
O Que E o Endpoint /crawl da Cloudflare?
O endpoint /crawl da Cloudflare faz parte da API de Browser Rendering, atualmente em beta aberto. Ele raspa conteudo de uma URL inicial, segue links pelo site ate um limite configuravel de profundidade ou paginas, e retorna os resultados como HTML, Markdown ou JSON estruturado alimentado por Workers AI. A Cloudflare o posiciona como uma ferramenta para treinar modelos, construir pipelines RAG e pesquisar ou monitorar conteudo em um site.
O endpoint opera como um agente assinado que respeita o robots.txt e o AI Crawl Control da Cloudflare por padrao, o que e uma escolha de design notavel. E projetado para facilitar que os desenvolvedores cumpram as regras dos sites e dificultar que rastreadores ignorem as orientacoes dos proprietarios.
O endpoint esta localizado em:
https://api.cloudflare.com/client/v4/accounts/<account_id>/browser-rendering/crawl
Voce precisa de um token de API da Cloudflare com permissao Browser Rendering Edit para usa-lo.
Como Funciona
O rastreamento e executado como um trabalho assincrono em duas etapas:
- Inicie o rastreamento com uma requisicao POST contendo uma URL inicial. A API retorna um ID de trabalho imediatamente.
- Consulte os resultados com requisicoes GET usando esse ID de trabalho. Quando o status do trabalho muda de
runningparacompleted, seus dados rastreados estao prontos.
Os trabalhos podem ser executados por ate sete dias. Os resultados sao armazenados por 14 dias apos a conclusao.
O Que Voce Envia
No minimo, voce envia uma URL:
curl -X POST 'https://api.cloudflare.com/client/v4/accounts/{account_id}/browser-rendering/crawl' \
-H 'Authorization: Bearer <apiToken>' \
-H 'Content-Type: application/json' \
-d '{
"url": "https://example.com"
}'
Parametros Principais
| Parametro | Padrao | O Que Faz |
|---|---|---|
limit |
10 | Max de paginas para rastrear (ate 100.000) |
depth |
100.000 | Profundidade maxima de links a partir da URL inicial |
source |
all |
Onde descobrir URLs: all, sitemaps ou links |
formats |
HTML | Formato de resposta: html, markdown ou json |
render |
true | Executar JavaScript (true) ou busca rapida de HTML (false) |
maxAge |
86.400 | TTL do cache em segundos (max 604.800) |
modifiedSince |
nenhum | Timestamp Unix: rastrear apenas paginas modificadas apos este momento |
options.includePatterns |
nenhum | Rastrear apenas URLs que correspondam a esses padroes wildcard |
options.excludePatterns |
nenhum | Pular URLs que correspondam a esses padroes |
O Que Voce Recebe de Volta
Cada pagina rastreada retorna como um registro com a URL, status, conteudo no formato escolhido e metadados basicos (codigo de status HTTP, titulo da pagina, URL final apos redirecionamentos). Com render: true, voce tambem recebe tags Open Graph. A resposta tambem inclui browserSecondsUsed para visibilidade de faturamento, e um cursor para paginar resultados que excedem 10 MB.
Aqui esta a resposta real em nivel de trabalho de um rastreamento renderizado de 24 paginas de uma loja Shopify real:
{
"job_id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890",
"status": "completed",
"total": 24,
"finished": 24,
"browserSecondsUsed": 58.38,
"record_count": 24,
"records": [
{
"url": "https://www.example-store.com/products/premium-widget-bundle",
"status": "completed",
"metadata": {
"status": 200,
"title": "Premium Widget Bundle | Example Store",
"url": "https://www.example-store.com/products/premium-widget-bundle",
"lastModified": "",
"og:type": "product",
"og:site_name": "Example Store",
"og:title": "Premium Widget Bundle | Example Store",
"og:image": "https://www.example-store.com/cdn/shop/files/product-image.jpg",
"og:description": "Our best-selling bundle with everything you need..."
},
"markdown": "Store\n\nexample-store\n\nURL\n\nhttps://www.example-store.com\n\nCurrency\n\nUSD\n\n# Premium Widget Bundle\n\nOur best-selling bundle with everything you need..."
}
]
}
Com render: true, o objeto de metadados inclui o conjunto completo de campos Open Graph: type, site name, title, image URL e description. Estes sao extraidos das meta tags OG da pagina durante a renderizacao do navegador. Com render: false, os metadados contem apenas o codigo de status HTTP, titulo da pagina e URL final. Nenhum campo Open Graph e extraido.
O campo markdown contem toda a saida da pagina, nao apenas o conteudo principal. Menus de navegacao, mega menus, rodapes e blocos de template repetidos estao todos incluidos em cada registro. Em nossos testes, a pagina media retornou aproximadamente 158 KB de markdown, com cerca de 90% sendo boilerplate repetido. Se voce esta alimentando isso em um LLM ou pipeline RAG, precisara de sua propria logica de extracao de conteudo para remover o template e isolar o conteudo real da pagina.
Aqui esta o que a mesma loja retornou quando executamos render: false:
{
"job_id": "f9e8d7c6-b5a4-3210-fedc-ba9876543210",
"status": "completed",
"total": 266,
"finished": 266,
"browserSecondsUsed": 0,
"record_count": 256,
"records": [
{
"url": "https://www.example-store.com/products/classic-knit-sweater",
"status": "completed",
"metadata": {
"status": 200,
"title": "Classic Knit Sweater | Example Store",
"url": "https://www.example-store.com/products/classic-knit-sweater",
"lastModified": ""
},
"markdown": "Skip to content\n\nFree Shipping $150+\n\n# Classic Knit Sweater\n\nOur best-selling sweater made from premium natural fibers..."
}
]
}
Zero segundos de navegador, 256 registros de 266 paginas. Os metadados sao minimos comparados a versao renderizada: sem campos Open Graph, apenas o status HTTP, titulo da pagina e URL. Mas o markdown ainda contem o conteudo completo da pagina incluindo navegacao, detalhes do produto e rodape. Para lojas Shopify renderizadas no servidor, o HTML estatico ja tem tudo o que voce precisa.
Descoberta de URLs
O rastreador descobre URLs atraves de tres fontes (quando source esta definido como all):
- A URL inicial que voce fornece
- Links de sitemap encontrados no dominio
- Links internos encontrados nas paginas rastreadas
Voce pode restringir isso apenas a sitemaps ou apenas a links de pagina usando o parametro source. excludePatterns sempre tem prioridade sobre includePatterns, para que voce possa lancar uma rede ampla e depois recortar secoes que nao precisa.
