST-Anfragen | 163 |
| Gesamtanfragen | 2.234 |
| Tatsaechlich gerenderte Seiten | ~25 |
| Anfragen pro Seite | ~89-fache Verstaerkung |
Wie viel Traffic erzeugt ein vollstaendig gerenderter Cloudflare /crawl tatsaechlich?
Die groesste Erkenntnis: Nur 1,1% der 2.234 Anfragen waren tatsaechlicher Seiteninhalt. Die anderen 98,9% waren JavaScript, CSS, Analytics-Beacons, Tracking-Pixel und Checkout-Preloads, die durch den Browser ausgeloest wurden, der jede Seite wie ein echter Besucher laedt.
Ein nicht-gerenderter Bot wie Amazonbot oder ChatGPT-User erzeugt 1 Anfrage pro Seite. Der Cloudflare Browser-Renderer erzeugt 89.
Verfaelscht Cloudflare /crawl Shopify-Analytics?
Die 163 POST-Anfragen in unseren Logs waren ausschliesslich Shopify-Analytics- und Tracking-Endpoints, die waehrend des Crawls ausgeloest wurden. Dies sind dieselben Events, die ausgeloest werden, wenn ein echter Kunde Ihren Store besucht. Aus Sicht von Shopify Analytics sieht der Cloudflare-Crawler wie ein Besucher aus, der in 2 Minuten jede Seite Ihres Stores durchstoeebert.
Wie schnell trifft Cloudflare /crawl auf Ihren Server?
Alle 2.234 Anfragen landeten in einem 134-Sekunden-Fenster. Der Spitzendurchsatz erreichte 82 Anfragen pro Sekunde. Der Crawler renderte die gesamte 25-Seiten-Website in knapp ueber 2 Minuten, aber der Server sah einen anhaltenden Burst von Traffic, der in keiner Weise organischen Browsing-Mustern aehnelt.
Fuer kleine Stores ist das handhabbar. Fuer groessere Stores mit Tausenden von Seiten koennte die Anfrageverstaerkung (89-fach pro Seite) in Kombination mit anhaltendem Durchsatz eine spuerbare Last auf dem Origin-Server erzeugen, besonders wenn Sie auf einem Shared-Hosting-Plan sind oder aggressives Rate-Limiting eingerichtet haben.
Woher kommt Cloudflare /crawl?
Der Crawl wurde ueber 5 Cloudflare-Rechenzentren in den USA verteilt:
| Rechenzentrum | % der Anfragen | Standort |
|---|---|---|
| ATL | 38% | Atlanta |
| ORD | 25% | Chicago |
| MIA | 23% | Miami |
| EWR | 9% | Newark |
| IAD | 5% | Washington DC |
Dies ist nicht ein einzelner Server, der Anfragen stellt. Cloudflare verteilt die Rendering-Arbeitslast ueber sein Edge-Netzwerk. Alle 23 IPs lagen im 104.28.x.x-Bereich, und der User-Agent war CloudflareBrowserRenderingCrawler/1.0 bei jeder einzelnen Anfrage.
Welchen Browser-Fingerabdruck hinterlaesst Cloudflare /crawl?
Der Renderer sendet korrekte Sec-Fetch-Header, die einen echten Chrome-Browser nachahmen:
| Header | Wert | Echtes Chrome? |
|---|---|---|
sec-fetch-dest |
script, document, etc. |
Ja, stimmt ueberein |
sec-fetch-mode |
cors, navigate |
Ja, stimmt ueberein |
sec-fetch-site |
same-origin, cross-site |
Ja, stimmt ueberein |
sec-ch-ua (Client Hints) |
Nicht gesendet | Nein, echtes Chrome sendet dies |
| HTTP-Version | HTTP/1.1 | Nein, echtes Chrome verhandelt HTTP/2 oder HTTP/3 |
Zwei Fingerabdruck-Luecken fallen auf: Der Renderer laesst sec-ch-ua Client-Hints-Header vollstaendig weg (ein echter Chrome-Browser sendet diese immer), und alle Anfragen verwenden HTTP/1.1 statt HTTP/2 oder HTTP/3. Wenn Sie Bot-Erkennungsregeln erstellen, sind dies zuverlaessige Signale, um Cloudflares Browser-Renderer von echtem Besucher-Traffic zu unterscheiden.
Wie verhaelt sich Cloudflare /crawl im Vergleich zu anderen KI-Bots in Server-Logs?
Wir haben den Cloudflare-Crawl mit anderen Bots verglichen, die denselben Store im selben 12-Stunden-Fenster getroffen haben:
Amazonbot und ChatGPT-User rufen rohes HTML ab: eine Anfrage, eine Seite, keine JavaScript-Ausfuehrung. AhrefsBot crawlt Sitemaps zur Erkennung. Der Cloudflare Browser-Renderer fuehrt auf jeder Seite eine vollstaendige Shopify-Storefront aus und loest dabei jedes Skript, Pixel und Preload aus, als wuerde ein echter Kunde browsen.
