
Cos’e l’endpoint Cloudflare /crawl?
L’endpoint /crawl di Cloudflare fa parte della loro API Browser Rendering, attualmente in open beta. Esegue lo scraping dei contenuti da un URL di partenza, segue i link nel sito fino a una profondita o un limite di pagine configurabile e restituisce i risultati come HTML, Markdown o JSON strutturato alimentato da Workers AI. Cloudflare lo posiziona come uno strumento per addestrare modelli, costruire pipeline RAG e ricercare o monitorare contenuti su un sito.
L’endpoint opera come un agente firmato che rispetta robots.txt e il controllo AI Crawl di Cloudflare per impostazione predefinita, una scelta di design degna di nota. E pensato per rendere facile per gli sviluppatori conformarsi alle regole dei siti web e piu difficile per i crawler ignorare le indicazioni dei proprietari dei siti.
L’endpoint si trova a:
https://api.cloudflare.com/client/v4/accounts/<account_id>/browser-rendering/crawl
Hai bisogno di un token API Cloudflare con permesso Browser Rendering Edit per utilizzarlo.
Come funziona
Il crawl viene eseguito come un job asincrono in due passaggi:
- Avvia il crawl con una richiesta POST contenente un URL di partenza. L’API restituisce immediatamente un job ID.
- Interroga per i risultati con richieste GET usando quel job ID. Quando lo stato del job cambia da
runningacompleted, i dati del crawl sono pronti.
I job possono essere eseguiti fino a sette giorni. I risultati vengono conservati per 14 giorni dopo il completamento.
Cosa invii
Come minimo, invii un URL:
curl -X POST 'https://api.cloudflare.com/client/v4/accounts/{account_id}/browser-rendering/crawl' \
-H 'Authorization: Bearer <apiToken>' \
-H 'Content-Type: application/json' \
-d '{
"url": "https://example.com"
}'
Parametri principali
| Parametro | Predefinito | Cosa fa |
|---|---|---|
limit |
10 | Numero massimo di pagine da analizzare (fino a 100.000) |
depth |
100.000 | Profondita massima dei link dall’URL di partenza |
source |
all |
Dove scoprire gli URL: all, sitemaps o links |
formats |
HTML | Formato della risposta: html, markdown o json |
render |
true | Esegui JavaScript (true) o fetch HTML veloce (false) |
maxAge |
86.400 | TTL della cache in secondi (massimo 604.800) |
modifiedSince |
nessuno | Timestamp Unix: analizza solo le pagine modificate dopo questo momento |
options.includePatterns |
nessuno | Analizza solo gli URL che corrispondono a questi pattern con wildcard |
options.excludePatterns |
nessuno | Salta gli URL che corrispondono a questi pattern |
Cosa ottieni in risposta
Ogni pagina analizzata viene restituita come un record con l’URL, lo stato, il contenuto nel formato scelto e metadati base (codice di stato HTTP, titolo della pagina, URL finale dopo i redirect). Con render: true, ottieni anche i tag Open Graph. La risposta include anche browserSecondsUsed per la visibilita sulla fatturazione e un cursor per paginare i risultati che superano i 10 MB.
Ecco la risposta effettiva a livello di job da un crawl con rendering di 24 pagine di un negozio Shopify reale:
{
"job_id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890",
"status": "completed",
"total": 24,
"finished": 24,
"browserSecondsUsed": 58.38,
"record_count": 24,
"records": [
{
"url": "https://www.example-store.com/products/premium-widget-bundle",
"status": "completed",
"metadata": {
"status": 200,
"title": "Premium Widget Bundle | Example Store",
"url": "https://www.example-store.com/products/premium-widget-bundle",
"lastModified": "",
"og:type": "product",
"og:site_name": "Example Store",
"og:title": "Premium Widget Bundle | Example Store",
"og:image": "https://www.example-store.com/cdn/shop/files/product-image.jpg",
"og:description": "Our best-selling bundle with everything you need..."
},
"markdown": "Store\n\nexample-store\n\nURL\n\nhttps://www.example-store.com\n\nCurrency\n\nUSD\n\n# Premium Widget Bundle\n\nOur best-selling bundle with everything you need..."
}
]
}
Con render: true, l’oggetto metadata include l’intero set di campi Open Graph: tipo, nome del sito, titolo, URL dell’immagine e descrizione. Questi vengono estratti dai meta tag OG della pagina durante il rendering del browser. Con render: false, i metadati contengono solo il codice di stato HTTP, il titolo della pagina e l’URL finale. Nessun campo Open Graph viene estratto.
Il campo markdown contiene l’intero output della pagina, non solo il contenuto principale. Menu di navigazione, mega menu, footer e blocchi di template ripetuti sono tutti inclusi in ogni record. Nei nostri test, la pagina media ha restituito circa 158 KB di markdown, con circa il 90% di boilerplate ripetuto. Se stai alimentando questo contenuto in un LLM o una pipeline RAG, avrai bisogno della tua logica di estrazione dei contenuti per eliminare il template e isolare il contenuto effettivo della pagina.
Ecco cosa ha restituito lo stesso negozio quando abbiamo eseguito render: false:
{
"job_id": "f9e8d7c6-b5a4-3210-fedc-ba9876543210",
"status": "completed",
"total": 266,
"finished": 266,
"browserSecondsUsed": 0,
"record_count": 256,
"records": [
{
"url": "https://www.example-store.com/products/classic-knit-sweater",
"status": "completed",
"metadata": {
"status": 200,
"title": "Classic Knit Sweater | Example Store",
"url": "https://www.example-store.com/products/classic-knit-sweater",
"lastModified": ""
},
"markdown": "Skip to content\n\nFree Shipping $150+\n\n# Classic Knit Sweater\n\nOur best-selling sweater made from premium natural fibers..."
}
]
}
Zero secondi di browser, 256 record su 266 pagine. I metadati sono minimi rispetto alla versione con rendering: nessun campo Open Graph, solo lo stato HTTP, il titolo della pagina e l’URL. Ma il markdown contiene comunque l’intero contenuto della pagina inclusi navigazione, dettagli prodotto e footer. Per i negozi Shopify con rendering lato server, l’HTML statico contiene gia tutto cio di cui hai bisogno.
Scoperta degli URL
Il crawler scopre gli URL attraverso tre fonti (quando source e impostato su all):
- L’URL di partenza che fornisci
- I link delle sitemap trovati sul dominio
- I link interni trovati nelle pagine analizzate
Puoi limitare questo alle sole sitemap o ai soli link delle pagine usando il parametro source. excludePatterns ha sempre la priorita su includePatterns, cosi puoi lanciare una rete ampia e poi escludere le sezioni che non ti servono.