Renderizacao vs. Busca Rapida
render: true (o padrao) inicia um navegador headless, executa JavaScript e aguarda a pagina carregar completamente. Isso e necessario para aplicacoes de pagina unica e conteudo renderizado por JavaScript, mas usa segundos de navegador que sao cobrados.
render: false faz uma busca rapida de HTML sem executar JavaScript. Durante o beta, essas buscas nao sao cobradas. Esta e a escolha certa para sites estaticos ou paginas renderizadas no servidor onde o conteudo ja esta no HTML inicial.
Faturamento e Disponibilidade
O endpoint esta disponivel nos planos Workers Free e Paid. Rastreamentos renderizados sao cobrados sob o preco de Browser Rendering da Cloudflare a $0,09 por hora de navegador alem da sua alocacao inclusa.
Workers Free: 10 minutos de tempo de navegador por dia. O endpoint /crawl e limitado a 5 trabalhos por dia, 100 paginas por rastreamento e 6 requisicoes de API por minuto.
Workers Paid ($5/mes): 10 horas de tempo de navegador por mes incluidas. Sem limites por rastreamento. 600 requisicoes de API por minuto. Horas adicionais de navegador custam $0,09 cada.
Rastreamentos render: false usam zero tempo de navegador. Sao gratuitos durante o beta, mas eventualmente cairao sob o preco padrao do Workers.
O Que E Tempo Real (Wall Clock Time)?
Tempo real e o tempo total decorrido desde quando um rastreamento comeca ate quando termina, medido da mesma forma que voce mediria com um cronometro. Inclui tudo: latencia de rede, tempo de fila interna da Cloudflare, consultas DNS, tempo de resposta do servidor e (se a renderizacao estiver ativada) tempo de execucao do navegador.
Tempo real e diferente de tempo de navegador. Tempo de navegador conta apenas os segundos que o navegador headless da Cloudflare gasta renderizando paginas ativamente. Um rastreamento pode usar 22 minutos de tempo de navegador mas levar 25 minutos de tempo real por causa de overhead de fila e rede. Rastreamentos sem renderizacao usam zero tempo de navegador mas ainda tem tempo real do processo de busca e fila.
Em nossos benchmarks, relatamos ambos os numeros para que voce possa ver pelo que esta pagando (tempo de navegador) versus quanto tempo realmente esta esperando (tempo real).
As Letras Miudas
O endpoint respeita diretivas do robots.txt incluindo crawl-delay. Ele se identifica como CloudflareBrowserRenderingCrawler/1.0. Nao contorna CAPTCHAs, desafios Turnstile ou outra protecao contra bots. Se voce esta rastreando seu proprio site e sendo bloqueado, precisa criar uma regra de skip do WAF para permitir o rastreador.
Como o Cloudflare /crawl se Comporta em Cinco Lojas Shopify
Executamos o endpoint /crawl contra cinco lojas Shopify reais para medir velocidade, taxa de sucesso, custo e como o rastreador interage com cada site. Todos os nomes de lojas sao anonimizados. Estes sao numeros reais de rastreamentos reais. Tempos reais sao estimativas aproximadas. Alguns testes iniciais usaram scripts com tratamento de erros limitado, o que pode ter afetado as taxas de sucesso relatadas em certas lojas. Onde isso se aplica, indicamos abaixo.
Este nao e um endpoint do tipo configure-e-esqueca. Cada loja respondeu de forma diferente as requisicoes do endpoint. Algumas precisaram de bloqueio de recursos para completar um rastreamento renderizado. Outras retornaram erros 429 em um modo mas funcionaram bem no outro. Diretivas de crawl-delay, contagem de paginas e arquitetura da loja mudaram o resultado. Planeje testar e ajustar as configuracoes para cada site que rastrear.
Teste 1: Catalogo Grande de E-Commerce (Store A)
Apontamos o endpoint /crawl para uma loja Shopify grande com quase 3.000 paginas. O conteudo voltou rapido, o markdown era utilizavel e o endpoint nao teve problemas para buscar paginas de produtos, paginas de colecoes e conteudo de blog. Sem problemas de proxy, sem bloqueios, sem rate limiting.
Executamos multiplos rastreamentos em diferentes escalas:
| Tamanho do Rastreamento | Paginas Retornadas | Modo | Tempo de Navegador | Tempo Real |
|---|---|---|---|---|
| Amostra de 20 paginas | 20 / 20 (100%) | no-render | 0s | ~1 min |
| Rastreamento de 500 paginas | 500 / 500 (100%) | no-render | 0s | ~18 min |
| 5 paginas renderizadas | 4 / 5 (80%) | render: true | 0.9s | ~10s |
Rastrear sem renderizacao JavaScript alcancou 100% de sucesso em ambas as escalas. A renderizacao completa retornou 4 de 5 paginas em um teste de amostra pequena. Em uma amostra tao pequena, a pagina ausente pode ser um timeout do navegador, um erro transitorio ou um problema do script.
Teste 2: Loja Shopify Pequena (Store D, 24 paginas)
Uma loja menor onde testamos o fluxo de trabalho completo:
Rastrear sem renderizacao retornou erros. Nosso teste inicial retornou respostas 429 na busca HTML simples. Nao retestamos esta loja com tratamento de erros melhorado, entao nao podemos confirmar se os 429s se originaram do rate limiting da loja ou de problemas transitorios durante o teste.
Renderizacao completa com descoberta baseada em sitemap foi um sucesso total. 24 de 24 paginas rastreadas, 100% de conclusao.
| Tipo de Pagina | Quantidade |
|---|---|
| Products | 9 |
| Collections | 4 |
| Pages | 3 |
| Blogs/News | 5 |
| Other (homepage, blog index) | 3 |
Uma descoberta importante: o modo padrao de descoberta de URLs encontrou apenas 1 pagina porque a homepage tinha quase nenhum link interno. Mudar para descoberta baseada em sitemap encontrou todas as 24. Se sua homepage e minimalista ou pesada em JavaScript, o rastreador pode nao encontrar paginas apenas atraves de links.
