
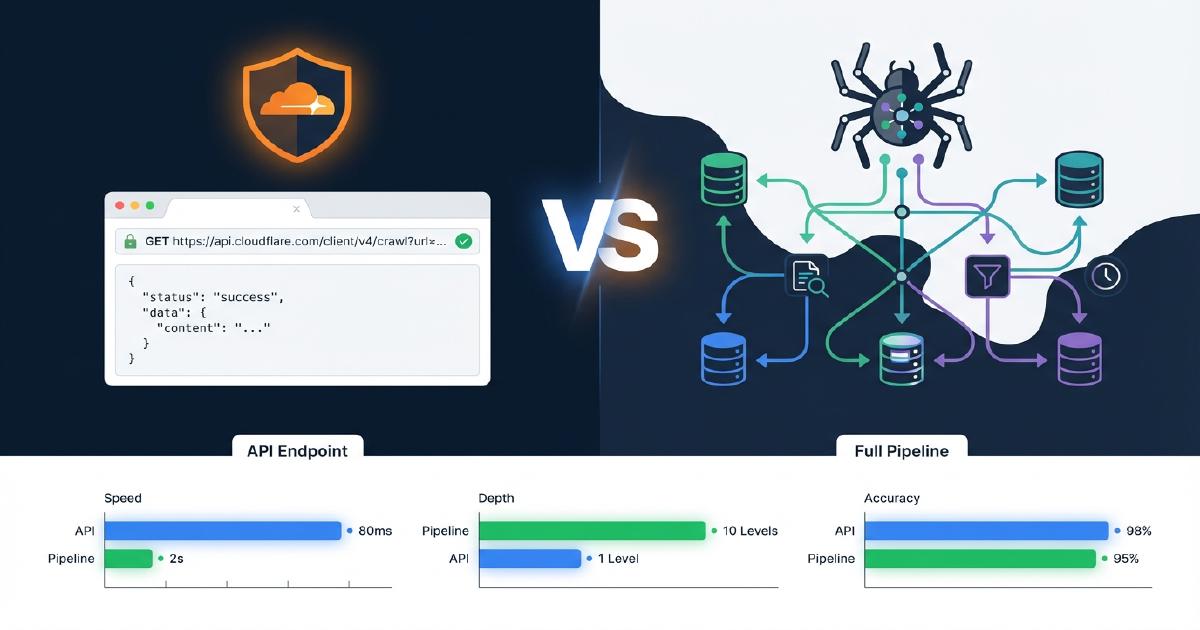
Que es el endpoint /crawl de Cloudflare?
El endpoint /crawl de Cloudflare es parte de su API de Browser Rendering, actualmente en beta abierta. Extrae contenido de una URL de inicio, sigue enlaces a traves del sitio hasta una profundidad o limite de paginas configurable, y devuelve los resultados como HTML, Markdown o JSON estructurado impulsado por Workers AI. Cloudflare lo posiciona como una herramienta para entrenar modelos, construir pipelines RAG e investigar o monitorear contenido en un sitio.
El endpoint opera como un agente firmado que respeta robots.txt y el AI Crawl Control de Cloudflare por defecto, lo cual es una decision de diseno notable. Esta pensado para facilitar que los desarrolladores cumplan con las reglas del sitio web y dificultar que los rastreadores ignoren las directrices del propietario del sitio.
El endpoint se encuentra en:
https://api.cloudflare.com/client/v4/accounts/<account_id>/browser-rendering/crawl
Necesitas un token de API de Cloudflare con permiso de Browser Rendering Edit para usarlo.
Como funciona
El rastreo se ejecuta como un trabajo asincrono en dos pasos:
- Inicia el rastreo con una solicitud POST que contiene una URL de inicio. La API devuelve un ID de trabajo inmediatamente.
- Consulta los resultados con solicitudes GET usando ese ID de trabajo. Cuando el estado del trabajo cambia de
runningacompleted, tus datos rastreados estan listos.
Los trabajos pueden ejecutarse hasta siete dias. Los resultados se almacenan durante 14 dias despues de completarse.
Que envias
Como minimo, envias una URL:
curl -X POST 'https://api.cloudflare.com/client/v4/accounts/{account_id}/browser-rendering/crawl' \
-H 'Authorization: Bearer <apiToken>' \
-H 'Content-Type: application/json' \
-d '{
"url": "https://example.com"
}'
Parametros clave
| Parametro | Predeterminado | Que hace |
|---|---|---|
limit |
10 | Paginas maximas a rastrear (hasta 100,000) |
depth |
100,000 | Profundidad maxima de enlaces desde la URL de inicio |
source |
all |
Donde descubrir URLs: all, sitemaps o links |
formats |
HTML | Formato de respuesta: html, markdown o json |
render |
true | Ejecutar JavaScript (true) u obtencion rapida de HTML (false) |
maxAge |
86,400 | TTL de cache en segundos (maximo 604,800) |
modifiedSince |
ninguno | Marca de tiempo Unix: solo rastrear paginas modificadas despues de este momento |
options.includePatterns |
ninguno | Solo rastrear URLs que coincidan con estos patrones comodin |
options.excludePatterns |
ninguno | Omitir URLs que coincidan con estos patrones |
Que obtienes de vuelta
Cada pagina rastreada se devuelve como un registro con la URL, el estado, el contenido en el formato elegido y metadatos basicos (codigo de estado HTTP, titulo de la pagina, URL final despues de redirecciones). Con render: true, tambien obtienes etiquetas Open Graph. La respuesta tambien incluye browserSecondsUsed para visibilidad de facturacion, y un cursor para paginar resultados que excedan 10 MB.