Rendering vs. Fetch veloce
render: true (il valore predefinito) avvia un browser headless, esegue JavaScript e attende il caricamento completo della pagina. Questo e necessario per le applicazioni a pagina singola e i contenuti renderizzati via JavaScript, ma usa secondi di browser che vengono fatturati.
render: false esegue un fetch HTML veloce senza eseguire JavaScript. Durante la beta, questi fetch non vengono fatturati. Questa e la scelta giusta per siti statici o pagine renderizzate lato server dove il contenuto e gia nell’HTML iniziale.
Fatturazione e disponibilita
L’endpoint e disponibile sia sui piani Workers Free che Paid. I crawl con rendering vengono fatturati secondo il pricing Browser Rendering di Cloudflare a $0,09 per ora di browser oltre la tua allocazione inclusa.
Workers Free: 10 minuti di tempo browser al giorno. L’endpoint /crawl e limitato a 5 job al giorno, 100 pagine per crawl e 6 richieste API al minuto.
Workers Paid ($5/mese): 10 ore di tempo browser al mese incluse. Nessun limite di pagine per crawl. 600 richieste API al minuto. Le ore di browser aggiuntive costano $0,09 ciascuna.
I crawl con render: false usano zero tempo browser. Sono gratuiti durante la beta ma alla fine ricadranno sotto il pricing standard dei Workers.
Cos’e il tempo reale (Wall Clock Time)?
Il tempo reale e il tempo totale trascorso dall’inizio di un crawl al suo completamento, misurato nello stesso modo in cui lo misureresti con un cronometro. Include tutto: latenza di rete, tempo di coda interno di Cloudflare, ricerche DNS, tempo di risposta del server e (se il rendering e abilitato) tempo di esecuzione del browser.
Il tempo reale e diverso dal tempo browser. Il tempo browser conta solo i secondi in cui il browser headless di Cloudflare trascorre attivamente a renderizzare le pagine. Un crawl potrebbe usare 22 minuti di tempo browser ma richiedere 25 minuti di tempo reale a causa dell’overhead di coda e rete. I crawl senza rendering usano zero tempo browser ma hanno comunque un tempo reale dal processo di fetch e coda.
Nei nostri benchmark, riportiamo entrambi i numeri cosi puoi vedere per cosa stai pagando (tempo browser) rispetto a quanto stai effettivamente aspettando (tempo reale).
Le clausole
L’endpoint rispetta le direttive robots.txt incluso crawl-delay. Si identifica come CloudflareBrowserRenderingCrawler/1.0. Non aggira CAPTCHA, sfide Turnstile o altre protezioni anti-bot. Se stai facendo crawling del tuo sito e vieni bloccato, devi creare una regola WAF skip per inserire il crawler in whitelist.
Come si comporta Cloudflare /crawl su cinque negozi Shopify
Abbiamo eseguito l’endpoint /crawl su cinque negozi Shopify reali per misurare velocita, tasso di successo, costo e come il crawler interagisce con ciascun sito. Ogni nome di negozio e anonimizzato. Questi sono numeri reali da crawl reali. I tempi reali sono stime approssimative. Alcuni test iniziali utilizzavano script con gestione degli errori limitata, che potrebbe aver influenzato i tassi di successo riportati su alcuni negozi. Dove applicabile, lo segnaliamo di seguito.
Questo non e un endpoint da configurare e dimenticare. Ogni negozio ha risposto diversamente alle richieste dell’endpoint. Alcuni necessitavano del blocco delle risorse per completare un crawl con rendering. Altri restituivano errori 429 in una modalita ma funzionavano perfettamente nell’altra. Le direttive crawl-delay, il numero di pagine e l’architettura del negozio hanno tutti cambiato il risultato. Pianifica di testare e regolare le impostazioni per ogni sito che analizzi.
Test 1: Catalogo e-commerce grande (Store A)
Abbiamo puntato l’endpoint /crawl su un grande negozio Shopify con quasi 3.000 pagine. I contenuti sono arrivati velocemente, il markdown era utilizzabile e l’endpoint non ha avuto problemi a recuperare pagine prodotto, pagine di collezione e contenuti del blog. Nessun problema con i proxy, nessun blocco, nessun rate limiting.
Abbiamo eseguito piu crawl a diverse scale:
| Dimensione crawl | Pagine restituite | Modalita | Tempo browser | Tempo reale |
|---|---|---|---|---|
| Campione da 20 pagine | 20 / 20 (100%) | no-render | 0s | ~1 min |
| Crawl da 500 pagine | 500 / 500 (100%) | no-render | 0s | ~18 min |
| 5 pagine con rendering | 4 / 5 (80%) | render: true | 0,9s | ~10s |
Il crawling senza rendering JavaScript ha raggiunto il 100% di successo a entrambe le scale. Il rendering completo del browser ha restituito 4 su 5 pagine in un piccolo test campione. Su un campione cosi piccolo, la singola pagina mancante potrebbe essere un timeout del browser, un errore transitorio o un problema lato script.
Test 2: Negozio Shopify piccolo (Store D, 24 pagine)
Un negozio piu piccolo dove abbiamo testato il flusso di lavoro completo:
Il crawling senza rendering ha restituito errori. Il nostro test iniziale ha restituito risposte 429 sul fetch HTML semplice. Non abbiamo ritestato questo negozio con una gestione degli errori migliorata, quindi non possiamo confermare se i 429 provenivano dal rate limiting del negozio o da problemi transitori durante il test.
Il rendering completo con scoperta basata sulle sitemap e stato un successo completo. 24 su 24 pagine analizzate, completamento al 100%.
| Tipo di pagina | Conteggio |
|---|---|
| Prodotti | 9 |
| Collezioni | 4 |
| Pagine | 3 |
| Blog/News | 5 |
| Altro (homepage, indice blog) | 3 |
Una scoperta importante: la modalita predefinita di scoperta degli URL ha trovato solo 1 pagina perche la homepage aveva pochissimi link interni. Passando alla scoperta basata sulle sitemap sono state trovate tutte le 24 pagine. Se la tua homepage e minimalista o pesante in JavaScript, il crawler potrebbe non trovare pagine solo attraverso i link.