Teste 3: Loja de Vestuario Media (Store B, 256 paginas), Com e Sem Renderizacao
Nosso teste mais detalhado. Uma loja de vestuario media com 256 paginas indexaveis: produtos, colecoes, posts de blog e paginas informativas. Executamos ambos os modos no site completo para medir a diferenca real.
| Metrica | render: false | render: true | Diferenca |
|---|---|---|---|
| Paginas rastreadas | 256 / 266 | 256 / 266 | Igual |
| Saida total de markdown | 11,0 MB | 12,5 MB | +14% |
| Tempo de navegador | 0s | 1.338s (22 min) | +22 min |
| Custo estimado | $0 (beta) | ~$0,03 | +$0,03 |
| Tempo real | ~5 min | ~25 min | 5x mais lento |
Teste 4: Varejista de Saude e Suplementos (Store C), Sucesso Parcial em Escala
Um grande varejista de produtos de saude com um catalogo massivo. Executamos dois rastreamentos sem renderizacao em diferentes escalas:
| Tamanho do Rastreamento | Paginas Retornadas | Taxa de Sucesso | Tempo Real |
|---|---|---|---|
| Amostra de 5 paginas | 2 / 5 | 40% | ~25s |
| Rastreamento de 100 paginas | 89 / 100 | 89% | ~3,5 min |
A taxa de sucesso parcial pode indicar que a infraestrutura desta loja descarta algumas requisicoes sem navegador, mas nosso teste inicial nao tinha recuperacao de erros robusta, entao algumas dessas falhas podem ter sido recuperaveis com melhor tratamento de retentativas do nosso lado. A taxa de sucesso melhorou de 40% para 89% em escala maior. Nao retestamos esta loja com tratamento de erros melhorado para isolar a causa.
Teste 5: Loja Multi-Categoria Grande (Store E, ~1.200 paginas)
Nosso maior e mais revelador teste. Uma loja Shopify com aproximadamente 1.200 URLs distribuidas em quatro sitemaps: 521 produtos, 626 colecoes, 22 paginas e 31 posts de blog.
| Metrica | render: false | render: true (otimizado) |
|---|---|---|
| Paginas rastreadas | 1.200 / 1.200 | 100 / 100 |
| Saida total de markdown | 148,5 MB | 11,3 MB |
| Tempo de navegador | 0s | 475s (~8 min) |
| Custo estimado | $0 (beta) | ~$0,012 |
| Tempo real | ~55 min | ~12 min |
O rastreamento sem renderizacao atingiu 100% de sucesso em todas as 1.200 paginas com zero custo de navegador. O rastreamento renderizado foi executado em uma amostra de 100 paginas com otimizacoes de bloqueio de recursos habilitadas.
O bloqueio de recursos fez a diferenca entre um rastreamento travado e um limpo. Sem bloquear recursos, o rastreamento renderizado travou em 99 de 100 paginas indefinidamente e consumiu 649 segundos de tempo de navegador para essas 99 paginas. Habilitar o bloqueio de recursos (imagens, midia, fontes, folhas de estilo) com uma condicao de espera domcontentloaded completou todas as 100 paginas em 475 segundos, uma reducao de 27% no tempo do navegador sem travamentos.
Crawl-delay no robots.txt criou paralisacoes visiveis. O robots.txt da Store E especifica um crawl-delay de 10 segundos para certos bots. Em nossos dados de polling sem renderizacao, isso apareceu como platos de varios minutos onde a contagem de paginas parava antes de retomar. O rastreador da Cloudflare respeita diretivas de crawl-delay, o que estende diretamente o tempo real em sites que as definem.
O Que o Endpoint /crawl Realmente Aceita
O endpoint recebe uma URL inicial, nao uma lista. Ele descobre paginas navegando para fora dessa URL atraves de sitemaps, links de pagina ou ambos. Se voce ja tem uma lista de URLs de um rastreamento Scrapy e quer usar a Cloudflare para conversao de markdown, precisaria chamar os endpoints separados /markdown ou /scrape individualmente por URL.
O Que o Cloudflare /crawl Realmente Faz no Lado do Servidor?
Extraimos os logs completos do servidor durante um rastreamento totalmente renderizado da Store D (25 paginas) para analisar a pegada real de trafego. Os resultados revelam diferencas fundamentais entre rastreamento renderizado por navegador e rastreamento tradicional de bot, com efeitos colaterais nao intencionais para analytics, carga do servidor e monitoramento de trafego de bots.
| Metrica | Valor |
|---|---|
| User-Agent | CloudflareBrowserRenderingCrawler/1.0 (100% dos hits) |
| Janela de rastreamento | 134 segundos (~2 minutos) |
| Throughput de pico | 82 requisicoes/segundo |
| IPs unicos | 23, em 5 data centers da Cloudflare |
| Requisicoes GET | 2.071 |
| Requisicoes POST | 163 |
| Total de requisicoes | 2.234 |
| Paginas reais renderizadas | ~25 |
| Requisicoes por pagina | ~89x amplificacao |
Quanto Trafego um Cloudflare /crawl Totalmente Renderizado Realmente Gera?
A maior descoberta: apenas 1,1% das 2.234 requisicoes eram conteudo de pagina real. Os outros 98,9% eram JavaScript, CSS, beacons de analytics, pixels de rastreamento e preloads de checkout disparados pelo navegador carregando cada pagina como um visitante real faria.
Um bot sem renderizacao como Amazonbot ou ChatGPT-User gera 1 requisicao por pagina. O renderizador de navegador da Cloudflare gera 89.
O Cloudflare /crawl Infla as Analytics do Shopify?
As 163 requisicoes POST em nossos logs eram inteiramente endpoints de analytics e rastreamento do Shopify disparando durante o rastreamento. Esses sao os mesmos eventos que disparam quando um cliente real visita sua loja. Da perspectiva do Shopify Analytics, o rastreador da Cloudflare parece um visitante navegando cada pagina do seu site em 2 minutos.
Quao Rapido o Cloudflare /crawl Atinge Seu Servidor?
Todas as 2.234 requisicoes chegaram em uma janela de 134 segundos. O throughput de pico atingiu 82 requisicoes por segundo. O rastreador renderizou todo o site de 25 paginas em pouco mais de 2 minutos, mas o servidor viu uma rajada sustentada de trafego que nao se parece com padroes organicos de navegacao.
Para lojas pequenas, isso e gerenciavel. Para lojas maiores com milhares de paginas, a amplificacao de requisicoes (89x por pagina) combinada com throughput sustentado pode criar carga significativa no servidor de origem, especialmente se voce esta em um plano de hospedagem compartilhada ou tem rate limiting agressivo em vigor.
De Onde Vem o Cloudflare /crawl?
O rastreamento foi distribuido por 5 data centers da Cloudflare nos EUA:
| Data Center | % de Requisicoes | Localizacao |
|---|---|---|
| ATL | 38% | Atlanta |
| ORD | 25% | Chicago |
| MIA | 23% | Miami |
| EWR | 9% | Newark |
| IAD | 5% | Washington DC |
Nao e um unico servidor fazendo requisicoes. A Cloudflare distribui a carga de trabalho de renderizacao pela sua rede edge. Todos os 23 IPs estavam na faixa 104.28.x.x, e o user-agent era CloudflareBrowserRenderingCrawler/1.0 em cada requisicao.