Cloudflare /crawl Geschwindigkeit und Kosten: Der vollstaendige Benchmark
Jeder Crawl, den wir durchgefuehrt haben, in einer Tabelle. Alle Stores anonymisiert, alle Zahlen aus echten Tests. Wall-Clock-Zeiten sind ungefaehr. Erfolgsraten fuer Stores C und D koennten durch eingeschraenkte Fehlerbehandlung in unseren anfaenglichen Testskripten beeinflusst worden sein.
| Store | Seiten | Modus | Erfolgsrate | Browser-Zeit | Wall Clock | Kosten |
|---|---|---|---|---|---|---|
| A: Grosser E-Commerce | 500 / 500 | no-render | 100% | 0s | ~18 Min. | 0 $ |
| B: Mittelgrosse Bekleidung | 256 / 266 | no-render | 96% | 0s | ~5 Min. | 0 $ |
| C: Gesundheit & Nahrungsergaenzung | 89 / 100 | no-render | 89% | 0s | ~3,5 Min. | 0 $ |
| D: Kleiner Shopify | 24 / 24 | render: true | 100% | 58s | ~2 Min. | ~0,002 $ |
| E: Grosser Multi-Kategorie | 1.200 / 1.200 | no-render | 100% | 0s | ~55 Min. | 0 $ |
Wie schnell ist Cloudflare /crawl mit vs. ohne Rendering?
Der klarste Vergleich kommt von Store B, wo wir beide Modi auf exakt denselben 256 Seiten ausgefuehrt haben:
Das Muster ueber alle elf Crawls ist konsistent: Crawling ohne Rendering ist dramatisch schneller. Wall-Clock-Zeit ohne Rendering besteht hauptsaechlich aus Cloudflares internem Warteschlangen- und Abruf-Overhead. Vollstaendiges Rendering fuegt pro Seite etwa 5 Sekunden Browser-Zeit auf dieser Baseline hinzu.
Was kostet ein vollstaendig gerenderter Cloudflare Crawl pro Seite?
Cloudflares Browser-Rendering-Preise basieren auf Browser-Stunden, der Zeit, die ihr Headless-Browser aktiv mit dem Rendern Ihrer Seiten verbringt. Crawling ohne Rendering verbraucht null Browser-Stunden und ist waehrend der Beta kostenlos.
Workers Free Plan: 10 Minuten Browser-Zeit pro Tag. Der /crawl Endpoint ist weiter auf 5 Crawl-Jobs pro Tag begrenzt, mit maximal 100 Seiten pro Crawl.
Workers Paid Plan (5 $/Monat): 10 Stunden Browser-Zeit pro Monat inklusive. Darueber hinaus zahlen Sie 0,09 $ pro zusaetzliche Browser-Stunde. Keine Crawl-Limits beim /crawl Endpoint. Bis zu 600 API-Anfragen pro Minute.
Hier ist, was unsere Test-Crawls tatsaechlich gekostet haben bei 0,09 $/Stunde:
| Crawl | Verbrauchte Browser-Zeit | Kosten bei 0,09 $/Std. |
|---|---|---|
| Store D: 24 Seiten gerendert | 58 Sekunden | ~0,002 $ |
| Store B: 256 Seiten gerendert | 1.338 Sekunden (~22 Min.) | ~0,03 $ |
| 3.000-Seiten-Katalog (geschaetzt) | ~4 Stunden | ~0,36 $ |
Bei etwa 5 Sekunden Browser-Zeit pro Seite liegen all diese Kosten komfortabel innerhalb der 10 im Paid Plan enthaltenen Stunden. Ein 3.000-seitiger gerenderter Crawl wuerde etwa 4 Ihrer 10 enthaltenen Stunden verbrauchen, was bedeutet, dass Sie zwei vollstaendige Crawls pro Monat durchfuehren koennten, bevor Sie ueber die 5 $ Basis hinaus zahlen. Crawling ohne Rendering ist kostenlos und verbraucht auf keinem Plan Browser-Zeit.
Wann sollten Sie Rendering ueberspringen vs. vollstaendiges Rendering bei Cloudflare /crawl verwenden?
Das Fazit
Fuer die meisten Shopify Stores mit servergerendertem Inhalt liefert Crawling ohne Rendering ueber 90% des nuetzlichen Inhalts kostenlos in einem Bruchteil der Zeit.
Was wir beim Testen von Cloudflare /crawl auf Shopify Stores gelernt haben
Nach 11 Crawls ueber 5 Live-Shopify-Stores und der Analyse vollstaendiger Server-Logs sind dies die Erkenntnisse, die am wichtigsten sind.
90% des Inhalts kommen ohne Rendering durch
Fuer Shopify Stores mit standardmaessig servergerenderten Seiten erfasste Crawling ohne JavaScript-Rendering ueber 90% des nuetzlichen Inhalts. Der 14%ige Inhaltsanstieg durch vollstaendiges Rendering stammte fast ausschliesslich von JavaScript-geladenen Elementen auf Startseiten und Index-Seiten. Einzelne Produktseiten und Blog-Artikel waren in beiden Varianten nahezu identisch. Sofern Ihr Store nicht als Single-Page-App gebaut ist, brauchen Sie wahrscheinlich kein vollstaendiges Rendering.
Vollstaendiges Rendering erzeugt einen 89-fachen Traffic-Multiplikator
Das Rendern von 25 Seiten erzeugte 2.234 Server-Anfragen. Nur 25 davon waren tatsaechlicher Seiteninhalt. Die anderen 98,9% waren JavaScript-Dateien (75%), Analytics-Beacons (6,3%), CSS (4,3%), Tracking-Pixel (3,4%) und Checkout-Preloads (3,3%). Jede gerenderte Seite loest den vollstaendigen Shopify-clientseitigen Stack aus, als wuerde ein echter Kunde browsen.