Test 3: Negozio di abbigliamento medio (Store B, 256 pagine), con e senza rendering
Il nostro test piu dettagliato. Un negozio di abbigliamento medio con 256 pagine indicizzabili: prodotti, collezioni, articoli del blog e pagine informative. Abbiamo eseguito entrambe le modalita sull’intero sito per misurare la differenza effettiva.
| Metrica | render: false | render: true | Differenza |
|---|---|---|---|
| Pagine analizzate | 256 / 266 | 256 / 266 | Uguale |
| Output markdown totale | 11,0 MB | 12,5 MB | +14% |
| Tempo browser | 0s | 1.338s (22 min) | +22 min |
| Costo stimato | $0 (beta) | ~$0,03 | +$0,03 |
| Tempo reale | ~5 min | ~25 min | 5 volte piu lento |
Test 4: Rivenditore di salute e integratori (Store C), successo parziale su larga scala
Un grande rivenditore di prodotti per la salute con un catalogo molto ampio. Abbiamo eseguito due crawl senza rendering a scale diverse:
| Dimensione crawl | Pagine restituite | Tasso di successo | Tempo reale |
|---|---|---|---|
| Campione da 5 pagine | 2 / 5 | 40% | ~25s |
| Crawl da 100 pagine | 89 / 100 | 89% | ~3,5 min |
Il tasso di successo parziale potrebbe indicare che l’infrastruttura di questo negozio rifiuta alcune richieste non provenienti da browser, ma il nostro test iniziale mancava di un robusto recupero degli errori, quindi alcuni di questi fallimenti potrebbero essere stati recuperabili con una migliore gestione dei tentativi da parte nostra. Il tasso di successo e migliorato dal 40% all'89% su scala maggiore. Non abbiamo ritestato questo negozio con una gestione degli errori migliorata per isolare la causa.
Test 5: Negozio multi-categoria grande (Store E, ~1.200 pagine)
Il nostro test piu grande e rivelatore. Un negozio Shopify con circa 1.200 URL distribuiti su quattro sitemap: 521 prodotti, 626 collezioni, 22 pagine e 31 articoli del blog.
| Metrica | render: false | render: true (ottimizzato) |
|---|---|---|
| Pagine analizzate | 1.200 / 1.200 | 100 / 100 |
| Output markdown totale | 148,5 MB | 11,3 MB |
| Tempo browser | 0s | 475s (~8 min) |
| Costo stimato | $0 (beta) | ~$0,012 |
| Tempo reale | ~55 min | ~12 min |
Il crawl senza rendering ha raggiunto il 100% di successo su tutte le 1.200 pagine con zero costo browser. Il crawl con rendering e stato eseguito su un campione di 100 pagine con ottimizzazioni di blocco delle risorse abilitate.
Il blocco delle risorse ha fatto la differenza tra un crawl bloccato e uno pulito. Senza blocco delle risorse, il crawl con rendering si e bloccato a 99 su 100 pagine a tempo indefinito e ha consumato 649 secondi di tempo browser per quelle 99 pagine. Abilitando il blocco delle risorse (immagini, media, font, fogli di stile) con una condizione di attesa domcontentloaded, tutte le 100 pagine sono state completate in 475 secondi, una riduzione del 27% nel tempo browser senza blocchi.
Il crawl-delay nel robots.txt ha creato stalli visibili. Il robots.txt di Store E specifica un crawl-delay di 10 secondi per certi bot. Nei nostri dati di polling senza rendering, questo appariva come plateau di piu minuti in cui il conteggio delle pagine si bloccava prima di riprendere. Il crawler di Cloudflare rispetta le direttive crawl-delay, il che estende direttamente il tempo reale sui siti che le impostano.
Cosa accetta effettivamente l’endpoint /crawl
L’endpoint accetta un singolo URL di partenza, non un elenco. Scopre le pagine esplorando verso l’esterno da quell’URL attraverso le sitemap, i link delle pagine o entrambi. Se hai gia un elenco di URL da un crawl Scrapy e vuoi usare Cloudflare per la conversione in markdown, dovresti chiamare i distinti endpoint /markdown o /scrape individualmente per ogni URL.
Cosa fa effettivamente Cloudflare /crawl lato server?
Abbiamo estratto i log completi del server durante un crawl completamente renderizzato di Store D (25 pagine) per analizzare l’impronta reale del traffico. I risultati rivelano differenze fondamentali tra il crawling con rendering del browser e il crawling tradizionale dei bot, con effetti collaterali non previsti per analytics, carico del server e monitoraggio del traffico bot.
| Metrica | Valore |
|---|---|
| User-Agent | CloudflareBrowserRenderingCrawler/1.0 (100% degli hit) |
| Finestra di crawl | 134 secondi (~2 minuti) |
| Throughput di picco | 82 richieste/secondo |
| IP unici | 23, su 5 data center Cloudflare |
| Richieste GET | 2.071 |
| Richieste POST | 163 |
| Richieste totali | 2.234 |
| Pagine effettivamente renderizzate | ~25 |
| Richieste per pagina | amplificazione ~89x |
Quanto traffico genera effettivamente un Cloudflare /crawl completamente renderizzato?
La scoperta piu grande: solo l'1,1% delle 2.234 richieste era contenuto effettivo della pagina. L’altro 98,9% era JavaScript, CSS, beacon di analytics, pixel di tracciamento e precaricamenti del checkout attivati dal browser che caricava ogni pagina come farebbe un visitatore reale.
Un bot senza rendering come Amazonbot o ChatGPT-User genera 1 richiesta per pagina. Il browser renderer di Cloudflare ne genera 89.
Cloudflare /crawl gonfia le analytics di Shopify?
Le 163 richieste POST nei nostri log erano interamente endpoint di analytics e tracciamento di Shopify che si attivavano durante il crawl. Sono gli stessi eventi che si attivano quando un cliente reale visita il tuo negozio. Dal punto di vista di Shopify Analytics, il crawler di Cloudflare sembra un visitatore che sfoglia ogni pagina del tuo sito in 2 minuti.
Quanto velocemente Cloudflare /crawl colpisce il tuo server?
Tutte le 2.234 richieste sono atterrate in una finestra di 134 secondi. Il throughput di picco ha raggiunto 82 richieste al secondo. Il crawler ha renderizzato l’intero sito di 25 pagine in poco piu di 2 minuti, ma il server ha visto un burst sostenuto di traffico che non assomiglia per niente ai pattern di navigazione organica.
Per i negozi piccoli, questo e gestibile. Per i negozi piu grandi con migliaia di pagine, l’amplificazione delle richieste (89x per pagina) combinata con il throughput sostenuto potrebbe creare un carico significativo sul server di origine, specialmente se sei su un piano di hosting condiviso o hai rate limiting aggressivo.
Da dove proviene Cloudflare /crawl?
Il crawl e stato distribuito su 5 data center Cloudflare negli USA:
| Data Center | % delle richieste | Posizione |
|---|---|---|
| ATL | 38% | Atlanta |
| ORD | 25% | Chicago |
| MIA | 23% | Miami |
| EWR | 9% | Newark |
| IAD | 5% | Washington DC |
Non si tratta di un singolo server che effettua richieste. Cloudflare distribuisce il carico di lavoro del rendering sulla sua rete edge. Tutti i 23 IP rientravano nel range 104.28.x.x, e lo user-agent era CloudflareBrowserRenderingCrawler/1.0 su ogni singola richiesta.