Qual Fingerprint de Navegador o Cloudflare /crawl Deixa?
O renderizador envia headers Sec-Fetch adequados que imitam um navegador Chrome real:
| Header | Valor | Chrome Real? |
|---|---|---|
sec-fetch-dest |
script, document, etc. |
Sim, corresponde |
sec-fetch-mode |
cors, navigate |
Sim, corresponde |
sec-fetch-site |
same-origin, cross-site |
Sim, corresponde |
sec-ch-ua (Client Hints) |
Nao enviado | Nao, Chrome real envia isso |
| Versao HTTP | HTTP/1.1 | Nao, Chrome real negocia HTTP/2 ou HTTP/3 |
Duas lacunas de fingerprint se destacam: o renderizador omite headers sec-ch-ua Client Hints inteiramente (um navegador Chrome real sempre envia esses), e todas as requisicoes usam HTTP/1.1 em vez de HTTP/2 ou HTTP/3. Se voce esta construindo regras de deteccao de bots, esses sao sinais confiaveis para distinguir o renderizador de navegador da Cloudflare do trafego real de visitantes.
Como o Cloudflare /crawl se Compara a Outros Bots de IA nos Logs do Servidor?
Comparamos o rastreamento da Cloudflare com outros bots que acessaram a mesma loja na mesma janela de 12 horas:
Amazonbot e ChatGPT-User buscam HTML bruto: uma requisicao, uma pagina, sem execucao de JavaScript. AhrefsBot rastreia sitemaps para descoberta. O renderizador de navegador da Cloudflare executa uma vitrine Shopify completa em cada pagina, disparando cada script, pixel e preload como se um cliente real estivesse navegando.
Velocidade e Custo do Cloudflare /crawl: O Benchmark Completo
Cada rastreamento que executamos, em uma tabela. Todas as lojas anonimizadas, todos os numeros de testes reais. Tempos reais sao aproximados. Taxas de sucesso para Stores C e D podem ter sido afetadas pelo tratamento de erros limitado em nossos scripts de teste iniciais.
| Loja | Paginas | Modo | Taxa de Sucesso | Tempo de Navegador | Tempo Real | Custo |
|---|---|---|---|---|---|---|
| A: E-Commerce Grande | 500 / 500 | no-render | 100% | 0s | ~18 min | $0 |
| B: Vestuario Medio | 256 / 266 | no-render | 96% | 0s | ~5 min | $0 |
| C: Saude e Suplementos | 89 / 100 | no-render | 89% | 0s | ~3,5 min | $0 |
| D: Shopify Pequena | 24 / 24 | render: true | 100% | 58s | ~2 min | ~$0,002 |
| E: Multi-Categoria Grande | 1.200 / 1.200 | no-render | 100% | 0s | ~55 min | $0 |
Quao Rapido E o Cloudflare /crawl Com vs. Sem Renderizacao?
A comparacao mais clara vem da Store B, onde executamos ambos os modos nas mesmas 256 paginas:
O padrao em todos os onze rastreamentos e consistente: rastrear sem renderizacao e dramaticamente mais rapido. O tempo real sem renderizacao e principalmente o overhead de fila interna e busca da Cloudflare. A renderizacao completa adiciona aproximadamente 5 segundos de tempo de navegador por pagina alem dessa baseline.
Quanto Custa um Rastreamento Cloudflare Totalmente Renderizado Por Pagina?
O preco do Browser Rendering da Cloudflare e baseado em horas de navegador, o tempo que o navegador headless deles gasta renderizando ativamente suas paginas. Rastrear sem renderizacao usa zero horas de navegador e e gratuito durante o beta.
Plano Workers Free: 10 minutos de tempo de navegador por dia. O endpoint /crawl e ainda limitado a 5 trabalhos de rastreamento por dia, com maximo de 100 paginas por rastreamento.
Plano Workers Paid ($5/mes): 10 horas de tempo de navegador por mes incluidas. Alem disso, voce paga $0,09 por hora adicional de navegador. Sem limites por rastreamento no endpoint /crawl. Ate 600 requisicoes de API por minuto.
Aqui esta o que nossos rastreamentos de teste realmente custaram a $0,09/hr:
| Rastreamento | Tempo de Navegador Usado | Custo a $0,09/hr |
|---|---|---|
| Store D: 24 paginas renderizadas | 58 segundos | ~$0,002 |
| Store B: 256 paginas renderizadas | 1.338 segundos (~22 min) | ~$0,03 |
| Catalogo de 3.000 paginas (estimado) | ~4 horas | ~$0,36 |
Com aproximadamente 5 segundos de tempo de navegador por pagina, todos esses custos ficam bem dentro das 10 horas incluidas no plano pago. Um rastreamento renderizado de 3.000 paginas usaria cerca de 4 das suas 10 horas incluidas, o que significa que voce poderia executar dois rastreamentos completos por mes antes de pagar algo alem dos $5 base. Rastrear sem renderizacao e gratuito e nao tem custo de tempo de navegador em nenhum dos planos.
Quando Voce Deve Pular a Renderizacao vs. Usar Renderizacao Completa no Cloudflare /crawl?
A Conclusao
Para a maioria das lojas Shopify com conteudo renderizado no servidor, rastrear sem renderizacao obtem mais de 90% do conteudo util a custo zero em uma fracao do tempo.
O Que Aprendemos Testando o Cloudflare /crawl em Lojas Shopify
Apos executar 11 rastreamentos em 5 lojas Shopify reais e analisar logs completos do servidor, estas sao as descobertas mais importantes.
90% do Conteudo Vem Sem Renderizacao
Para lojas Shopify com paginas padrao renderizadas no servidor, rastrear sem renderizacao JavaScript capturou mais de 90% do conteudo util. O aumento de 14% no conteudo da renderizacao completa veio quase inteiramente de elementos carregados por JavaScript em homepages e paginas de indice. Paginas individuais de produtos e artigos de blog foram quase identicos de qualquer forma. A menos que sua loja seja construida como um aplicativo de pagina unica, voce provavelmente nao precisa de renderizacao completa.
Renderizacao Completa Cria um Multiplicador de Trafego de 89x
Renderizar 25 paginas gerou 2.234 requisicoes ao servidor. Apenas 25 delas eram conteudo de pagina real. Os outros 98,9% eram arquivos JavaScript (75%), beacons de analytics (6,3%), CSS (4,3%), pixels de rastreamento (3,4%) e preloads de checkout (3,3%). Cada pagina renderizada dispara toda a stack client-side do Shopify como se um cliente real estivesse navegando.