Aqui esta la respuesta real a nivel de trabajo de un rastreo renderizado de 24 paginas de una tienda Shopify en produccion:
{
"job_id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890",
"status": "completed",
"total": 24,
"finished": 24,
"browserSecondsUsed": 58.38,
"record_count": 24,
"records": [
{
"url": "https://www.example-store.com/products/premium-widget-bundle",
"status": "completed",
"metadata": {
"status": 200,
"title": "Premium Widget Bundle | Example Store",
"url": "https://www.example-store.com/products/premium-widget-bundle",
"lastModified": "",
"og:type": "product",
"og:site_name": "Example Store",
"og:title": "Premium Widget Bundle | Example Store",
"og:image": "https://www.example-store.com/cdn/shop/files/product-image.jpg",
"og:description": "Our best-selling bundle with everything you need..."
},
"markdown": "Store\n\nexample-store\n\nURL\n\nhttps://www.example-store.com\n\nCurrency\n\nUSD\n\n# Premium Widget Bundle\n\nOur best-selling bundle with everything you need..."
}
]
}
Con render: true, el objeto de metadatos incluye el conjunto completo de campos Open Graph: tipo, nombre del sitio, titulo, URL de imagen y descripcion. Estos se extraen de las metaetiquetas OG de la pagina durante el renderizado del navegador. Con render: false, los metadatos solo contienen el codigo de estado HTTP, el titulo de la pagina y la URL final. No se extraen campos Open Graph.
El campo markdown contiene la salida completa de la pagina, no solo el contenido principal. Los menus de navegacion, mega menus, pies de pagina y bloques de plantilla repetidos se incluyen en cada registro. En nuestras pruebas, la pagina promedio devolvio aproximadamente 158 KB de markdown, con aproximadamente el 90% siendo boilerplate repetido. Si estas alimentando esto en un LLM o pipeline RAG, necesitaras tu propia logica de extraccion de contenido para eliminar la plantilla y aislar el contenido real de la pagina.
Aqui esta lo que devolvio la misma tienda cuando ejecutamos render: false:
{
"job_id": "f9e8d7c6-b5a4-3210-fedc-ba9876543210",
"status": "completed",
"total": 266,
"finished": 266,
"browserSecondsUsed": 0,
"record_count": 256,
"records": [
{
"url": "https://www.example-store.com/products/classic-knit-sweater",
"status": "completed",
"metadata": {
"status": 200,
"title": "Classic Knit Sweater | Example Store",
"url": "https://www.example-store.com/products/classic-knit-sweater",
"lastModified": ""
},
"markdown": "Skip to content\n\nFree Shipping $150+\n\n# Classic Knit Sweater\n\nOur best-selling sweater made from premium natural fibers..."
}
]
}
Cero segundos de navegador, 256 registros de 266 paginas. Los metadatos son minimos comparados con la version renderizada: sin campos Open Graph, solo el estado HTTP, titulo de la pagina y URL. Pero el markdown sigue conteniendo el contenido completo de la pagina incluyendo navegacion, detalles de productos y pie de pagina. Para tiendas Shopify renderizadas en el servidor, el HTML estatico ya tiene todo lo que necesitas.
Descubrimiento de URLs
El rastreador descubre URLs a traves de tres fuentes (cuando source esta configurado como all):
- La URL de inicio que proporcionas
- Enlaces de sitemap encontrados en el dominio
- Enlaces internos encontrados en las paginas rastreadas
Puedes restringir esto solo a sitemaps o solo a enlaces de pagina usando el parametro source. excludePatterns siempre tiene prioridad sobre includePatterns, asi que puedes lanzar una red amplia y luego recortar secciones que no necesites.
Renderizado vs. obtencion rapida
render: true (el predeterminado) inicia un navegador headless, ejecuta JavaScript y espera a que la pagina cargue completamente. Esto es necesario para aplicaciones de pagina unica y contenido renderizado por JavaScript, pero usa segundos de navegador que se facturan.
render: false hace una obtencion rapida de HTML sin ejecutar JavaScript. Durante la beta, estas obtenciones no se facturan. Esta es la opcion correcta para sitios estaticos o paginas renderizadas en el servidor donde el contenido ya esta en el HTML inicial.
Facturacion y disponibilidad
El endpoint esta disponible tanto en los planes Workers Free como Paid. Los rastreos renderizados se facturan bajo el precio de Browser Rendering de Cloudflare a $0.09 por hora de navegador mas alla de tu asignacion incluida.
Workers Free: 10 minutos de tiempo de navegador por dia. El endpoint /crawl esta limitado a 5 trabajos por dia, 100 paginas por rastreo y 6 solicitudes de API por minuto.
Workers Paid ($5/mes): 10 horas de tiempo de navegador por mes incluidas. Sin limites de paginas por rastreo. 600 solicitudes de API por minuto. Las horas adicionales de navegador cuestan $0.09 cada una.
Los rastreos con render: false usan cero tiempo de navegador. Son gratuitos durante la beta pero eventualmente estaran bajo el precio estandar de Workers.
Que es el tiempo real (Wall Clock Time)?
El tiempo real es el tiempo total transcurrido desde que un rastreo comienza hasta que termina, medido de la misma manera que lo cronometrarias con un cronometro. Incluye todo: latencia de red, tiempo de cola interno de Cloudflare, busquedas DNS, tiempo de respuesta del servidor y (si el renderizado esta habilitado) tiempo de ejecucion del navegador.
El tiempo real es diferente del tiempo de navegador. El tiempo de navegador solo cuenta los segundos que el navegador headless de Cloudflare pasa activamente renderizando paginas. Un rastreo podria usar 22 minutos de tiempo de navegador pero tomar 25 minutos de tiempo real debido a la sobrecarga de cola y red. Los rastreos sin renderizado usan cero tiempo de navegador pero aun tienen tiempo real por el proceso de obtencion y cola.