Quale fingerprint del browser lascia Cloudflare /crawl?
Il renderer invia gli header Sec-Fetch corretti che imitano un vero browser Chrome:
| Header | Valore | Chrome reale? |
|---|---|---|
sec-fetch-dest |
script, document, ecc. |
Si, corrisponde |
sec-fetch-mode |
cors, navigate |
Si, corrisponde |
sec-fetch-site |
same-origin, cross-site |
Si, corrisponde |
sec-ch-ua (Client Hints) |
Non inviato | No, un Chrome reale lo invia |
| Versione HTTP | HTTP/1.1 | No, un Chrome reale negozia HTTP/2 o HTTP/3 |
Due lacune nel fingerprint si distinguono: il renderer omette completamente gli header sec-ch-ua Client Hints (un vero browser Chrome li invia sempre), e tutte le richieste usano HTTP/1.1 invece di HTTP/2 o HTTP/3. Se stai costruendo regole di rilevamento dei bot, questi sono segnali affidabili per distinguere il browser renderer di Cloudflare dal traffico reale dei visitatori.
Come si confronta Cloudflare /crawl con altri bot AI nei log del server?
Abbiamo confrontato il crawl di Cloudflare con altri bot che hanno colpito lo stesso negozio nella stessa finestra di 12 ore:
Amazonbot e ChatGPT-User recuperano HTML grezzo: una richiesta, una pagina, nessuna esecuzione di JavaScript. AhrefsBot analizza le sitemap per la scoperta. Il browser renderer di Cloudflare esegue un intero storefront Shopify su ogni pagina, attivando ogni script, pixel e precaricamento come se un cliente reale stesse navigando.
Velocita e costo di Cloudflare /crawl: il benchmark completo
Ogni crawl che abbiamo eseguito, in una tabella. Tutti i negozi anonimizzati, tutti i numeri da test reali. I tempi reali sono approssimativi. I tassi di successo per Store C e D potrebbero essere stati influenzati dalla gestione degli errori limitata nei nostri script di test iniziali.
| Negozio | Pagine | Modalita | Tasso di successo | Tempo browser | Tempo reale | Costo |
|---|---|---|---|---|---|---|
| A: E-commerce grande | 500 / 500 | no-render | 100% | 0s | ~18 min | $0 |
| B: Abbigliamento medio | 256 / 266 | no-render | 96% | 0s | ~5 min | $0 |
| C: Salute e integratori | 89 / 100 | no-render | 89% | 0s | ~3,5 min | $0 |
| D: Shopify piccolo | 24 / 24 | render: true | 100% | 58s | ~2 min | ~$0,002 |
| E: Multi-categoria grande | 1.200 / 1.200 | no-render | 100% | 0s | ~55 min | $0 |
Quanto e veloce Cloudflare /crawl con vs. senza rendering?
Il confronto piu chiaro viene da Store B, dove abbiamo eseguito entrambe le modalita sulle stesse identiche 256 pagine:
Il pattern in tutti gli undici crawl e coerente: il crawling senza rendering e drammaticamente piu veloce. Il tempo reale senza rendering e principalmente l’overhead interno di coda e fetch di Cloudflare. Il rendering completo aggiunge circa 5 secondi di tempo browser per pagina in aggiunta a quel baseline.
Quanto costa un crawl Cloudflare completamente renderizzato per pagina?
Il pricing del Browser Rendering di Cloudflare si basa sulle ore di browser, il tempo che il loro browser headless trascorre a renderizzare attivamente le tue pagine. Il crawling senza rendering usa zero ore di browser ed e gratuito durante la beta.
Piano Workers Free: 10 minuti di tempo browser al giorno. L’endpoint /crawl e ulteriormente limitato a 5 job di crawl al giorno, con un massimo di 100 pagine per crawl.
Piano Workers Paid ($5/mese): 10 ore di tempo browser al mese incluse. Oltre a questo, paghi $0,09 per ora di browser aggiuntiva. Nessun limite per crawl sull’endpoint /crawl. Fino a 600 richieste API al minuto.
Ecco quanto sono costati effettivamente i nostri crawl di test a $0,09/ora:
| Crawl | Tempo browser utilizzato | Costo a $0,09/ora |
|---|---|---|
| Store D: 24 pagine renderizzate | 58 secondi | ~$0,002 |
| Store B: 256 pagine renderizzate | 1.338 secondi (~22 min) | ~$0,03 |
| Catalogo da 3.000 pagine (stimato) | ~4 ore | ~$0,36 |
A circa 5 secondi di tempo browser per pagina, tutti questi costi rientrano ampiamente nelle 10 ore incluse nel piano paid. Un crawl con rendering di 3.000 pagine userebbe circa 4 delle tue 10 ore incluse, il che significa che potresti eseguire due crawl completi al mese prima di pagare qualcosa oltre i $5 base. Il crawling senza rendering e gratuito e non ha costo di tempo browser su nessuno dei due piani.
Quando dovresti saltare il rendering vs. usare il rendering completo su Cloudflare /crawl?
La conclusione
Per la maggior parte dei negozi Shopify con contenuti renderizzati lato server, il crawling senza rendering ti offre oltre il 90% dei contenuti utili a costo zero in una frazione del tempo.
Cosa abbiamo imparato testando Cloudflare /crawl sui negozi Shopify
Dopo aver eseguito 11 crawl su 5 negozi Shopify reali e analizzato i log completi del server, questi sono i risultati che contano di piu.
Il 90% dei contenuti arriva senza rendering
Per i negozi Shopify con pagine standard renderizzate lato server, il crawling senza rendering JavaScript ha catturato oltre il 90% dei contenuti utili. L’aumento del 14% dei contenuti dal rendering completo proveniva quasi interamente da elementi caricati via JavaScript nelle homepage e nelle pagine indice. Le singole pagine prodotto e gli articoli del blog erano quasi identici in entrambi i casi. A meno che il tuo negozio non sia costruito come una applicazione a pagina singola, probabilmente non hai bisogno del rendering completo.
Il rendering completo crea un moltiplicatore di traffico di 89x
Il rendering di 25 pagine ha generato 2.234 richieste server. Solo 25 di queste erano contenuto effettivo della pagina. L’altro 98,9% era costituito da file JavaScript (75%), beacon di analytics (6,3%), CSS (4,3%), pixel di tracciamento (3,4%) e precaricamenti del checkout (3,3%). Ogni pagina renderizzata attiva l’intero stack lato client di Shopify come se un cliente reale stesse navigando.