Suas Analytics do Shopify Provavelmente Estao Sendo Infladas
Rastreamentos renderizados disparam toda a stack de analytics do Shopify: beacons monorail, eventos de rastreamento, preloads do Shop Pay e scripts de web-pixel. Acreditamos que isso significa que o Shopify Analytics esta contando essas como sessoes reais de visitantes. Se for o caso, um unico rastreamento renderizado poderia inflar suas contagens de sessoes, visualizacoes de pagina e dados de funil de conversao. Nao confirmamos isso diretamente nos relatorios do Shopify, mas os logs do servidor mostram todos os mesmos eventos de analytics disparando como fariam para um cliente real.
Renderizacao Completa Pode Contornar Limites de Taxa da Loja
A Store D retornou erros 429 em cada pagina sem renderizacao. Mudar para renderizacao completa na mesma loja produziu 100% de sucesso. Se voce encontrar limites de taxa sem renderizacao, a renderizacao completa e sua solucao.
Descoberta por Sitemap E Mais Confiavel Que Descoberta por Links
A descoberta padrao baseada em links nao encontrou quase nada na Store D porque a homepage tinha muito poucos links internos. Mudar para descoberta baseada em sitemap encontrou todas as 24 paginas. Sempre use descoberta por sitemap.
O Rastreador Vem de 5 Data Centers nos EUA
A Cloudflare distribui a carga de trabalho de renderizacao pela sua rede edge. Nosso rastreamento veio de 23 IPs unicos distribuidos por Atlanta (38%), Chicago (25%), Miami (23%), Newark (9%) e Washington DC (5%). Todos os IPs estao na faixa 104.28.x.x.
Duas Lacunas de Fingerprint o Identificam Como Bot
O renderizador omite headers sec-ch-ua Client Hints (Chrome real sempre envia esses) e usa HTTP/1.1 em vez de HTTP/2 ou HTTP/3. Se voce esta construindo regras de deteccao de bots, esses sao sinais confiaveis.
Renderizacao Pode Na Verdade Retornar Menos Conteudo
Na Store E, o rastreamento sem renderizacao retornou 6,8% mais conteudo por pagina do que o rastreamento renderizado. Bloquear imagens, fontes e folhas de estilo para otimizar o tempo do navegador tambem impediu que algum JavaScript populasse elementos dinamicos. O HTML estatico ja tinha tudo. Para lojas Shopify renderizadas no servidor, a renderizacao nao garante capturar mais conteudo.
Bloqueio de Recursos Previne Rastreamentos Travados
Sem bloqueio de recursos, o rastreamento renderizado na Store E travou em 99 de 100 paginas e nunca completou. Habilitar bloqueio para imagens, midia, fontes e folhas de estilo com uma condicao de espera domcontentloaded completou todas as 100 paginas e reduziu o tempo do navegador em 27%. Se seus rastreamentos renderizados travam antes de terminar, bloqueio de recursos e a solucao.
Crawl-Delay do robots.txt Estende o Tempo Real
O robots.txt da Store E especifica um crawl-delay de 10 segundos. Em nossos dados de polling sem renderizacao, isso apareceu como platos de varios minutos onde a contagem de paginas parava antes de retomar. O rastreador da Cloudflare respeita diretivas de crawl-delay, entao sites com delays agressivos terao tempos reais significativamente maiores do que a contagem de paginas sozinha sugeriria.
O Custo E Baixo Mas o Plano Gratuito Tem Limites
Renderizar 256 paginas custou aproximadamente $0,03 a $0,09 por hora de navegador. Renderizar 24 paginas custou aproximadamente $0,002. O plano Workers Free limita o tempo de navegador a 10 minutos por dia com maximo de 5 trabalhos de rastreamento e 100 paginas por rastreamento. O plano Workers Paid ($5/mes) inclui 10 horas de tempo de navegador por mes sem limites por rastreamento. Um rastreamento renderizado de 3.000 paginas usaria cerca de 4 dessas 10 horas incluidas, entao a maioria das lojas cabe confortavelmente no plano pago sem excedente. Rastrear sem renderizacao usa zero tempo de navegador e e gratuito em qualquer plano durante o beta.
Os Pros
Velocidade
Paginas buscadas quase instantaneamente versus um rastreamento Scrapy de varias horas com autothrottle. Sem filas, sem delays de cortesia, sem esperar que seu spider trabalhe por milhares de requisicoes em um ritmo respeitoso.
Saida em Markdown
O endpoint retorna HTML-para-Markdown pre-convertido para cada pagina. Isso e diretamente util para ingestao por LLM, pipelines RAG e analise de conteudo sem nenhum pos-processamento. Voce pula toda a camada de extracao e vai direto para texto limpo. Para equipes construindo aplicacoes de IA em cima de conteudo de websites, isso remove uma etapa do pipeline.
Opcao de Modo de Renderizacao
Definir render: true executa JavaScript e extrai automaticamente metadados Open Graph (og:title, og:description, og:image, og:site_name). Para sites pesados em JavaScript onde o conteudo e renderizado no lado do cliente, essa e a diferenca entre ver a pagina real e ver uma estrutura vazia.
Sem Dores de Cabeca com Proxy ou Rate-Limit
A Cloudflare lida com medidas anti-bot e rate limiting na propria infraestrutura. Voce nao precisa gerenciar pools de proxy, rotacionar user agents ou lidar com CAPTCHAs. Uma unica chamada de API.
Rastreamento Incremental
Os parametros modifiedSince e maxAge permitem pular paginas que nao mudaram ou foram buscadas recentemente. Para rastreamentos recorrentes onde voce esta monitorando mudancas de conteudo, isso economiza tanto tempo quanto custo ao processar apenas paginas que sao realmente novas ou atualizadas.
Simplicidade
Uma unica chamada de API. Resposta JSON. Sem codigo de spider, sem middleware, sem pipelines de itens, sem arquivos de configuracao.
Bot Bem-Comportado por Padrao
O rastreador e um agente assinado que respeita robots.txt, crawl-delay e o AI Crawl Control da Cloudflare. Ele se auto-identifica como CloudflareBrowserRenderingCrawler/1.0 e nao pode contornar protecao contra bots ou CAPTCHAs. Voce obtem conformidade etica de rastreamento sem construir a logica voce mesmo.