Ihre Shopify-Analytics werden wahrscheinlich verfaelscht
Gerenderte Crawls loesen Shopifys vollstaendigen Analytics-Stack aus: Monorail-Beacons, Tracking-Events, Shop-Pay-Preloads und Web-Pixel-Skripte. Wir glauben, dass Shopify Analytics diese als echte Besuchersitzungen zaehlt. Wenn das der Fall ist, koennte ein einzelner gerenderter Crawl Ihre Sitzungszahlen, Seitenaufrufe und Conversion-Funnel-Daten verfaelschen. Wir haben dies nicht direkt in Shopifys Berichterstattung bestaetigt, aber die Server-Logs zeigen alle dieselben Analytics-Events, die auch fuer einen echten Kunden ausgeloest wuerden.
Vollstaendiges Rendering kann Store-Rate-Limits umgehen
Store D gab bei jeder Seite ohne Rendering 429-Fehler zurueck. Der Wechsel zu vollstaendigem Rendering auf demselben Store ergab 100% Erfolg. Wenn Sie ohne Rendering auf Rate-Limits stossen, ist vollstaendiges Rendering Ihre Loesung.
Sitemap-Erkennung ist zuverlaessiger als Link-Erkennung
Die standardmaessige linkbasierte Erkennung fand auf Store D fast nichts, weil die Startseite nur sehr wenige interne Links hatte. Der Wechsel zur Sitemap-basierten Erkennung fand alle 24 Seiten. Verwenden Sie immer Sitemap-Erkennung.
Der Crawler kommt aus 5 US-Rechenzentren
Cloudflare verteilt die Rendering-Arbeitslast ueber sein Edge-Netzwerk. Unser Crawl kam von 23 einzigartigen IPs ueber Atlanta (38%), Chicago (25%), Miami (23%), Newark (9%) und Washington DC (5%). Alle IPs liegen im 104.28.x.x-Bereich.
Zwei Fingerabdruck-Luecken identifizieren ihn als Bot
Der Renderer laesst sec-ch-ua Client-Hints-Header weg (echtes Chrome sendet diese immer) und verwendet HTTP/1.1 statt HTTP/2 oder HTTP/3. Wenn Sie Bot-Erkennungsregeln erstellen, sind dies zuverlaessige Signale.
Rendering kann tatsaechlich weniger Inhalt zurueckgeben
Bei Store E gab der No-Render-Crawl 6,8% mehr Inhalt pro Seite zurueck als der gerenderte Crawl. Das Blockieren von Bildern, Fonts und Stylesheets zur Optimierung der Browser-Zeit verhinderte auch, dass einiges an JavaScript dynamische Elemente befuellte. Das statische HTML hatte bereits alles. Fuer servergerenderte Shopify Stores ist Rendering nicht garantiert, mehr Inhalt zu erfassen.
Resource-Blocking verhindert haengende Crawls
Ohne Resource-Blocking hing der gerenderte Crawl bei Store E bei 99 von 100 Seiten und wurde nie abgeschlossen. Das Aktivieren von Blocking fuer Bilder, Medien, Fonts und Stylesheets mit einer domcontentloaded-Wartebedingung schloss alle 100 Seiten ab und reduzierte die Browser-Zeit um 27%. Wenn Ihre gerenderten Crawls vor dem Abschluss stocken, ist Resource-Blocking die Loesung.
robots.txt Crawl-Delay verlaengert die Wall-Clock-Zeit
Die robots.txt von Store E gibt einen 10-Sekunden-Crawl-Delay an. In unseren No-Render-Polling-Daten zeigte sich dies als mehrminuetige Plateaus, bei denen die Seitenzahl stagnierte, bevor sie wieder anstieg. Der Cloudflare-Crawler respektiert Crawl-Delay-Direktiven, daher werden Websites mit aggressiven Verzoegerungen deutlich laengere Wall-Clock-Zeiten haben, als die Seitenzahl allein vermuten liesse.
Kosten sind niedrig, aber der Free Plan hat Limits
Das Rendern von 256 Seiten kostete etwa 0,03 $ bei 0,09 $ pro Browser-Stunde. Das Rendern von 24 Seiten kostete etwa 0,002 $. Der Workers Free Plan begrenzt die Browser-Zeit auf 10 Minuten pro Tag mit maximal 5 Crawl-Jobs und 100 Seiten pro Crawl. Der Workers Paid Plan (5 $/Monat) umfasst 10 Stunden Browser-Zeit pro Monat ohne Crawl-Limits. Ein 3.000-seitiger gerenderter Crawl wuerde etwa 4 dieser 10 enthaltenen Stunden verbrauchen, sodass die meisten Stores bequem in den Paid Plan passen, ohne Mehrkosten. Crawling ohne Rendering verbraucht null Browser-Zeit und ist waehrend der Beta auf beiden Plaenen kostenlos.