Le tue analytics di Shopify vengono probabilmente gonfiate
I crawl con rendering attivano l’intero stack di analytics di Shopify: beacon monorail, eventi di tracciamento, precaricamenti Shop Pay e script web-pixel. Riteniamo che questo significhi che Shopify Analytics conta queste come sessioni reali di visitatori. Se cosi fosse, un singolo crawl con rendering potrebbe gonfiare i conteggi delle sessioni, le visualizzazioni di pagina e i dati del funnel di conversione. Non lo abbiamo confermato direttamente nei report di Shopify, ma i log del server mostrano tutti gli stessi eventi di analytics che si attiverebbero per un cliente reale.
Il rendering completo puo aggirare i limiti di frequenza del negozio
Store D ha restituito errori 429 su ogni pagina senza rendering. Passando al rendering completo sullo stesso negozio si e ottenuto il 100% di successo. Se incontri limiti di frequenza senza rendering, il rendering completo e la soluzione.
La scoperta tramite sitemap e piu affidabile della scoperta tramite link
La scoperta predefinita basata sui link non ha trovato quasi nulla su Store D perche la homepage aveva pochissimi link interni. Passando alla scoperta basata sulle sitemap sono state trovate tutte le 24 pagine. Usa sempre la scoperta tramite sitemap.
Il crawler proviene da 5 data center negli USA
Cloudflare distribuisce il carico di lavoro del rendering sulla sua rete edge. Il nostro crawl proveniva da 23 IP unici distribuiti tra Atlanta (38%), Chicago (25%), Miami (23%), Newark (9%) e Washington DC (5%). Tutti gli IP rientrano nel range 104.28.x.x.
Due lacune nel fingerprint lo identificano come un bot
Il renderer omette gli header sec-ch-ua Client Hints (un Chrome reale li invia sempre) e usa HTTP/1.1 invece di HTTP/2 o HTTP/3. Se stai costruendo regole di rilevamento dei bot, questi sono segnali affidabili.
Il rendering puo effettivamente restituire meno contenuto
Su Store E, il crawl senza rendering ha restituito il 6,8% di contenuto in piu per pagina rispetto al crawl con rendering. Bloccare immagini, font e fogli di stile per ottimizzare il tempo browser ha anche impedito ad alcuni JavaScript di popolare gli elementi dinamici. L’HTML statico aveva gia tutto. Per i negozi Shopify con rendering lato server, il rendering non garantisce di catturare piu contenuto.
Il blocco delle risorse previene i crawl bloccati
Senza blocco delle risorse, il crawl con rendering su Store E si e bloccato a 99 su 100 pagine senza mai completarsi. Abilitando il blocco per immagini, media, font e fogli di stile con una condizione di attesa domcontentloaded, tutte le 100 pagine sono state completate e il tempo browser si e ridotto del 27%. Se i tuoi crawl con rendering si bloccano prima di finire, il blocco delle risorse e la soluzione.
Il crawl-delay nel robots.txt estende il tempo reale
Il robots.txt di Store E specifica un crawl-delay di 10 secondi. Nei nostri dati di polling senza rendering, questo appariva come plateau di piu minuti in cui il conteggio delle pagine si bloccava prima di riprendere. Il crawler di Cloudflare rispetta le direttive crawl-delay, quindi i siti con ritardi aggressivi avranno tempi reali significativamente piu lunghi di quanto il solo conteggio delle pagine suggerirebbe.
Il costo e basso ma il piano Free ha limiti
Il rendering di 256 pagine e costato circa $0,03 a $0,09 per ora di browser. Il rendering di 24 pagine e costato circa $0,002. Il piano Workers Free limita il tempo browser a 10 minuti al giorno con un massimo di 5 job di crawl e 100 pagine per crawl. Il piano Workers Paid ($5/mese) include 10 ore di tempo browser al mese senza limiti per crawl. Un crawl con rendering di 3.000 pagine userebbe circa 4 di quelle 10 ore incluse, quindi la maggior parte dei negozi rientra comodamente nel piano paid senza eccedenze. Il crawling senza rendering usa zero tempo browser ed e gratuito su entrambi i piani durante la beta.
I pro
Velocita
Le pagine vengono recuperate quasi istantaneamente rispetto a un crawl Scrapy di piu ore con autothrottle. Nessuna coda, nessun ritardo di cortesia, nessuna attesa che il tuo spider lavori attraverso migliaia di richieste a un ritmo rispettoso.
Output Markdown
L’endpoint restituisce la conversione HTML-to-Markdown pre-elaborata per ogni pagina. Questo e direttamente utile per l’ingestione LLM, le pipeline RAG e l’analisi dei contenuti senza alcuna post-elaborazione. Salti l’intero livello di estrazione e vai direttamente al testo pulito. Per i team che costruiscono applicazioni AI sui contenuti dei siti web, questo rimuove un passaggio dalla pipeline.
Opzione modalita rendering
Impostando render: true si esegue JavaScript e si estraggono automaticamente i metadati Open Graph (og:title, og:description, og:image, og:site_name). Per i siti pesanti in JavaScript dove il contenuto viene renderizzato lato client, questa e la differenza tra vedere la pagina reale e vedere un guscio vuoto.
Nessun problema con proxy o limiti di frequenza
Cloudflare gestisce le misure anti-bot e il rate limiting sulla propria infrastruttura. Non devi gestire pool di proxy, ruotare user agent o affrontare CAPTCHA. Una sola chiamata API.
Crawling incrementale
I parametri modifiedSince e maxAge ti permettono di saltare le pagine che non sono cambiate o che sono state recuperate di recente. Per crawl ricorrenti in cui stai monitorando le modifiche ai contenuti, questo risparmia sia tempo che costo elaborando solo le pagine che sono effettivamente nuove o aggiornate.
Semplicita
Una singola chiamata API. Risposta JSON. Nessun codice spider, nessun middleware, nessuna item pipeline, nessun file di configurazione.
Bot ben educato per impostazione predefinita
Il crawler e un agente firmato che rispetta robots.txt, crawl-delay e il controllo AI Crawl di Cloudflare. Si auto-identifica come CloudflareBrowserRenderingCrawler/1.0 e non puo aggirare protezioni bot o CAPTCHA. Ottieni la conformita al crawling etico senza costruire la logica da solo.