O Que o Endpoint Cloudflare Crawl Nao Suporta
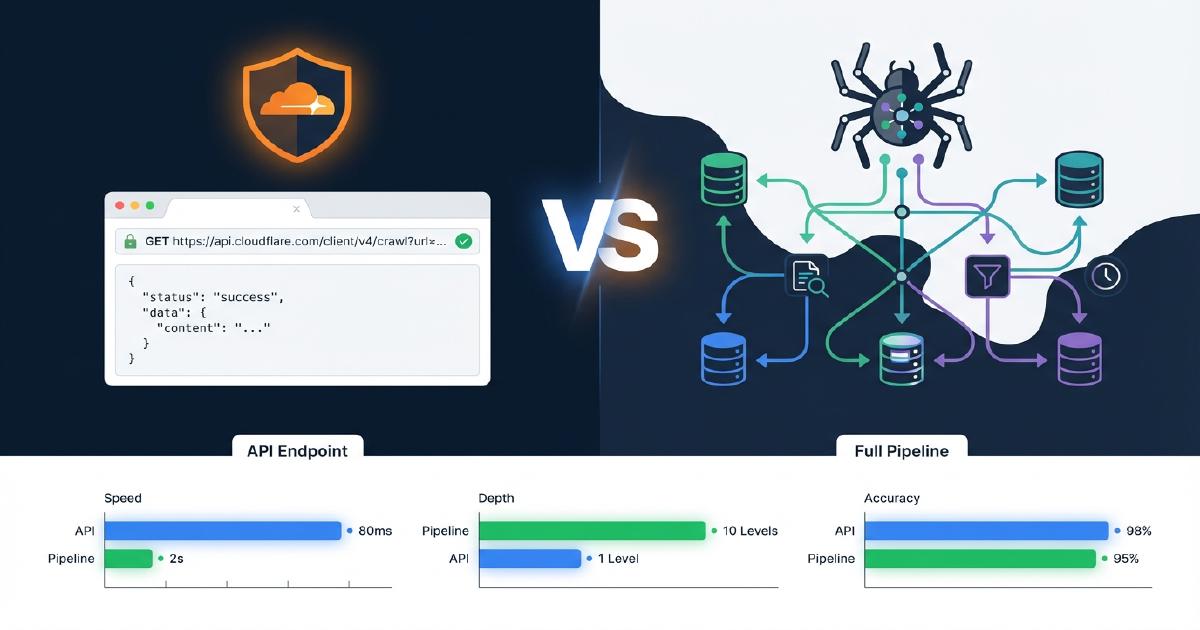
Como o Cloudflare /crawl Difere de um Pipeline Completo de Rastreamento?
A tabela abaixo mostra exatamente quais capacidades estao presentes no endpoint /crawl da Cloudflare versus um pipeline Scrapy de producao. Isso e baseado em nossos testes reais contra lojas Shopify.
| Capacidade | Cloudflare /crawl | Pipeline Scrapy |
|---|---|---|
| Busca de conteudo (HTML/Markdown) | Sim | Sim |
| Renderizacao JavaScript | Sim (render: true) |
Sim (Splash/Playwright) |
| Descoberta de links / spidering | Sim (lista plana) | Sim (grafo completo de rastreamento) |
| Mapeamento de links pai-filho | Nao | Sim |
| Deteccao de paginas orfas | Nao | Sim |
| Rastreamento de cadeias de redirecionamento | Nao | Sim |
| Extracao de JSON-LD | Nao | Sim |
| Extracao de Microdata | Nao | Sim |
| Validacao de schema + relatorio de problemas | Nao | Sim |
| Codigos de status nao-200 (404s, 403s) | Nao | Sim (capturou 2.547 404s no nosso teste) |
| Limite de URLs | 100.000 | Nenhum |
Quais Dados Estruturados o Cloudflare /crawl Extrai?
Com render: false, nenhum. Sem JSON-LD, sem Microdata, sem parsing de OpenGraph.
Com render: true, apenas tags OG basicas (og:title, og:description, og:image, og:site_name). JSON-LD e marcacao schema.org nao sao analisados, extraidos ou validados.
Para comparacao, nosso pipeline Scrapy produz schemas_found, issues (falta contactPoint, address, etc.), top_level_schemas e nested_schemas para cada URL. Voce pode ver quais paginas tem schema Product, quais estao sem marcacao Organization e quais tem erros de validacao que fariam sistemas de IA interpretar mal o conteudo.
Quais Codigos de Status HTTP o Cloudflare /crawl Retorna?
Apenas respostas 200. Nosso rastreamento Scrapy do mesmo site capturou 2.547 erros 404, alem de respostas 403 e erros de conexao. A deteccao de 404 e critica para analise de paginas fantasma, remediacao de links quebrados e mapeamento de redirecionamentos. Sem isso, voce esta perdendo as paginas que estao ativamente vazando link equity e confundindo rastreadores de IA.
Quantas URLs o Cloudflare /crawl Pode Processar?
Ate 100.000 por trabalho. Isso cobre a maioria dos sites, mas grandes catalogos de e-commerce com centenas de milhares de paginas de produtos, URLs de variantes e paginas de colecoes filtradas excederao o limite. O Scrapy nao tem limite inerente de URLs.
O Cloudflare /crawl Tem um Bug de Resolucao de URL?
Encontramos 233 de 908 links em uma unica pagina de produto com caminhos quebrados. O conversor de markdown resolve URLs relativas contra a URL da pagina incorretamente, produzindo URLs com caminhos duplicados como /products/slug//www.example.com/.... Este e um bug confirmado no conversor da Cloudflare que afeta qualquer analise downstream de links.
Quanto Boilerplate Ha na Saida Markdown do Cloudflare /crawl?
A pagina media retornou 158 KB de markdown. Aproximadamente 90% e conteudo de template repetido: navegacao completa, mega menu e rodape em cada registro. Para analise de conteudo, isso significa trabalho pesado de deduplicacao, e para uso de tokens de LLM, o custo se acumula rapido. Voce precisa de sua propria logica de extracao de conteudo em cima do markdown para isolar o conteudo real da pagina.
O Que o Cloudflare /crawl Nao Classifica?
Nao ha etiquetagem de tipo de conteudo. Paginas de produtos, paginas de colecoes, posts de blog e homepages voltam como registros indiferenciados. O Scrapy classifica cada URL por tipo, o que e essencial para entender a cobertura de rastreamento por categoria de pagina e para identificar quais tipos de conteudo bots de IA priorizam.
Quais Recursos de Finalizacao Estao Ausentes no Cloudflare /crawl?
Sem capturas de tela de paginas fantasma. Sem comparacao de renderizacao JavaScript (o que o bot ve versus o que o navegador ve). Sem analise de bots de IA no robots.txt. Sem relatorio de qualidade de rastreamento. Sem manifesto do cliente. Sem sincronizacao CDN. Os dados da Cloudflare sao apenas conteudo bruto. Cada peca do pipeline de relatorios e analise precisaria ser construida separadamente.