En nuestros benchmarks, reportamos ambos numeros para que puedas ver por que estas pagando (tiempo de navegador) versus cuanto tiempo realmente estas esperando (tiempo real).
La letra pequena
El endpoint respeta las directivas de robots.txt incluyendo crawl-delay. Se identifica como CloudflareBrowserRenderingCrawler/1.0. No evade CAPTCHAs, desafios Turnstile ni otras protecciones contra bots. Si estas rastreando tu propio sitio y te estan bloqueando, necesitas crear una regla de omision de WAF para incluir al rastreador en la lista permitida.
Como se comporta Cloudflare /crawl en cinco tiendas Shopify
Ejecutamos el endpoint /crawl contra cinco tiendas Shopify en produccion para medir velocidad, tasa de exito, costo y como el rastreador interactua con cada sitio. Cada nombre de tienda esta anonimizado. Estos son numeros reales de rastreos reales. Los tiempos reales son estimaciones aproximadas. Algunas pruebas iniciales usaron scripts con manejo de errores limitado, lo que puede haber afectado las tasas de exito reportadas en ciertas tiendas. Donde esto aplica, lo indicamos a continuacion.
Este no es un endpoint de configurar y olvidar. Cada tienda respondio de manera diferente a las solicitudes del endpoint. Algunas necesitaron bloqueo de recursos para completar un rastreo renderizado. Otras devolvieron errores 429 en un modo pero funcionaron bien en el otro. Las directivas de crawl-delay, el conteo de paginas y la arquitectura de la tienda cambiaron el resultado. Planea probar y ajustar la configuracion para cada sitio que rastrees.
Prueba 1: catalogo de e-commerce grande (Store A)
Apuntamos el endpoint /crawl a una tienda Shopify grande con casi 3,000 paginas. El contenido regreso rapido, el markdown era utilizable y el endpoint no tuvo problemas para obtener paginas de productos, paginas de colecciones y contenido de blog. Sin problemas de proxy, sin bloqueos, sin limitacion de velocidad.
Ejecutamos multiples rastreos a diferentes escalas:
| Tamano del rastreo | Paginas devueltas | Modo | Tiempo de navegador | Tiempo real |
|---|---|---|---|---|
| Muestra de 20 paginas | 20 / 20 (100%) | no-render | 0s | ~1 min |
| Rastreo de 500 paginas | 500 / 500 (100%) | no-render | 0s | ~18 min |
| 5 paginas renderizadas | 4 / 5 (80%) | render: true | 0.9s | ~10s |
Rastrear sin renderizado de JavaScript logro 100% de exito en ambas escalas. El renderizado completo del navegador devolvio 4 de 5 paginas en una prueba de muestra pequena. En una muestra tan pequena, la unica pagina faltante podria ser un timeout del navegador, un error transitorio o un problema del script.
Prueba 2: tienda Shopify pequena (Store D, 24 paginas)
Una tienda mas pequena donde probamos el flujo de trabajo completo:
Rastrear sin renderizado devolvio errores. Nuestra prueba inicial devolvio respuestas 429 en la obtencion de HTML plano. No hemos vuelto a probar esta tienda con manejo de errores mejorado, por lo que no podemos confirmar si los 429 se originaron por la limitacion de velocidad de la tienda o por problemas transitorios durante la prueba.
El renderizado completo con descubrimiento basado en sitemaps fue un exito total. 24 de 24 paginas rastreadas, 100% de completitud.
| Tipo de pagina | Cantidad |
|---|---|
| Products | 9 |
| Collections | 4 |
| Pages | 3 |
| Blogs/News | 5 |
| Other (homepage, blog index) | 3 |
Un descubrimiento importante: el modo de descubrimiento de URLs predeterminado solo encontro 1 pagina porque la pagina de inicio tenia casi ningun enlace interno. Cambiar al descubrimiento basado en sitemaps encontro las 24. Si tu pagina de inicio es minimalista o tiene mucho JavaScript, el rastreador puede no encontrar paginas solo a traves de enlaces.
Prueba 3: tienda de ropa mediana (Store B, 256 paginas), con y sin renderizado
Nuestra prueba mas detallada. Una tienda de ropa mediana con 256 paginas indexables: productos, colecciones, publicaciones de blog y paginas informativas. Ejecutamos ambos modos en todo el sitio para medir la diferencia real.
| Metrica | render: false | render: true | Diferencia |
|---|---|---|---|
| Paginas rastreadas | 256 / 266 | 256 / 266 | Igual |
| Salida total de markdown | 11.0 MB | 12.5 MB | +14% |
| Tiempo de navegador | 0s | 1,338s (22 min) | +22 min |
| Costo estimado | $0 (beta) | ~$0.03 | +$0.03 |
| Tiempo real | ~5 min | ~25 min | 5x mas lento |
Prueba 4: minorista de salud y suplementos (Store C), exito parcial a escala
Un gran minorista de productos de salud con un catalogo masivo. Ejecutamos dos rastreos sin renderizado a diferentes escalas:
| Tamano del rastreo | Paginas devueltas | Tasa de exito | Tiempo real |
|---|---|---|---|
| Muestra de 5 paginas | 2 / 5 | 40% | ~25s |
| Rastreo de 100 paginas | 89 / 100 | 89% | ~3.5 min |
La tasa de exito parcial podria indicar que la infraestructura de esta tienda descarta algunas solicitudes sin navegador, pero nuestra prueba inicial carecia de recuperacion robusta de errores, por lo que algunos de estos fallos pueden haber sido recuperables con mejor manejo de reintentos de nuestra parte. La tasa de exito mejoro del 40% al 89% a mayor escala. No hemos vuelto a probar esta tienda con manejo de errores mejorado para aislar la causa.