Die Vorteile
Geschwindigkeit
Seiten werden nahezu sofort abgerufen, im Vergleich zu einem mehrstuendigen Scrapy-Crawl mit Autothrottle. Kein Warten in der Warteschlange, keine Hoeflichkeitsverzoegerungen, kein Warten, bis Ihr Spider Tausende von Anfragen in einem respektvollen Tempo abarbeitet.
Markdown-Ausgabe
Der Endpoint gibt fuer jede Seite vorkonvertiertes HTML-zu-Markdown zurueck. Dies ist direkt nuetzlich fuer LLM-Ingestion, RAG-Pipelines und Content-Analyse ohne jegliche Nachbearbeitung. Sie ueberspringen die gesamte Extraktionsschicht und gelangen direkt zu sauberem Text. Fuer Teams, die KI-Anwendungen auf Basis von Website-Inhalten erstellen, entfaellt damit ein Schritt in der Pipeline.
Render-Modus-Option
Das Setzen von render: true fuehrt JavaScript aus und extrahiert automatisch Open-Graph-Metadaten (og:title, og:description, og:image, og:site_name). Fuer JavaScript-lastige Websites, auf denen Inhalte clientseitig gerendert werden, ist dies der Unterschied zwischen dem Sehen der echten Seite und einer leeren Huelle.
Keine Proxy- oder Rate-Limit-Probleme
Cloudflare kuemmert sich um Anti-Bot-Massnahmen und Rate-Limiting auf ihrer eigenen Infrastruktur. Sie muessen keine Proxy-Pools verwalten, User-Agents rotieren oder sich mit CAPTCHAs befassen. Ein API-Aufruf.
Inkrementelles Crawling
Die Parameter modifiedSince und maxAge ermoeglichten es, Seiten zu ueberspringen, die sich nicht geaendert haben oder kuerzlich abgerufen wurden. Fuer wiederkehrende Crawls, bei denen Sie Inhaltsaenderungen ueberwachen, spart dies sowohl Zeit als auch Kosten, da nur tatsaechlich neue oder aktualisierte Seiten verarbeitet werden.
Einfachheit
Ein einziger API-Aufruf. JSON-Antwort. Kein Spider-Code, keine Middleware, keine Item-Pipelines, keine Settings-Dateien.
Gut erzogener Bot als Standard
Der Crawler ist ein signierter Agent, der robots.txt, crawl-delay und Cloudflares AI Crawl Control respektiert. Er identifiziert sich als CloudflareBrowserRenderingCrawler/1.0 und kann Bot-Schutz oder CAPTCHAs nicht umgehen. Sie erhalten ethische Crawling-Compliance, ohne die Logik selbst bauen zu muessen.
Was der Cloudflare Crawl Endpoint nicht unterstuetzt
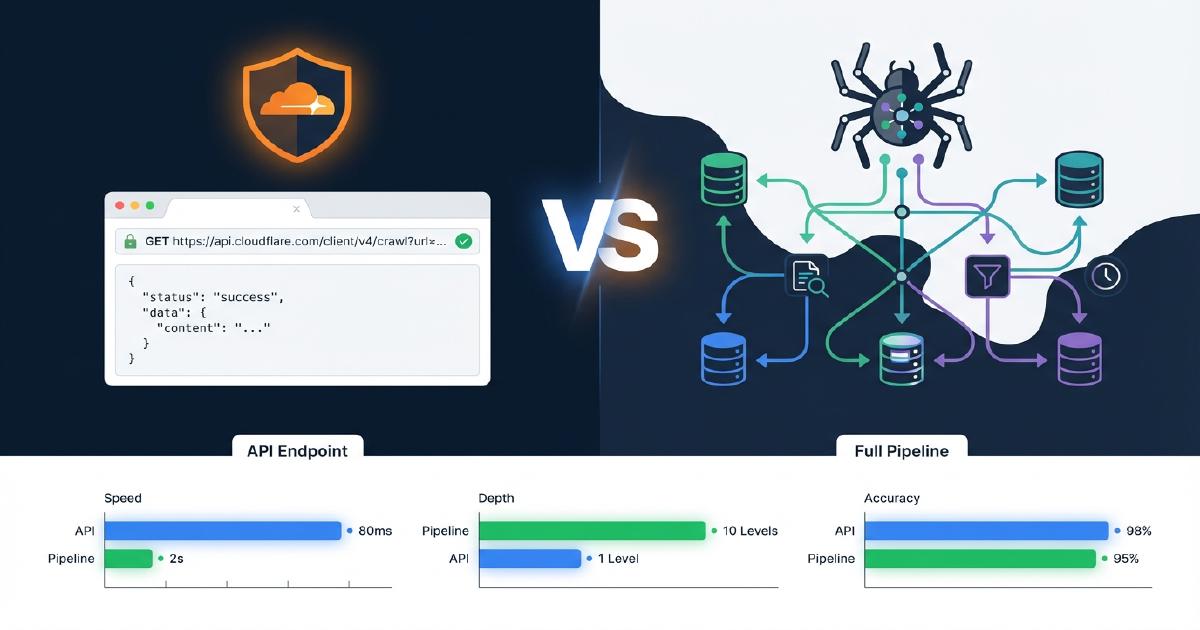
Wie unterscheidet sich Cloudflare /crawl von einer vollstaendigen Crawl-Pipeline?