Quanto Custa o Cloudflare /crawl para Sites Grandes?
Em nossos testes, render: true teve uma media de aproximadamente 5 segundos de execucao de navegador por pagina. Um rastreamento de 256 paginas usou 1.338 segundos de navegador (22 minutos) e custou aproximadamente $0,03 a $0,09 por hora de navegador. Um rastreamento de 24 paginas usou 58 segundos de navegador e custou aproximadamente $0,002. Extrapolando para um catalogo de 3.000 paginas: aproximadamente 4 horas de tempo de navegador. O plano Workers Free e limitado a 10 minutos de tempo de navegador por dia, 5 trabalhos de rastreamento por dia e 100 paginas por rastreamento. O plano Workers Paid ($5/mes) inclui 10 horas de tempo de navegador por mes sem limites por rastreamento, entao um rastreamento de 3.000 paginas usaria cerca de 4 dessas 10 horas incluidas. render: false usa zero tempo de navegador e e gratuito durante o beta em qualquer plano.
A Conclusao Final
O endpoint crawl da Cloudflare e otimo para:
- Snapshots rapidos de conteudo quando voce precisa do texto da pagina rapido
- Markdown pronto para LLM para pipelines RAG e ingestao de conteudo
- Verificacoes ad-hoc de paginas onde voce sabe as URLs exatas que precisa
- Extraccoes rapidas de conteudo do site inteiro quando voce precisa de texto markdown sem construir um spider
Ele nao pode substituir um pipeline completo de rastreamento porque o valor do pipeline esta em:
- Grafo completo de rastreamento com topologia de links, deteccao de orfas e cobertura de 404s
- Extracao e validacao de dados estruturados (JSON-LD, Microdata, OpenGraph)
- Classificacao de conteudo por tipo de pagina
- Todo o pipeline de finalizacao incluindo analise de paginas fantasma, comparacao de renderizacao JavaScript, relatorios de schema e pontuacao de prontidao para LLM
A Melhor Abordagem Hibrida
Use a Cloudflare como fonte de dados suplementar. Apos um rastreamento completo identificar suas URLs, use a saida markdown da Cloudflare para alimentar pontuacao de prontidao para LLM ou analise de qualidade de conteudo onde voce precisa do texto real da pagina em vez de metadados estruturados. O pipeline de rastreamento descobre e classifica. O endpoint da Cloudflare entrega texto limpo para as paginas que importam.
Quer ver o pipeline completo de rastreamento em acao?
Agendar uma ChamadaPerguntas Frequentes
Quais recursos de auditoria de sites nao sao suportados pelo Cloudflare /crawl?
O Cloudflare /crawl nao suporta: construcao completa de grafo de rastreamento, mapeamento de links pai-filho, deteccao de paginas orfas, rastreamento de cadeias de redirecionamento, extracao de JSON-LD ou Microdata, validacao de schema, captura de codigos de status nao-200 (404s, 403s), classificacao de tipo de conteudo, medicao de tamanho de pagina em bytes, deteccao de paginas fantasma, comparacao de renderizacao JS vs HTML, analise de bots de IA no robots.txt ou referencia cruzada de backlinks. E um buscador de conteudo, nao uma ferramenta de auditoria de sites.
Como o Cloudflare /crawl difere do Scrapy para rastreamento de e-commerce?
O Cloudflare /crawl busca conteudo rapidamente sem infraestrutura para gerenciar. O Scrapy constroi um grafo completo de rastreamento com topologia de links, extrai e valida dados estruturados (JSON-LD, Microdata, OpenGraph), captura todos os codigos de status HTTP incluindo 404s, classifica paginas por tipo de conteudo e alimenta um pipeline downstream para analise de paginas fantasma, relatorios de schema e pontuacao de prontidao para LLM. O Cloudflare fornece o texto da pagina; o Scrapy fornece a arquitetura completa do site.
Qual e o limite exato de URLs para o Cloudflare /crawl?
100.000 URLs por trabalho de rastreamento. O limit padrao e 10, entao voce deve defini-lo explicitamente. A depth maxima tambem e 100.000. Para sites que excedem 100K paginas, o Scrapy ou outro rastreador sem limite inerente de URLs e necessario.
O Cloudflare /crawl extrai JSON-LD ou valida marcacao schema?
Nao. Com render: false, nenhum dado estruturado e extraido. Com render: true, apenas tags basicas Open Graph sao retornadas (og:title, og:description, og:image, og:site_name). JSON-LD, Microdata e marcacao schema.org nao sao analisados, extraidos ou validados em nenhum dos modos.
Quanto custa o Cloudflare /crawl para renderizar sites grandes?
Em nossos testes, render: true teve uma media de aproximadamente 5 segundos de tempo de navegador por pagina. Um site de 256 paginas usou 1.338 segundos de navegador (22 minutos) e custou aproximadamente $0,03 a $0,09 por hora de navegador. Um site de 24 paginas usou 58 segundos e custou aproximadamente $0,002. Extrapolando para um catalogo de 3.000 paginas: aproximadamente 4 horas de tempo de navegador. O plano Workers Free e limitado a 10 minutos por dia, 5 trabalhos de rastreamento por dia e 100 paginas por rastreamento, entao rastreamentos renderizados grandes requerem o plano Workers Paid ($5/mes), que inclui 10 horas de tempo de navegador por mes sem limites por rastreamento. render: false usa zero tempo de navegador e e gratuito durante o beta em qualquer plano.
O Cloudflare /crawl tem um bug conhecido de resolucao de URL?
Sim. Em nosso teste, 233 de 908 links em uma unica pagina de produto tinham caminhos malformados. O conversor de markdown prepende a URL da pagina a caminhos relativos como //www.example.com/cdn/..., criando URLs com caminhos duplicados quebrados. Isso afeta qualquer analise downstream de grafo de links ou auditoria de links internos construida a partir da saida markdown.
Por que o Cloudflare /crawl com render false retorna erros 429 em algumas lojas Shopify?
render: false faz uma busca HTML bruta sem um navegador headless. Em um dos nossos testes, render: false retornou erros 429 enquanto render: true funcionou com 100% de sucesso na mesma loja. Nao retestamos isso com tratamento de erros melhorado, entao os 429s podem ter sido causados pelo rate limiting da loja, problemas transitorios da API ou uma combinacao. Se voce encontrar erros 429 sem renderizacao, tente render: true como primeiro passo.
O Cloudflare /crawl aceita uma lista de URLs?
Nao. O endpoint recebe uma unica URL inicial e descobre paginas navegando para fora atraves de sitemaps, links de paginas ou ambos. Se voce ja tem uma lista de URLs e quer a conversao markdown da Cloudflare, use os endpoints separados /markdown ou /scrape, que aceitam URLs individuais por requisicao.