Prueba 5: tienda grande multi-categoria (Store E, ~1,200 paginas)
Nuestra prueba mas grande y reveladora. Una tienda Shopify con aproximadamente 1,200 URLs distribuidas en cuatro sitemaps: 521 productos, 626 colecciones, 22 paginas y 31 publicaciones de blog.
| Metrica | render: false | render: true (optimizado) |
|---|---|---|
| Paginas rastreadas | 1,200 / 1,200 | 100 / 100 |
| Salida total de markdown | 148.5 MB | 11.3 MB |
| Tiempo de navegador | 0s | 475s (~8 min) |
| Costo estimado | $0 (beta) | ~$0.012 |
| Tiempo real | ~55 min | ~12 min |
El rastreo sin renderizado logro 100% de exito en las 1,200 paginas con cero costo de navegador. El rastreo renderizado se ejecuto en una muestra de 100 paginas con optimizaciones de bloqueo de recursos habilitadas.
El bloqueo de recursos marco la diferencia entre un rastreo atascado y uno limpio. Sin bloquear recursos, el rastreo renderizado se quedo en 99 de 100 paginas indefinidamente y consumio 649 segundos de tiempo de navegador para esas 99 paginas. Habilitar el bloqueo de recursos (imagenes, medios, fuentes, hojas de estilo) con una condicion de espera domcontentloaded completo las 100 paginas en 475 segundos, una reduccion del 27% en tiempo de navegador sin atascos.
El crawl-delay en robots.txt creo estancamientos visibles. El robots.txt de Store E especifica un crawl-delay de 10 segundos para ciertos bots. En nuestros datos de sondeo sin renderizado, esto aparecio como mesetas de varios minutos donde el conteo de paginas se estancaba antes de reanudarse. El rastreador de Cloudflare respeta las directivas de crawl-delay, lo que extiende directamente el tiempo real en sitios que las configuran.
Que acepta realmente el endpoint /crawl
El endpoint toma una URL de inicio, no una lista. Descubre paginas rastreando hacia afuera desde esa URL a traves de sitemaps, enlaces de pagina, o ambos. Si ya tienes una lista de URLs de un rastreo de Scrapy y quieres usar Cloudflare para la conversion a markdown, necesitarias llamar a los endpoints separados /markdown o /scrape individualmente por URL.
Que hace realmente Cloudflare /crawl en el lado del servidor?
Extrajimos los registros completos del servidor durante un rastreo completamente renderizado de Store D (25 paginas) para analizar la huella real de trafico. Los resultados revelan diferencias fundamentales entre el rastreo con renderizado de navegador y el rastreo tradicional de bots, con efectos secundarios no intencionados para analiticas, carga del servidor y monitoreo de trafico de bots.
| Metrica | Valor |
|---|---|
| User-Agent | CloudflareBrowserRenderingCrawler/1.0 (100% de los hits) |
| Ventana de rastreo | 134 segundos (~2 minutos) |
| Rendimiento maximo | 82 solicitudes/segundo |
| IPs unicas | 23, en 5 centros de datos de Cloudflare |
| Solicitudes GET | 2,071 |
| Solicitudes POST | 163 |
| Solicitudes totales | 2,234 |
| Paginas realmente renderizadas | ~25 |
| Solicitudes por pagina | ~89x amplificacion |
Cuanto trafico genera realmente un Cloudflare /crawl completamente renderizado?
El hallazgo mas importante: solo el 1.1% de las 2,234 solicitudes fueron contenido de pagina real. El otro 98.9% fueron JavaScript, CSS, beacons de analiticas, pixeles de seguimiento y precargas de checkout disparadas por el navegador al cargar cada pagina como lo haria un visitante real.
Un bot sin renderizado como Amazonbot o ChatGPT-User genera 1 solicitud por pagina. El renderizador de navegador de Cloudflare genera 89.
Infla Cloudflare /crawl las analiticas de Shopify?
Las 163 solicitudes POST en nuestros registros fueron completamente endpoints de analiticas y seguimiento de Shopify disparandose durante el rastreo. Estos son los mismos eventos que se disparan cuando un cliente real visita tu tienda. Desde la perspectiva de Shopify Analytics, el rastreador de Cloudflare parece un visitante navegando cada pagina de tu sitio en 2 minutos.
A que velocidad golpea Cloudflare /crawl tu servidor?
Las 2,234 solicitudes llegaron en una ventana de 134 segundos. El rendimiento maximo alcanzo 82 solicitudes por segundo. El rastreador renderizo todo el sitio de 25 paginas en poco mas de 2 minutos, pero el servidor vio una rafaga sostenida de trafico que no se parece en nada a los patrones de navegacion organica.
Para tiendas pequenas, esto es manejable. Para tiendas mas grandes con miles de paginas, la amplificacion de solicitudes (89x por pagina) combinada con rendimiento sostenido podria crear una carga significativa en el servidor de origen, especialmente si estas en un plan de hosting compartido o tienes limitacion de velocidad agresiva.
De donde viene Cloudflare /crawl?
El rastreo se distribuyo en 5 centros de datos de Cloudflare en EE.UU.:
| Centro de datos | % de solicitudes | Ubicacion |
|---|---|---|
| ATL | 38% | Atlanta |
| ORD | 25% | Chicago |
| MIA | 23% | Miami |
| EWR | 9% | Newark |
| IAD | 5% | Washington DC |
Esto no es un solo servidor haciendo solicitudes. Cloudflare distribuye la carga de trabajo de renderizado a traves de su red edge. Las 23 IPs cayeron en el rango 104.28.x.x, y el user-agent fue CloudflareBrowserRenderingCrawler/1.0 en cada solicitud.