Cosa non supporta l’endpoint Cloudflare Crawl
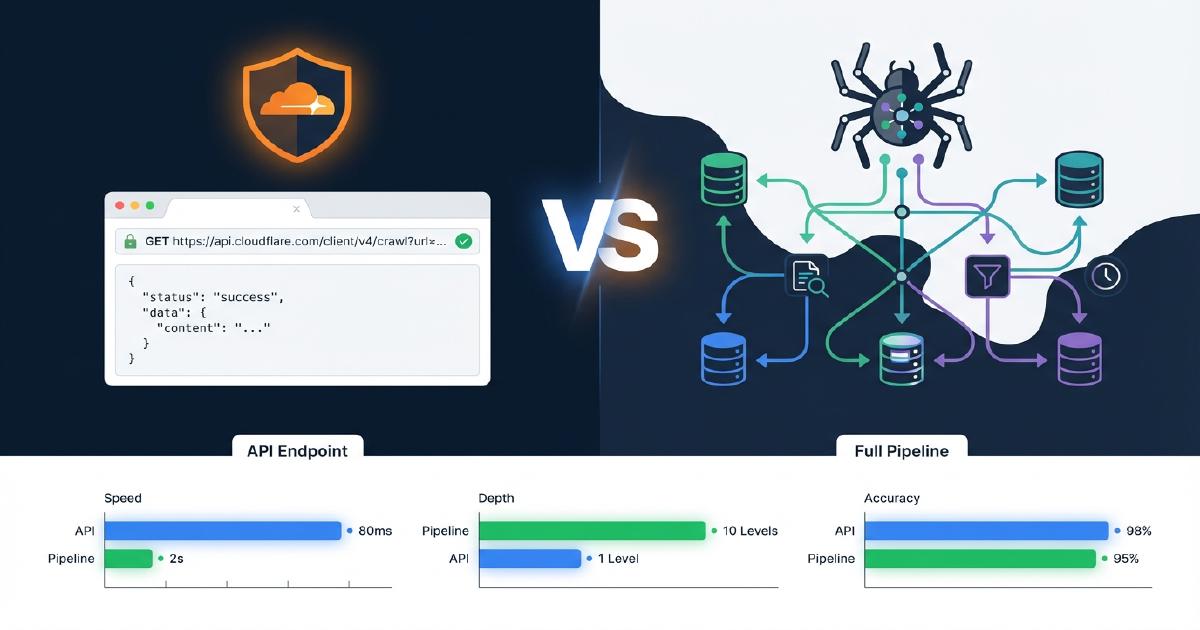
In cosa si differenzia Cloudflare /crawl da una pipeline di crawl completa?
La tabella seguente mostra esattamente quali funzionalita sono presenti nell’endpoint /crawl di Cloudflare rispetto a una pipeline Scrapy di produzione. Questo si basa sui nostri test reali su negozi Shopify.
| Funzionalita | Cloudflare /crawl | Pipeline Scrapy |
|---|---|---|
| Recupero contenuti (HTML/Markdown) | Si | Si |
| Rendering JavaScript | Si (render: true) |
Si (Splash/Playwright) |
| Scoperta link / spidering | Si (lista piatta) | Si (grafo di crawl completo) |
| Mappatura link padre-figlio | No | Si |
| Rilevamento pagine orfane | No | Si |
| Tracciamento catene di redirect | No | Si |
| Estrazione JSON-LD | No | Si |
| Estrazione Microdata | No | Si |
| Validazione schema + report problemi | No | Si |
| Codici di stato non-200 (404, 403) | No | Si (catturati 2.547 404 nel nostro test) |
| Limite URL | 100.000 | Nessuno |
Quali dati strutturati estrae Cloudflare /crawl?
Con render: false, nessuno. Nessun JSON-LD, nessun Microdata, nessun parsing OpenGraph.
Con render: true, solo tag OG base (og:title, og:description, og:image, og:site_name). JSON-LD e il markup schema.org non vengono analizzati, estratti o validati.
Per confronto, la nostra pipeline Scrapy produce schemas_found, issues (contactPoint mancante, address mancante, ecc.), top_level_schemas e nested_schemas per ogni URL. Puoi vedere quali pagine hanno lo schema Product, quali mancano del markup Organization e quali hanno errori di validazione che causerebbero una lettura errata del contenuto da parte dei sistemi AI.
Quali codici di stato HTTP restituisce Cloudflare /crawl?
Solo risposte 200. Il nostro crawl Scrapy dello stesso sito ha catturato 2.547 errori 404, piu risposte 403 e errori di connessione. Il rilevamento dei 404 e critico per l’analisi delle pagine fantasma, la correzione dei link rotti e la mappatura dei redirect. Senza di esso, ti stai perdendo le pagine che stanno attivamente disperdendo link equity e confondendo i crawler AI.
Quanti URL puo elaborare Cloudflare /crawl?
Fino a 100.000 per job. Questo copre la maggior parte dei siti, ma i grandi cataloghi e-commerce con centinaia di migliaia di pagine prodotto, URL di varianti e pagine di collezione filtrate supereranno il limite. Scrapy non ha limiti intrinseci di URL.
Cloudflare /crawl ha un bug nella risoluzione degli URL?
Abbiamo trovato 233 su 908 link in una singola pagina prodotto con percorsi non funzionanti. Il convertitore di markdown risolve gli URL relativi rispetto all’URL della pagina in modo errato, producendo URL con doppio percorso come /products/slug//www.example.com/.... Si tratta di un bug confermato nel convertitore di Cloudflare che influisce su qualsiasi analisi dei link a valle.
Quanto boilerplate c’e nell’output markdown di Cloudflare /crawl?
La pagina media ha restituito 158 KB di markdown. Circa il 90% e contenuto di template ripetuto: navigazione completa, mega menu e footer su ogni singolo record. Per l’analisi dei contenuti questo significa un pesante lavoro di deduplicazione, e per l’uso dei token LLM il costo si accumula rapidamente. Hai bisogno della tua logica di estrazione dei contenuti sopra il markdown per isolare il contenuto effettivo della pagina.
Cosa non classifica Cloudflare /crawl?
Non c’e tagging per tipo di contenuto. Pagine prodotto, pagine di collezione, articoli del blog e homepage tornano tutti come record indifferenziati. Scrapy classifica ogni URL per tipo, il che e essenziale per comprendere la copertura del crawl per categoria di pagina e per identificare quali tipi di contenuto i bot AI danno priorita.
Quali funzionalita di finalizzazione mancano in Cloudflare /crawl?
Nessuno screenshot delle pagine fantasma. Nessun confronto del rendering JavaScript (cosa vede il bot rispetto a cosa vede il browser). Nessuna analisi del robots.txt per bot AI. Nessun report sulla qualita del crawl. Nessun manifesto client. Nessun sync CDN. I dati di Cloudflare sono solo contenuto grezzo. Ogni pezzo della pipeline di reporting e analisi dovrebbe essere costruito separatamente.