Por que o Cloudflare /crawl com source all encontra apenas uma pagina em alguns sites?
O source: all padrao descobre URLs tanto de sitemaps quanto de links de paginas. Se a URL inicial tem muito poucos links internos (comum em homepages minimalistas ou SPAs pesadas em JavaScript), o rastreador pode nao encontrar paginas adicionais apenas pela descoberta de links. Mude para source: sitemaps para garantir que o rastreador leia o sitemap.xml completo e descubra todas as URLs listadas.
Qual e a melhor forma de usar o Cloudflare /crawl com um pipeline completo de rastreamento?
Use o pipeline completo de rastreamento (Scrapy ou equivalente) primeiro para descobrir URLs, construir o grafo de links, extrair dados estruturados, capturar 404s e classificar conteudo. Depois use os endpoints /markdown ou /scrape da Cloudflare para obter markdown limpo para pontuacao de prontidao para LLM, analise de qualidade de conteudo ou ingestao RAG onde voce precisa do texto real da pagina em vez de metadados estruturados.
Quanto mais rapido e o Cloudflare /crawl render false comparado ao render true?
Em nosso teste direto no mesmo site de 256 paginas, render: false completou em aproximadamente 5 minutos. render: true levou aproximadamente 25 minutos para as mesmas paginas. Essa e uma diferenca de velocidade de 5x. A diferenca de tempo real vem de aproximadamente 5 segundos de execucao do navegador adicionados por pagina quando a renderizacao esta ativada. render: false custou $0 durante o beta. render: true custou aproximadamente $0,03 para o mesmo rastreamento.
Quanto conteudo extra o Cloudflare /crawl render true captura comparado ao render false?
Em nosso teste de 256 paginas, render: true produziu 12,5 MB de markdown versus 11,0 MB do render: false, um aumento de 14%. O conteudo extra veio quase inteiramente de elementos carregados por JavaScript na homepage e paginas de indice do blog. Paginas individuais de produtos e artigos do blog foram quase identicas entre os modos. Para sites com conteudo majoritariamente renderizado no servidor, render: false captura mais de 90% do texto util a custo zero e velocidade 5x maior.
O Cloudflare /crawl funciona de forma confiavel em todas as lojas Shopify?
Depende da loja e do modo de renderizacao. Em nossos testes com cinco lojas Shopify: Store A (catalogo grande) alcancou 100% de sucesso com render: false. Store B (vestuario medio) alcancou 96% de sucesso com ambos os modos. Store C (saude e suplementos) alcancou 40% em uma amostra de 5 paginas e 89% em um rastreamento de 100 paginas com render: false, embora nosso teste inicial nao tivesse recuperacao de erros robusta e algumas falhas podem ter sido recuperaveis. Store D (loja pequena) retornou erros 429 com render: false mas alcancou 100% com render: true. Store E (multi-categoria grande, ~1.200 paginas) alcancou 100% de sucesso com render: false e 100% em uma amostra renderizada de 100 paginas com otimizacoes de bloqueio de recursos. Nao retestamos Stores C e D com tratamento de erros melhorado. Teste ambos os modos na sua loja especifica antes de se comprometer com uma estrategia de rastreamento.
Qual e o tempo real para um Cloudflare /crawl de 500 paginas com render false?
Em nosso teste, um rastreamento render: false de 500 paginas completou em aproximadamente 18 minutos com uma taxa de sucesso de 100%. Um rastreamento de 256 paginas em uma loja diferente completou em aproximadamente 5 minutos. Um rastreamento de 100 paginas completou em aproximadamente 3,5 minutos. Esses tempos reais sao estimativas baseadas em intervalos de polling, nao medicoes precisas. O tempo real e principalmente o overhead de fila interna e busca HTTP da Cloudflare, nao renderizacao do navegador, ja que nenhum segundo de navegador e usado com render: false.
Quantas requisicoes ao servidor um Cloudflare /crawl render true gera?
Em nossa analise de logs do servidor, um unico rastreamento render: true de 25 paginas gerou 2.234 requisicoes totais: 2.071 GETs e 163 POSTs. Isso e aproximadamente 89 requisicoes ao servidor por pagina real renderizada. Apenas 1,1% das requisicoes eram conteudo de pagina real. Os 98,9% restantes eram arquivos JavaScript (75%), beacons de analytics (6,3%), CSS (4,3%), pixels de rastreamento (3,4%) e preloads de checkout (3,3%). Se voce esta monitorando trafego de bots ou gerenciando carga do servidor, espere que um rastreamento renderizado gere 89x o numero de requisicoes reais de pagina nos seus logs do servidor.
Qual user-agent o Cloudflare /crawl usa e de qual faixa de IP ele vem?
O rastreador se identifica como CloudflareBrowserRenderingCrawler/1.0 em 100% das requisicoes. Em nossos logs, todas as requisicoes vieram de 23 IPs unicos na faixa 104.28.x.x distribuidos por 5 data centers da Cloudflare nos EUA: ATL (38%), ORD (25%), MIA (23%), EWR (9%) e IAD (5%). Nao ha rotacao de user-agent ou disfarce de IP. O rastreador e um bot assinado e identificavel por design.
O Cloudflare /crawl infla as analytics e contagens de visitantes do Shopify?
Acreditamos que sim, mas nao confirmamos isso diretamente nos relatorios do Shopify. Porque render: true executa JavaScript, ele dispara toda a stack de analytics do Shopify em cada pagina: beacons monorail, eventos de rastreamento /api/collect, preloads de checkout do Shop Pay e scripts de sandbox de web-pixel. Em nosso teste, 163 das 2.234 requisicoes eram requisicoes POST para endpoints de analytics do Shopify. Esses sao os mesmos eventos que disparam para clientes reais. Se o Shopify conta esses como sessoes reais, suas contagens de sessoes, visualizacoes de pagina e dados de funil de conversao estariam inflados.
Como voce pode detectar o Cloudflare /crawl em logs do servidor vs trafego real de navegador?
Duas lacunas confiaveis de fingerprint: o renderizador de navegador da Cloudflare omite headers sec-ch-ua Client Hints (um navegador Chrome real sempre envia esses), e todas as requisicoes usam HTTP/1.1 em vez de HTTP/2 ou HTTP/3 que um navegador real negociaria. Ele envia headers sec-fetch-dest, sec-fetch-mode e sec-fetch-site adequados que correspondem ao Chrome real. O user-agent e sempre CloudflareBrowserRenderingCrawler/1.0 e todos os IPs estao na faixa 104.28.x.x.