Die folgende Tabelle zeigt genau, welche Faehigkeiten im Cloudflare /crawl Endpoint vorhanden sind im Vergleich zu einer Produktions-Scrapy-Pipeline. Dies basiert auf unseren echten Tests gegen Shopify Stores.
| Faehigkeit | Cloudflare /crawl | Scrapy-Pipeline |
|---|---|---|
| Content-Abruf (HTML/Markdown) | Ja | Ja |
| JavaScript-Rendering | Ja (render: true) |
Ja (Splash/Playwright) |
| Link-Erkennung / Spidering | Ja (flache Liste) | Ja (vollstaendiger Crawl-Graph) |
| Eltern-Kind-Link-Zuordnung | Nein | Ja |
| Verwaiste Seitenerkennung | Nein | Ja |
| Redirect-Chain-Tracking | Nein | Ja |
| JSON-LD-Extraktion | Nein | Ja |
| Microdata-Extraktion | Nein | Ja |
| Schema-Validierung + Problemberichterstattung | Nein | Ja |
| Nicht-200-Statuscodes (404s, 403s) | Nein | Ja (2.547 404s in unserem Test erfasst) |
| URL-Limit | 100.000 | Keins |
Welche strukturierten Daten extrahiert Cloudflare /crawl?
Mit render: false, keine. Kein JSON-LD, kein Microdata, kein OpenGraph-Parsing.
Mit render: true, nur grundlegende OG-Tags (og:title, og:description, og:image, og:site_name). JSON-LD und schema.org-Markup werden nicht geparst, extrahiert oder validiert.
Zum Vergleich: Unsere Scrapy-Pipeline erzeugt schemas_found, issues (fehlende contactPoint, address usw.), top_level_schemas und nested_schemas fuer jede URL. Sie koennen sehen, welche Seiten Product-Schema haben, welchen Organization-Markup fehlt und welche Validierungsfehler haben, die dazu fuehren wuerden, dass KI-Systeme den Inhalt falsch lesen.
Welche HTTP-Statuscodes gibt Cloudflare /crawl zurueck?
Nur 200-Antworten. Unser Scrapy-Crawl derselben Website erfasste 2.547 404-Fehler plus 403-Antworten und Verbindungsfehler. Die 404-Erkennung ist entscheidend fuer Ghost-Page-Analyse, Broken-Link-Behebung und Redirect-Mapping. Ohne sie uebersehen Sie die Seiten, die aktiv Link-Equity verlieren und KI-Crawler verwirren.
Wie viele URLs kann Cloudflare /crawl verarbeiten?
Bis zu 100.000 pro Job. Das deckt die meisten Websites ab, aber grosse E-Commerce-Kataloge mit Hunderttausenden von Produktseiten, Varianten-URLs und gefilterten Kollektionsseiten werden das Limit ueberschreiten. Scrapy hat kein inherentes URL-Limit.
Hat Cloudflare /crawl einen URL-Aufloesungsfehler?
Wir fanden 233 von 908 Links auf einer einzelnen Produktseite mit fehlerhaften Pfaden. Der Markdown-Converter loest relative URLs falsch gegen die Seiten-URL auf und erzeugt Doppelpfad-URLs wie /products/slug//www.example.com/.... Dies ist ein bestaetigter Fehler in Cloudflares Converter, der jede nachgelagerte Link-Analyse betrifft.
Wie viel Boilerplate steckt in der Cloudflare /crawl Markdown-Ausgabe?
Die durchschnittliche Seite gab 158 KB Markdown zurueck. Etwa 90% davon ist wiederholter Template-Inhalt: vollstaendige Navigation, Mega-Menue und Footer in jedem einzelnen Datensatz. Fuer Content-Analyse bedeutet das umfangreiche Deduplizierungsarbeit, und fuer LLM-Token-Nutzung summieren sich die Kosten schnell. Sie benoetigen Ihre eigene Content-Extraktionslogik auf dem Markdown, um den tatsaechlichen Seiteninhalt zu isolieren.
Was klassifiziert Cloudflare /crawl nicht?
Es gibt kein Inhaltstyp-Tagging. Produktseiten, Kollektionsseiten, Blog-Beitraege und Startseiten kommen alle als undifferenzierte Datensaetze zurueck. Scrapy klassifiziert jede URL nach Typ, was essentiell ist, um die Crawl-Abdeckung nach Seitenkategorie zu verstehen und zu identifizieren, welche Inhaltstypen KI-Bots priorisieren.
Welche Finalisierungsfunktionen fehlen bei Cloudflare /crawl?
Keine Ghost-Page-Screenshots. Kein JavaScript-Rendering-Vergleich (was der Bot sieht versus was der Browser sieht). Keine robots.txt-KI-Bot-Analyse. Kein Crawl-Qualitaetsbericht. Kein Client-Manifest. Keine CDN-Synchronisierung. Die Cloudflare-Daten sind nur Rohinhalte. Jedes Stueck der Reporting- und Analyse-Pipeline muesste separat gebaut werden.
Was kostet Cloudflare /crawl fuer grosse Websites?