Que huella digital de navegador deja Cloudflare /crawl?
El renderizador envia cabeceras Sec-Fetch apropiadas que imitan un navegador Chrome real:
| Cabecera | Valor | Chrome real? |
|---|---|---|
sec-fetch-dest |
script, document, etc. |
Si, coincide |
sec-fetch-mode |
cors, navigate |
Si, coincide |
sec-fetch-site |
same-origin, cross-site |
Si, coincide |
sec-ch-ua (Client Hints) |
No enviado | No, Chrome real envia esto |
| Version HTTP | HTTP/1.1 | No, Chrome real negocia HTTP/2 o HTTP/3 |
Dos brechas de huella digital destacan: el renderizador omite completamente las cabeceras sec-ch-ua Client Hints (un navegador Chrome real siempre las envia), y todas las solicitudes usan HTTP/1.1 en lugar de HTTP/2 o HTTP/3. Si estas construyendo reglas de deteccion de bots, estas son senales confiables para distinguir el renderizador de navegador de Cloudflare del trafico real de visitantes.
Como se compara Cloudflare /crawl con otros bots de IA en los registros del servidor?
Comparamos el rastreo de Cloudflare contra otros bots que visitaron la misma tienda en la misma ventana de 12 horas:
Amazonbot y ChatGPT-User obtienen HTML sin procesar: una solicitud, una pagina, sin ejecucion de JavaScript. AhrefsBot rastrea sitemaps para descubrimiento. El renderizador de navegador de Cloudflare ejecuta un storefront Shopify completo en cada pagina, disparando cada script, pixel y precarga como si un cliente real estuviera navegando.
Velocidad y costo de Cloudflare /crawl: el benchmark completo
Cada rastreo que ejecutamos, en una tabla. Todas las tiendas anonimizadas, todos los numeros de pruebas reales. Los tiempos reales son aproximados. Las tasas de exito para las tiendas C y D pueden haberse visto afectadas por el manejo de errores limitado en nuestros scripts de prueba iniciales.
| Tienda | Paginas | Modo | Tasa de exito | Tiempo de navegador | Tiempo real | Costo |
|---|---|---|---|---|---|---|
| A: E-Commerce grande | 500 / 500 | no-render | 100% | 0s | ~18 min | $0 |
| B: Ropa mediana | 256 / 266 | no-render | 96% | 0s | ~5 min | $0 |
| C: Salud y suplementos | 89 / 100 | no-render | 89% | 0s | ~3.5 min | $0 |
| D: Shopify pequena | 24 / 24 | render: true | 100% | 58s | ~2 min | ~$0.002 |
| E: Grande multi-categoria | 1,200 / 1,200 | no-render | 100% | 0s | ~55 min | $0 |
Que tan rapido es Cloudflare /crawl con vs. sin renderizado?
La comparacion mas clara viene de Store B, donde ejecutamos ambos modos en exactamente las mismas 256 paginas:
El patron en los once rastreos es consistente: rastrear sin renderizado es dramaticamente mas rapido. El tiempo real sin renderizado es mayormente la sobrecarga interna de cola y obtencion de Cloudflare. El renderizado completo agrega aproximadamente 5 segundos de tiempo de navegador por pagina sobre esa linea base.
Cuanto cuesta un rastreo Cloudflare completamente renderizado por pagina?
El precio de Browser Rendering de Cloudflare se basa en horas de navegador, el tiempo que su navegador headless pasa activamente renderizando tus paginas. Rastrear sin renderizado usa cero horas de navegador y es gratuito durante la beta.
Plan Workers Free: 10 minutos de tiempo de navegador por dia. El endpoint /crawl esta ademas limitado a 5 trabajos de rastreo por dia, con un maximo de 100 paginas por rastreo.
Plan Workers Paid ($5/mes): 10 horas de tiempo de navegador por mes incluidas. Mas alla de eso, pagas $0.09 por hora adicional de navegador. Sin limites por rastreo. Hasta 600 solicitudes de API por minuto.
Esto es lo que costaron nuestros rastreos de prueba realmente a $0.09/hr:
| Rastreo | Tiempo de navegador usado | Costo a $0.09/hr |
|---|---|---|
| Store D: 24 paginas renderizadas | 58 segundos | ~$0.002 |
| Store B: 256 paginas renderizadas | 1,338 segundos (~22 min) | ~$0.03 |
| Catalogo de 3,000 paginas (estimado) | ~4 horas | ~$0.36 |
A aproximadamente 5 segundos de tiempo de navegador por pagina, todos estos costos caen bien dentro de las 10 horas incluidas en el plan pagado. Un rastreo renderizado de 3,000 paginas usaria aproximadamente 4 de tus 10 horas incluidas, lo que significa que podrias ejecutar dos rastreos completos por mes antes de pagar algo mas alla de los $5 base. Rastrear sin renderizado es gratuito y no tiene costo de tiempo de navegador en ningun plan.
Cuando deberias omitir el renderizado vs. usar renderizado completo en Cloudflare /crawl?
La conclusion
Para la mayoria de las tiendas Shopify con contenido renderizado en el servidor, rastrear sin renderizado te da mas del 90% del contenido util a costo cero en una fraccion del tiempo.
Lo que aprendimos probando Cloudflare /crawl en tiendas Shopify
Despues de ejecutar 11 rastreos en 5 tiendas Shopify en produccion y analizar registros completos del servidor, estos son los hallazgos que mas importan.