Quanto costa Cloudflare /crawl per siti grandi?
Nei nostri test, render: true ha impiegato in media circa 5 secondi di esecuzione browser per pagina. Un crawl di 256 pagine ha usato 1.338 secondi di browser (22 minuti) e e costato circa $0,03 a $0,09 per ora di browser. Un crawl di 24 pagine ha usato 58 secondi di browser e e costato circa $0,002. Estrapolando a un catalogo da 3.000 pagine: circa 4 ore di tempo browser. Il piano Workers Free e limitato a 10 minuti di tempo browser al giorno, 5 job di crawl al giorno e 100 pagine per crawl. Il piano Workers Paid ($5/mese) include 10 ore di tempo browser al mese senza limiti per crawl, quindi un crawl di 3.000 pagine userebbe circa 4 di quelle 10 ore incluse. render: false usa zero tempo browser ed e gratuito durante la beta su entrambi i piani.
La conclusione
L’endpoint crawl di Cloudflare e ottimo per:
- Snapshot rapidi dei contenuti quando hai bisogno del testo della pagina velocemente
- Markdown pronto per LLM per pipeline RAG e ingestione di contenuti
- Controlli ad hoc delle pagine quando conosci gli URL esatti di cui hai bisogno
- Estrazioni rapide dei contenuti del sito quando hai bisogno di testo markdown senza costruire uno spider
Non puo sostituire una pipeline di crawl completa perche il valore della pipeline sta in:
- Grafo di crawl completo con topologia dei link, rilevamento orfani e copertura 404
- Estrazione e validazione dei dati strutturati (JSON-LD, Microdata, OpenGraph)
- Classificazione dei contenuti per tipo di pagina
- L’intera pipeline di finalizzazione inclusa l’analisi delle pagine fantasma, il confronto del rendering JavaScript, i report sugli schema e il punteggio di readiness LLM
L’approccio ibrido migliore
Usa Cloudflare come fonte dati supplementare. Dopo che un crawl completo ha identificato i tuoi URL, usa l’output markdown di Cloudflare per alimentare il punteggio di readiness LLM o l’analisi della qualita dei contenuti dove hai bisogno del testo effettivo della pagina piuttosto che dei metadati strutturati. La pipeline di crawl scopre e classifica. L’endpoint Cloudflare fornisce testo pulito per le pagine che contano.
Vuoi vedere la pipeline di crawl completa in azione?
Prenota una chiamataDomande frequenti
Quali funzionalita di audit del sito non sono supportate da Cloudflare /crawl?
Cloudflare /crawl non supporta: costruzione completa del grafo di crawl, mappatura dei link padre-figlio, rilevamento delle pagine orfane, tracciamento delle catene di redirect, estrazione di JSON-LD o Microdata, validazione degli schema, cattura dei codici di stato non-200 (404, 403), classificazione per tipo di contenuto, misurazione delle dimensioni delle pagine in byte, rilevamento delle pagine fantasma, confronto del rendering JS vs HTML, analisi del robots.txt per bot AI, o cross-referencing dei backlink. E un fetcher di contenuti, non uno strumento di audit del sito.
In cosa si differenzia Cloudflare /crawl da Scrapy per il crawling di e-commerce?
Cloudflare /crawl recupera i contenuti velocemente senza infrastruttura da gestire. Scrapy costruisce un grafo di crawl completo con la topologia dei link, estrae e valida i dati strutturati (JSON-LD, Microdata, OpenGraph), cattura tutti i codici di stato HTTP inclusi i 404, classifica le pagine per tipo di contenuto e alimenta una pipeline a valle per l'analisi delle pagine fantasma, i report sugli schema e il punteggio di readiness per LLM. Cloudflare ti da il testo della pagina; Scrapy ti da l'intera architettura del sito.
Qual e il limite esatto di URL per Cloudflare /crawl?
100.000 URL per job di crawl. Il limit predefinito e 10, quindi devi impostarlo esplicitamente. Anche la depth massima e 100.000. Per i siti che superano le 100K pagine, serve Scrapy o un altro crawler senza limiti intrinseci di URL.
Cloudflare /crawl estrae JSON-LD o valida il markup schema?
No. Con render: false, nessun dato strutturato viene estratto. Con render: true, vengono restituiti solo i tag Open Graph base (og:title, og:description, og:image, og:site_name). JSON-LD, Microdata e il markup schema.org non vengono analizzati, estratti o validati in nessuna delle due modalita.
Quanto costa Cloudflare /crawl per il rendering di siti grandi?
Nei nostri test, render: true ha impiegato in media circa 5 secondi di tempo browser per pagina. Un sito da 256 pagine ha usato 1.338 secondi di browser (22 minuti) e e costato circa $0,03 a $0,09 per ora di browser. Un sito da 24 pagine ha usato 58 secondi e e costato circa $0,002. Estrapolando a un catalogo da 3.000 pagine: circa 4 ore di tempo browser. Il piano Workers Free e limitato a 10 minuti al giorno, 5 job di crawl al giorno e 100 pagine per crawl, quindi i crawl con rendering di grandi dimensioni richiedono il piano Workers Paid ($5/mese), che include 10 ore di tempo browser al mese senza limiti per crawl. render: false usa zero tempo browser ed e gratuito durante la beta su entrambi i piani.
Cloudflare /crawl ha un bug noto nella risoluzione degli URL?
Si. Nel nostro test, 233 su 908 link in una singola pagina prodotto avevano percorsi malformati. Il convertitore di markdown antepone l'URL della pagina ai percorsi relativi come //www.example.com/cdn/..., creando URL con doppio percorso non funzionanti. Questo influisce su qualsiasi analisi del grafo dei link o audit dei link interni costruita dall'output markdown.
Perche Cloudflare /crawl con render false restituisce errori 429 su alcuni negozi Shopify?
render: false esegue un fetch HTML grezzo senza browser headless. In uno dei nostri test, render: false ha restituito errori 429 mentre render: true ha funzionato con successo al 100% sullo stesso negozio. Non abbiamo ritestato con gestione degli errori migliorata, quindi i 429 potrebbero essere stati causati dal rate limiting del negozio, da problemi API transitori o da una combinazione. Se riscontri errori 429 senza rendering, prova render: true come primo passo.
Cloudflare /crawl accetta un elenco di URL?
No. L'endpoint accetta un singolo URL di partenza e scopre le pagine esplorando verso l'esterno attraverso le sitemap, i link delle pagine o entrambi. Se hai gia un elenco di URL e vuoi la conversione markdown di Cloudflare, usa i distinti endpoint /markdown o /scrape, che accettano singoli URL per richiesta.