In unseren Tests benoetigte render: true im Durchschnitt etwa 5 Sekunden Browser-Ausfuehrungszeit pro Seite. Ein 256-Seiten-Crawl verbrauchte 1.338 Browser-Sekunden (22 Minuten) und kostete etwa 0,03 $ bei 0,09 $ pro Browser-Stunde. Ein 24-Seiten-Crawl verbrauchte 58 Browser-Sekunden und kostete etwa 0,002 $. Hochgerechnet auf einen 3.000-Seiten-Katalog: etwa 4 Stunden Browser-Zeit. Der Workers Free Plan ist auf 10 Minuten Browser-Zeit pro Tag, 5 Crawl-Jobs pro Tag und 100 Seiten pro Crawl begrenzt. Der Workers Paid Plan (5 $/Monat) umfasst 10 Stunden Browser-Zeit pro Monat ohne Crawl-Limits, sodass ein 3.000-Seiten-Crawl etwa 4 dieser 10 enthaltenen Stunden verbrauchen wuerde. render: false verbraucht null Browser-Zeit und ist waehrend der Beta auf beiden Plaenen kostenlos.
Das Fazit
Cloudflares Crawl Endpoint ist hervorragend fuer:
- Schnelle Content-Snapshots, wenn Sie Seitentext schnell benoetigen
- LLM-bereites Markdown fuer RAG-Pipelines und Content-Ingestion
- Ad-hoc-Seitenpruefungen, wenn Sie die genauen URLs kennen, die Sie brauchen
- Schnelle seitenweite Content-Abrufe, wenn Sie Markdown-Text benoetigen, ohne einen Spider zu bauen
Er kann eine vollstaendige Crawl-Pipeline nicht ersetzen, weil der Wert der Pipeline liegt in:
- Vollstaendigem Crawl-Graphen mit Link-Topologie, Verwaiste-Seiten-Erkennung und 404-Abdeckung
- Extraktion und Validierung strukturierter Daten (JSON-LD, Microdata, OpenGraph)
- Content-Klassifizierung nach Seitentyp
- Der gesamten Finalisierungs-Pipeline einschliesslich Ghost-Page-Analyse, JavaScript-Rendering-Vergleich, Schema-Reports und LLM-Readiness-Scoring
Der beste hybride Ansatz
Verwenden Sie Cloudflare als ergaenzende Datenquelle. Nachdem ein vollstaendiger Crawl Ihre URLs identifiziert hat, verwenden Sie Cloudflares Markdown-Ausgabe, um LLM-Readiness-Scoring oder Content-Qualitaetsanalyse zu speisen, wo Sie den tatsaechlichen Seitentext statt strukturierter Metadaten benoetigen. Die Crawl-Pipeline entdeckt und klassifiziert. Der Cloudflare Endpoint liefert sauberen Text fuer die Seiten, die wichtig sind.
Moechten Sie die vollstaendige Crawl-Pipeline in Aktion sehen?
Gespraech vereinbarenHaeufig gestellte Fragen
Welche Website-Audit-Funktionen werden von Cloudflare /crawl nicht unterstuetzt?
Cloudflare /crawl unterstuetzt nicht: vollstaendige Crawl-Graph-Erstellung, Eltern-Kind-Link-Zuordnung, verwaiste Seitenerkennung, Redirect-Chain-Tracking, JSON-LD- oder Microdata-Extraktion, Schema-Validierung, Erfassung von Nicht-200-Statuscodes (404s, 403s), Inhaltstyp-Klassifizierung, Seitengroessenmessung in Bytes, Ghost-Page-Erkennung, JS-vs-HTML-Rendering-Vergleich, robots.txt-KI-Bot-Analyse oder Backlink-Querverweise. Es ist ein Content-Fetcher, kein Site-Audit-Tool.
Wie unterscheidet sich Cloudflare /crawl von Scrapy fuer E-Commerce-Crawling?
Cloudflare /crawl ruft Inhalte schnell ab, ohne dass eine Infrastruktur verwaltet werden muss. Scrapy erstellt einen vollstaendigen Crawl-Graphen mit Link-Topologie, extrahiert und validiert strukturierte Daten (JSON-LD, Microdata, OpenGraph), erfasst alle HTTP-Statuscodes einschliesslich 404s, klassifiziert Seiten nach Inhaltstyp und speist eine nachgelagerte Pipeline fuer Ghost-Page-Analyse, Schema-Reports und LLM-Readiness-Scoring. Cloudflare liefert den Seitentext; Scrapy liefert die vollstaendige Site-Architektur.
Was ist das genaue URL-Limit fuer Cloudflare /crawl?
100.000 URLs pro Crawl-Job. Das Standard-limit ist 10, daher muessen Sie es explizit festlegen. Die maximale depth betraegt ebenfalls 100.000. Fuer Websites mit mehr als 100K Seiten wird Scrapy oder ein anderer Crawler ohne inherentes URL-Limit benoetigt.
Extrahiert Cloudflare /crawl JSON-LD oder validiert Schema-Markup?
Nein. Mit render: false werden keine strukturierten Daten extrahiert. Mit render: true werden nur grundlegende Open-Graph-Tags zurueckgegeben (og:title, og:description, og:image, og:site_name). JSON-LD, Microdata und schema.org-Markup werden in keinem der beiden Modi geparst, extrahiert oder validiert.
Was kostet Cloudflare /crawl fuer das Rendering grosser Websites?