El 90% del contenido llega sin renderizado
Para tiendas Shopify con paginas estandar renderizadas en el servidor, rastrear sin renderizado de JavaScript capturo mas del 90% del contenido util. El aumento del 14% en contenido del renderizado completo provino casi en su totalidad de elementos cargados por JavaScript en paginas de inicio y paginas de indice. Las paginas de productos individuales y los articulos del blog fueron casi identicos en cualquier caso. A menos que tu tienda este construida como una aplicacion de pagina unica, probablemente no necesites renderizado completo.
El renderizado completo crea un multiplicador de trafico de 89x
Renderizar 25 paginas genero 2,234 solicitudes al servidor. Solo 25 de ellas fueron contenido de pagina real. El otro 98.9% fueron archivos JavaScript (75%), beacons de analiticas (6.3%), CSS (4.3%), pixeles de seguimiento (3.4%) y precargas de checkout (3.3%). Cada pagina renderizada dispara la pila completa del lado del cliente de Shopify como si un cliente real estuviera navegando.
Tus analiticas de Shopify probablemente estan siendo infladas
Los rastreos renderizados disparan la pila completa de analiticas de Shopify: beacons monorail, eventos de seguimiento, precargas de Shop Pay y scripts de web-pixel. Creemos que esto significa que Shopify Analytics esta contando estas como sesiones de visitantes reales. Si ese es el caso, un solo rastreo renderizado podria inflar tus conteos de sesiones, vistas de pagina y datos del embudo de conversion. No hemos confirmado esto directamente en los informes de Shopify, pero los registros del servidor muestran todos los mismos eventos de analiticas disparandose como lo harian para un cliente real.
El renderizado completo puede evadir los limites de velocidad de la tienda
Store D devolvio errores 429 en cada pagina sin renderizado. Cambiar a renderizado completo en la misma tienda produjo 100% de exito. Si encuentras limites de velocidad sin renderizado, el renderizado completo es tu solucion.
El descubrimiento por sitemaps es mas confiable que el descubrimiento por enlaces
El descubrimiento basado en enlaces predeterminado no encontro casi nada en Store D porque la pagina de inicio tenia muy pocos enlaces internos. Cambiar al descubrimiento basado en sitemaps encontro las 24 paginas. Siempre usa el descubrimiento por sitemaps.
El rastreador proviene de 5 centros de datos en EE.UU.
Cloudflare distribuye la carga de trabajo de renderizado a traves de su red edge. Nuestro rastreo provino de 23 IPs unicas en Atlanta (38%), Chicago (25%), Miami (23%), Newark (9%) y Washington DC (5%). Todas las IPs caen en el rango 104.28.x.x.
Dos brechas de huella digital lo identifican como bot
El renderizador omite las cabeceras sec-ch-ua Client Hints (Chrome real siempre las envia) y usa HTTP/1.1 en lugar de HTTP/2 o HTTP/3. Si estas construyendo reglas de deteccion de bots, estas son senales confiables.
El renderizado puede devolver menos contenido
En Store E, el rastreo sin renderizado devolvio 6.8% mas contenido por pagina que el rastreo renderizado. Bloquear imagenes, fuentes y hojas de estilo para optimizar el tiempo de navegador tambien evito que algunos scripts de JavaScript poblaran elementos dinamicos. El HTML estatico ya tenia todo. Para tiendas Shopify renderizadas en el servidor, no se garantiza que el renderizado capture mas contenido.
El bloqueo de recursos previene rastreos atascados
Sin bloqueo de recursos, el rastreo renderizado en Store E se quedo en 99 de 100 paginas y nunca se completo. Habilitar el bloqueo para imagenes, medios, fuentes y hojas de estilo con una condicion de espera domcontentloaded completo las 100 paginas y redujo el tiempo de navegador en un 27%. Si tus rastreos renderizados se atascan antes de terminar, el bloqueo de recursos es la solucion.
El crawl-delay de robots.txt extiende el tiempo real
El robots.txt de Store E especifica un crawl-delay de 10 segundos. En nuestros datos de sondeo sin renderizado, esto aparecio como mesetas de varios minutos donde el conteo de paginas se estancaba antes de reanudarse. El rastreador de Cloudflare respeta las directivas de crawl-delay, por lo que los sitios con retrasos agresivos tendran tiempos reales significativamente mas largos de lo que el conteo de paginas solo sugeriria.
El costo es bajo pero el plan gratuito tiene limites
Renderizar 256 paginas costo aproximadamente $0.03 a $0.09 por hora de navegador. Renderizar 24 paginas costo aproximadamente $0.002. El plan Workers Free limita el tiempo de navegador a 10 minutos por dia con un maximo de 5 trabajos de rastreo y 100 paginas por rastreo. El plan Workers Paid ($5/mes) incluye 10 horas de tiempo de navegador por mes sin limites por rastreo. Un rastreo renderizado de 3,000 paginas usaria aproximadamente 4 de esas 10 horas incluidas, asi que la mayoria de las tiendas caben comodamente en el plan pagado sin excedentes. Rastrear sin renderizado usa cero tiempo de navegador y es gratuito en cualquier plan durante la beta.
Las ventajas
Velocidad
Paginas obtenidas casi instantaneamente versus un rastreo de Scrapy de varias horas con autothrottle. Sin colas, sin retrasos de cortesia, sin esperar a que tu spider trabaje a traves de miles de solicitudes a un ritmo respetuoso.
Salida en Markdown
El endpoint devuelve HTML-a-Markdown pre-convertido para cada pagina. Esto es directamente util para ingestion en LLM, pipelines RAG y analisis de contenido sin ningun post-procesamiento. Te saltas toda la capa de extraccion y vas directamente a texto limpio. Para equipos que construyen aplicaciones de IA sobre contenido web, esto elimina un paso del pipeline.