Perche Cloudflare /crawl con source all trova solo una pagina su alcuni siti?
L'impostazione predefinita source: all scopre gli URL sia dalle sitemap che dai link delle pagine. Se l'URL di partenza ha pochissimi link interni (comune nelle homepage minimaliste o nelle SPA pesanti in JavaScript), il crawler potrebbe non trovare pagine aggiuntive solo tramite la scoperta dei link. Passa a source: sitemaps per assicurarti che il crawler legga l'intero sitemap.xml e scopra tutti gli URL elencati.
Qual e il modo migliore per usare Cloudflare /crawl con una pipeline di crawl completa?
Usa prima la pipeline di crawl completa (Scrapy o equivalente) per scoprire gli URL, costruire il grafo dei link, estrarre i dati strutturati, catturare i 404 e classificare i contenuti. Poi usa gli endpoint /markdown o /scrape di Cloudflare per ottenere markdown pulito per il punteggio di readiness LLM, l'analisi della qualita dei contenuti o l'ingestione RAG dove hai bisogno del testo effettivo della pagina piuttosto che dei metadati strutturati.
Quanto e piu veloce Cloudflare /crawl render false rispetto a render true?
Nel nostro test diretto sullo stesso sito da 256 pagine, render: false ha completato in circa 5 minuti. render: true ha impiegato circa 25 minuti per le stesse pagine. Si tratta di una differenza di velocita di 5x. Il divario nel tempo reale deriva da circa 5 secondi di esecuzione del browser aggiunti per pagina quando il rendering e abilitato. render: false e costato $0 durante la beta. render: true e costato circa $0,03 per lo stesso crawl.
Quanto contenuto in piu cattura Cloudflare /crawl render true rispetto a render false?
Nel nostro test su 256 pagine, render: true ha prodotto 12,5 MB di markdown contro 11,0 MB da render: false, un aumento del 14%. Il contenuto extra proveniva quasi interamente da elementi caricati via JavaScript nella homepage e nelle pagine indice del blog. Le singole pagine prodotto e gli articoli del blog erano quasi identici tra le due modalita. Per i siti con contenuti prevalentemente renderizzati lato server, render: false cattura oltre il 90% del testo utile a costo zero e con velocita 5 volte superiore.
Cloudflare /crawl funziona in modo affidabile su tutti i negozi Shopify?
Dipende dal negozio e dalla modalita di rendering. Nei nostri test su cinque negozi Shopify: Store A (catalogo grande) ha raggiunto il 100% di successo con render: false. Store B (abbigliamento medio) ha raggiunto il 96% di successo con entrambe le modalita. Store C (salute e integratori) ha raggiunto il 40% su un campione di 5 pagine e l'89% su un crawl di 100 pagine con render: false, sebbene il nostro test iniziale mancasse di un robusto recupero degli errori e alcuni fallimenti potrebbero essere stati recuperabili. Store D (negozio piccolo) ha restituito errori 429 con render: false ma ha raggiunto il 100% con render: true. Store E (multi-categoria grande, ~1.200 pagine) ha raggiunto il 100% di successo con render: false e il 100% su un campione di 100 pagine renderizzate con ottimizzazioni di blocco delle risorse. Non abbiamo ritestato Store C e D con gestione degli errori migliorata. Testa entrambe le modalita sul tuo negozio specifico prima di adottare una strategia di crawl.
Qual e il tempo reale per un Cloudflare /crawl di 500 pagine con render false?
Nel nostro test, un crawl render: false di 500 pagine ha completato in circa 18 minuti con un tasso di successo del 100%. Un crawl di 256 pagine su un altro negozio ha completato in circa 5 minuti. Un crawl di 100 pagine ha completato in circa 3,5 minuti. Questi tempi reali sono stime basate sugli intervalli di polling, non misurazioni precise. Il tempo reale e principalmente l'overhead interno di coda e fetch HTTP di Cloudflare, non il rendering del browser, poiche nessun secondo di browser viene utilizzato con render: false.
Quante richieste server genera un Cloudflare /crawl render true?
Nella nostra analisi dei log del server, un singolo crawl render: true di 25 pagine ha generato 2.234 richieste totali: 2.071 GET e 163 POST. Si tratta di circa 89 richieste server per pagina effettivamente renderizzata. Solo l'1,1% delle richieste era contenuto effettivo della pagina. Il restante 98,9% era costituito da file JavaScript (75%), beacon di analytics (6,3%), CSS (4,3%), pixel di tracciamento (3,4%) e precaricamenti del checkout (3,3%). Se stai monitorando il traffico bot o gestendo il carico del server, aspettati che un crawl con rendering generi 89 volte il numero di richieste di pagina effettive nei tuoi log del server.
Quale user-agent usa Cloudflare /crawl e da quale range di IP proviene?
Il crawler si identifica come CloudflareBrowserRenderingCrawler/1.0 sul 100% delle richieste. Nei nostri log, tutte le richieste provenivano da 23 IP unici nel range 104.28.x.x distribuiti su 5 data center Cloudflare negli USA: ATL (38%), ORD (25%), MIA (23%), EWR (9%) e IAD (5%). Non c'e rotazione dello user-agent o mascheramento degli IP. Il crawler e un bot firmato e identificabile per design.
Cloudflare /crawl gonfia le analytics e i conteggi dei visitatori di Shopify?
Lo riteniamo probabile, ma non lo abbiamo confermato direttamente nei report di Shopify. Poiche render: true esegue JavaScript, attiva l'intero stack di analytics di Shopify su ogni pagina: beacon monorail, eventi di tracciamento /api/collect, precaricamenti del checkout Shop Pay e script web-pixel sandbox. Nel nostro test, 163 su 2.234 richieste erano richieste POST verso endpoint di analytics di Shopify. Sono gli stessi eventi che si attivano per i clienti reali. Se Shopify li conta come sessioni reali, i conteggi delle sessioni, le visualizzazioni di pagina e i dati del funnel di conversione risulterebbero gonfiati.
Come si puo rilevare Cloudflare /crawl nei log del server rispetto al traffico reale del browser?
Due lacune affidabili nel fingerprint: il browser renderer di Cloudflare omette gli header sec-ch-ua Client Hints (un vero browser Chrome li invia sempre), e tutte le richieste usano HTTP/1.1 invece di HTTP/2 o HTTP/3 che un browser reale negozierebbe. Invia correttamente gli header sec-fetch-dest, sec-fetch-mode e sec-fetch-site che corrispondono a un Chrome reale. Lo user-agent e sempre CloudflareBrowserRenderingCrawler/1.0 e tutti gli IP rientrano nel range 104.28.x.x.