In unseren Tests benoetigte render: true im Durchschnitt etwa 5 Sekunden Browser-Zeit pro Seite. Eine 256-Seiten-Website verbrauchte 1.338 Browser-Sekunden (22 Minuten) und kostete etwa 0,03 $ bei 0,09 $ pro Browser-Stunde. Eine 24-Seiten-Website verbrauchte 58 Sekunden und kostete etwa 0,002 $. Hochgerechnet auf einen 3.000-Seiten-Katalog: etwa 4 Stunden Browser-Zeit. Der Workers Free Plan ist auf 10 Minuten pro Tag, 5 Crawl-Jobs pro Tag und 100 Seiten pro Crawl begrenzt, daher erfordern grosse gerenderte Crawls den Workers Paid Plan (5 $/Monat), der 10 Stunden Browser-Zeit pro Monat ohne Crawl-Limits umfasst. render: false verbraucht null Browser-Zeit und ist waehrend der Beta auf beiden Plaenen kostenlos.
Hat Cloudflare /crawl einen bekannten URL-Aufloesungsfehler?
Ja. In unserem Test hatten 233 von 908 Links auf einer einzelnen Produktseite fehlerhafte Pfade. Der Markdown-Converter stellt die Seiten-URL relativen Pfaden wie //www.example.com/cdn/... voran und erzeugt so fehlerhafte Doppelpfad-URLs. Dies betrifft jede nachgelagerte Link-Graph-Analyse oder interne Linking-Pruefung, die auf der Markdown-Ausgabe basiert.
Warum gibt Cloudflare /crawl mit render false bei einigen Shopify Stores 429-Fehler zurueck?
render: false fuehrt einen rohen HTML-Abruf ohne Headless-Browser durch. In einem unserer Tests gab render: false 429-Fehler zurueck, waehrend render: true mit 100% Erfolg auf demselben Store funktionierte. Wir haben dies nicht erneut mit verbesserter Fehlerbehandlung getestet, daher koennten die 429er durch das Rate-Limiting des Stores, voruebergehende API-Probleme oder eine Kombination verursacht worden sein. Wenn Sie 429-Fehler ohne Rendering sehen, versuchen Sie als ersten Schritt render: true.
Akzeptiert Cloudflare /crawl eine Liste von URLs?
Nein. Der Endpoint nimmt eine einzelne Start-URL entgegen und entdeckt Seiten durch Spidering ueber Sitemaps, Seitenlinks oder beides. Wenn Sie bereits eine URL-Liste haben und Cloudflares Markdown-Konvertierung nutzen moechten, verwenden Sie die separaten /markdown- oder /scrape-Endpoints, die einzelne URLs pro Anfrage akzeptieren.
Warum findet Cloudflare /crawl mit source all auf manchen Websites nur eine Seite?
Das Standard-source: all entdeckt URLs sowohl aus Sitemaps als auch aus Seitenlinks. Wenn die Start-URL sehr wenige interne Links hat (ueblich bei minimalen Startseiten oder JavaScript-lastigen SPAs), findet der Crawler moeglicherweise keine zusaetzlichen Seiten allein durch Link-Erkennung. Wechseln Sie zu source: sitemaps, um sicherzustellen, dass der Crawler die vollstaendige sitemap.xml liest und alle gelisteten URLs entdeckt.
Wie nutzt man Cloudflare /crawl am besten mit einer vollstaendigen Crawl-Pipeline?
Verwenden Sie zuerst die vollstaendige Crawl-Pipeline (Scrapy oder Aequivalent), um URLs zu entdecken, den Link-Graphen aufzubauen, strukturierte Daten zu extrahieren, 404s zu erfassen und Inhalte zu klassifizieren. Verwenden Sie dann Cloudflares /markdown- oder /scrape-Endpoints, um sauberes Markdown fuer LLM-Readiness-Scoring, Content-Qualitaetsanalyse oder RAG-Ingestion abzurufen, wo Sie den tatsaechlichen Seitentext statt strukturierter Metadaten benoetigen.
Wie viel schneller ist Cloudflare /crawl mit render false im Vergleich zu render true?
In unserem direkten Vergleich auf derselben 256-Seiten-Website wurde render: false in etwa 5 Minuten abgeschlossen. render: true benoetigte etwa 25 Minuten fuer dieselben Seiten. Das ist ein 5-facher Geschwindigkeitsunterschied. Die Wall-Clock-Differenz ergibt sich aus etwa 5 Sekunden Browser-Ausfuehrungszeit, die pro Seite hinzukommen, wenn Rendering aktiviert ist. render: false kostete waehrend der Beta 0 $. render: true kostete etwa 0,03 $ fuer denselben Crawl.
Wie viel zusaetzlichen Inhalt erfasst Cloudflare /crawl mit render true im Vergleich zu render false?
In unserem 256-Seiten-Test erzeugte render: true 12,5 MB Markdown gegenueber 11,0 MB von render: false, ein Anstieg von 14%. Der zusaetzliche Inhalt stammte fast ausschliesslich von JavaScript-geladenen Elementen auf der Startseite und Blog-Index-Seiten. Einzelne Produktseiten und Blog-Artikel waren zwischen den Modi nahezu identisch. Fuer Websites mit ueberwiegend servergerendertem Inhalt erfasst render: false ueber 90% des nuetzlichen Texts bei null Kosten und 5-facher Geschwindigkeit.