Opcion de modo de renderizado
Configurar render: true ejecuta JavaScript y extrae automaticamente metadatos Open Graph (og:title, og:description, og:image, og:site_name). Para sitios con mucho JavaScript donde el contenido se renderiza del lado del cliente, esta es la diferencia entre ver la pagina real y ver un cascaron vacio.
Sin dolores de cabeza con proxies o limites de velocidad
Cloudflare maneja las medidas anti-bot y la limitacion de velocidad en su propia infraestructura. No necesitas gestionar pools de proxies, rotar user agents ni lidiar con CAPTCHAs. Una sola llamada API.
Rastreo incremental
Los parametros modifiedSince y maxAge te permiten omitir paginas que no han cambiado o que se obtuvieron recientemente. Para rastreos recurrentes donde estas monitoreando cambios de contenido, esto ahorra tanto tiempo como costo al procesar solo paginas que realmente son nuevas o actualizadas.
Simplicidad
Una sola llamada API. Respuesta JSON. Sin codigo de spider, sin middleware, sin pipelines de items, sin archivos de configuracion.
Bot bien comportado por defecto
El rastreador es un agente firmado que respeta robots.txt, crawl-delay y el AI Crawl Control de Cloudflare. Se identifica como CloudflareBrowserRenderingCrawler/1.0 y no puede evadir proteccion contra bots ni CAPTCHAs. Obtienes cumplimiento etico de rastreo sin construir la logica tu mismo.
Lo que no soporta el endpoint Cloudflare Crawl
Como se diferencia Cloudflare /crawl de un pipeline de rastreo completo?
La tabla a continuacion muestra exactamente que capacidades estan presentes en el endpoint /crawl de Cloudflare versus un pipeline de produccion de Scrapy. Esto se basa en nuestras pruebas reales contra tiendas Shopify.
| Capacidad | Cloudflare /crawl | Pipeline de Scrapy |
|---|---|---|
| Obtencion de contenido (HTML/Markdown) | Si | Si |
| Renderizado de JavaScript | Si (render: true) |
Si (Splash/Playwright) |
| Descubrimiento de enlaces / spidering | Si (lista plana) | Si (grafo de rastreo completo) |
| Mapeo de enlaces padre-hijo | No | Si |
| Deteccion de paginas huerfanas | No | Si |
| Seguimiento de cadenas de redireccion | No | Si |
| Extraccion de JSON-LD | No | Si |
| Extraccion de Microdata | No | Si |
| Validacion de esquemas + reporte de problemas | No | Si |
| Codigos de estado no-200 (404s, 403s) | No | Si (capturo 2,547 404s en nuestra prueba) |
| Limite de URLs | 100,000 | Ninguno |
Que datos estructurados extrae Cloudflare /crawl?
Con render: false, ninguno. Sin JSON-LD, sin Microdata, sin analisis de OpenGraph.
Con render: true, solo etiquetas OG basicas (og:title, og:description, og:image, og:site_name). JSON-LD y el markup de schema.org no se analizan, extraen ni validan.
Para comparacion, nuestro pipeline de Scrapy produce schemas_found, issues (contactPoint faltante, address, etc.), top_level_schemas y nested_schemas para cada URL. Puedes ver que paginas tienen esquema Product, cuales les falta el markup de Organization y cuales tienen errores de validacion que harian que los sistemas de IA lean mal el contenido.
Que codigos de estado HTTP devuelve Cloudflare /crawl?
Solo respuestas 200. Nuestro rastreo de Scrapy del mismo sitio capturo 2,547 errores 404, mas respuestas 403 y errores de conexion. La deteccion de 404 es critica para el analisis de paginas fantasma, la remediacion de enlaces rotos y el mapeo de redirecciones. Sin ella, te estan faltando las paginas que estan activamente fugando link equity y confundiendo a los rastreadores de IA.
Cuantas URLs puede procesar Cloudflare /crawl?
Hasta 100,000 por trabajo. Esto cubre la mayoria de los sitios, pero los catalogos grandes de e-commerce con cientos de miles de paginas de productos, URLs de variantes y paginas de colecciones filtradas excederan el limite. Scrapy no tiene limite inherente de URLs.
Tiene Cloudflare /crawl un error de resolucion de URLs?
Encontramos 233 de 908 enlaces en una sola pagina de producto con rutas rotas. El convertidor de markdown resuelve URLs relativas contra la URL de la pagina incorrectamente, produciendo URLs de doble ruta como /products/slug//www.example.com/.... Este es un error confirmado en el convertidor de Cloudflare que afecta cualquier analisis de enlaces posterior.
Cuanto boilerplate hay en la salida de markdown de Cloudflare /crawl?
La pagina promedio devolvio 158 KB de markdown. Aproximadamente el 90% es contenido de plantilla repetido: navegacion completa, mega menu y pie de pagina en cada registro. Para el analisis de contenido esto significa mucho trabajo de deduplicacion, y para el uso de tokens de LLM el costo se acumula rapido. Necesitas tu propia logica de extraccion de contenido sobre el markdown para aislar el contenido real de la pagina.
Que no clasifica Cloudflare /crawl?
No hay etiquetado de tipo de contenido. Las paginas de productos, paginas de colecciones, publicaciones de blog y paginas de inicio regresan como registros indiferenciados. Scrapy clasifica cada URL por tipo, lo cual es esencial para entender la cobertura de rastreo por categoria de pagina y para identificar que tipos de contenido priorizan los bots de IA.
Que funciones de finalizacion faltan en Cloudflare /crawl?