Funktioniert Cloudflare /crawl zuverlaessig auf allen Shopify Stores?
Das haengt vom Store und dem Render-Modus ab. In unseren Tests ueber fuenf Shopify Stores: Store A (grosser Katalog) erreichte 100% Erfolg mit render: false. Store B (mittelgrosse Bekleidung) erreichte 96% Erfolg mit beiden Modi. Store C (Gesundheit und Nahrungsergaenzung) erreichte 40% bei einer 5-Seiten-Stichprobe und 89% bei einem 100-Seiten-Crawl mit render: false, wobei unser erster Test keine robuste Fehlerbehebung hatte und einige Fehlschlaege behebbar gewesen sein koennten. Store D (kleiner Store) gab 429-Fehler mit render: false zurueck, erreichte aber 100% mit render: true. Store E (grosser Multi-Kategorie, ~1.200 Seiten) erreichte 100% Erfolg mit render: false und 100% bei einer 100-seitigen gerenderten Stichprobe mit Resource-Blocking-Optimierungen. Wir haben die Stores C und D nicht erneut mit verbesserter Fehlerbehandlung getestet. Testen Sie beide Modi auf Ihrem spezifischen Store, bevor Sie sich auf eine Crawl-Strategie festlegen.
Wie lang ist die Wall-Clock-Zeit fuer einen 500-seitigen Cloudflare /crawl mit render false?
In unserem Test wurde ein 500-seitiger render: false Crawl in etwa 18 Minuten mit einer 100%igen Erfolgsrate abgeschlossen. Ein 256-seitiger Crawl auf einem anderen Store wurde in etwa 5 Minuten abgeschlossen. Ein 100-seitiger Crawl wurde in etwa 3,5 Minuten abgeschlossen. Diese Wall-Clock-Zeiten sind Schaetzungen basierend auf Polling-Intervallen, keine praezisen Messungen. Die Wall-Clock-Zeit besteht hauptsaechlich aus Cloudflares internem Warteschlangen- und HTTP-Abruf-Overhead, nicht aus Browser-Rendering, da mit render: false keine Browser-Sekunden verbraucht werden.
Wie viele Server-Anfragen erzeugt ein Cloudflare /crawl mit render true?
In unserer Server-Log-Analyse erzeugte ein einzelner render: true Crawl von 25 Seiten 2.234 Gesamtanfragen: 2.071 GETs und 163 POSTs. Das sind etwa 89 Server-Anfragen pro tatsaechlich gerenderter Seite. Nur 1,1% der Anfragen waren tatsaechlicher Seiteninhalt. Die restlichen 98,9% waren JavaScript-Dateien (75%), Analytics-Beacons (6,3%), CSS (4,3%), Tracking-Pixel (3,4%) und Checkout-Preloads (3,3%). Wenn Sie Bot-Traffic ueberwachen oder Serverlast verwalten, erwarten Sie, dass ein gerenderter Crawl 89-mal so viele Anfragen wie die tatsaechlichen Seitenaufrufe in Ihren Server-Logs erzeugt.
Welchen User-Agent verwendet Cloudflare /crawl und aus welchem IP-Bereich kommt es?
Der Crawler identifiziert sich als CloudflareBrowserRenderingCrawler/1.0 bei 100% der Anfragen. In unseren Logs kamen alle Anfragen von 23 einzigartigen IPs im 104.28.x.x-Bereich, verteilt auf 5 US-Cloudflare-Rechenzentren: ATL (38%), ORD (25%), MIA (23%), EWR (9%) und IAD (5%). Es gibt keine User-Agent-Rotation oder IP-Verschleierung. Der Crawler ist ein signierter, identifizierbarer Bot von Design her.
Verfaelscht Cloudflare /crawl Shopify-Analytics und Besucherzahlen?
Wir glauben ja, haben es aber nicht direkt in Shopifys Berichterstattung bestaetigt. Da render: true JavaScript ausfuehrt, loest es Shopifys vollstaendigen Analytics-Stack auf jeder Seite aus: Monorail-Beacons, /api/collect-Tracking-Events, Shop-Pay-Checkout-Preloads und Web-Pixel-Sandbox-Skripte. In unserem Test waren 163 von 2.234 Anfragen POST-Anfragen an Shopify-Analytics-Endpoints. Dies sind dieselben Events, die fuer echte Kunden ausgeloest werden. Wenn Shopify diese als echte Sitzungen zaehlt, wuerden Ihre Sitzungszahlen, Seitenaufrufe und Conversion-Funnel-Daten verfaelscht.
Wie erkennt man Cloudflare /crawl in Server-Logs im Vergleich zu echtem Browser-Traffic?
Zwei zuverlaessige Fingerabdruck-Luecken: Cloudflares Browser-Renderer laesst sec-ch-ua Client-Hints-Header weg (ein echter Chrome-Browser sendet diese immer), und alle Anfragen verwenden HTTP/1.1 statt HTTP/2 oder HTTP/3, die ein echter Browser aushandeln wuerde. Er sendet korrekte sec-fetch-dest-, sec-fetch-mode- und sec-fetch-site-Header, die echtem Chrome entsprechen. Der User-Agent ist immer CloudflareBrowserRenderingCrawler/1.0 und alle IPs liegen im 104.28.x.x-Bereich.