Sin capturas de paginas fantasma. Sin comparacion de renderizado de JavaScript (lo que el bot ve versus lo que el navegador ve). Sin analisis de bots de IA en robots.txt. Sin informe de calidad de rastreo. Sin manifiesto de cliente. Sin sincronizacion CDN. Los datos de Cloudflare son solo contenido sin procesar. Cada pieza del pipeline de informes y analisis tendria que construirse por separado.
Cuanto cuesta Cloudflare /crawl para sitios grandes?
En nuestras pruebas, render: true promedió aproximadamente 5 segundos de ejecucion de navegador por pagina. Un rastreo de 256 paginas uso 1,338 segundos de navegador (22 minutos) y costo aproximadamente $0.03 a $0.09 por hora de navegador. Un rastreo de 24 paginas uso 58 segundos de navegador y costo aproximadamente $0.002. Extrapolando a un catalogo de 3,000 paginas: aproximadamente 4 horas de tiempo de navegador. El plan Workers Free esta limitado a 10 minutos de tiempo de navegador por dia, 5 trabajos de rastreo por dia y 100 paginas por rastreo. El plan Workers Paid ($5/mes) incluye 10 horas de tiempo de navegador por mes sin limites por rastreo, asi que un rastreo de 3,000 paginas usaria aproximadamente 4 de esas 10 horas incluidas. render: false usa cero tiempo de navegador y es gratuito durante la beta en cualquier plan.
La conclusion final
El endpoint de rastreo de Cloudflare es excelente para:
- Instantaneas rapidas de contenido cuando necesitas texto de pagina rapido
- Markdown listo para LLM para pipelines RAG e ingestion de contenido
- Verificaciones ad-hoc de paginas donde conoces las URLs exactas que necesitas
- Extracciones rapidas de contenido de todo el sitio cuando necesitas texto en markdown sin construir un spider
No puede reemplazar un pipeline de rastreo completo porque el valor del pipeline esta en:
- Grafo de rastreo completo con topologia de enlaces, deteccion de huerfanas y cobertura de 404
- Extraccion y validacion de datos estructurados (JSON-LD, Microdata, OpenGraph)
- Clasificacion de contenido por tipo de pagina
- El pipeline de finalizacion completo incluyendo analisis de paginas fantasma, comparacion de renderizado de JavaScript, informes de esquemas y puntuacion de preparacion para LLM
El mejor enfoque hibrido
Usa Cloudflare como fuente de datos complementaria. Despues de que un rastreo completo identifique tus URLs, usa la salida de markdown de Cloudflare para alimentar la puntuacion de preparacion para LLM o el analisis de calidad de contenido donde necesites el texto real de la pagina en lugar de metadatos estructurados. El pipeline de rastreo descubre y clasifica. El endpoint de Cloudflare entrega texto limpio para las paginas que importan.
Quieres ver el pipeline de rastreo completo en accion?
Agenda una llamadaPreguntas frecuentes
Que funciones de auditoria de sitios web no son compatibles con Cloudflare /crawl?
Cloudflare /crawl no soporta: construccion de grafos de rastreo completos, mapeo de enlaces padre-hijo, deteccion de paginas huerfanas, seguimiento de cadenas de redireccion, extraccion de JSON-LD o Microdata, validacion de esquemas, captura de codigos de estado no-200 (404s, 403s), clasificacion de tipos de contenido, medicion del tamano en bytes de la pagina, deteccion de paginas fantasma, comparacion de renderizado JS vs HTML, analisis de bots de IA en robots.txt, ni referencia cruzada de backlinks. Es un recolector de contenido, no una herramienta de auditoria de sitios.
Como se diferencia Cloudflare /crawl de Scrapy para el rastreo de comercio electronico?
Cloudflare /crawl obtiene contenido rapido sin infraestructura que gestionar. Scrapy construye un grafo de rastreo completo con topologia de enlaces, extrae y valida datos estructurados (JSON-LD, Microdata, OpenGraph), captura todos los codigos de estado HTTP incluyendo 404s, clasifica paginas por tipo de contenido y alimenta un pipeline posterior para analisis de paginas fantasma, informes de esquemas y puntuacion de preparacion para LLM. Cloudflare te da el texto de la pagina; Scrapy te da la arquitectura completa del sitio.
Cual es el limite exacto de URLs para Cloudflare /crawl?
100,000 URLs por trabajo de rastreo. El limit predeterminado es 10, por lo que debes establecerlo explicitamente. La depth maxima tambien es 100,000. Para sitios que excedan las 100K paginas, se requiere Scrapy u otro rastreador sin limite inherente de URLs.
Extrae Cloudflare /crawl JSON-LD o valida el markup de esquemas?
No. Con render: false, no se extraen datos estructurados. Con render: true, solo se devuelven etiquetas basicas de Open Graph (og:title, og:description, og:image, og:site_name). JSON-LD, Microdata y el markup de schema.org no se analizan, extraen ni validan en ningun modo.
Cuanto cuesta Cloudflare /crawl para renderizar sitios grandes?
En nuestras pruebas, render: true promedió aproximadamente 5 segundos de tiempo de navegador por pagina. Un sitio de 256 paginas uso 1,338 segundos de navegador (22 minutos) y costo aproximadamente $0.03 a $0.09 por hora de navegador. Un sitio de 24 paginas uso 58 segundos y costo aproximadamente $0.002. Extrapolando a un catalogo de 3,000 paginas: aproximadamente 4 horas de tiempo de navegador. El plan Workers Free esta limitado a 10 minutos por dia, 5 trabajos de rastreo por dia y 100 paginas por rastreo, por lo que los rastreos renderizados grandes requieren el plan Workers Paid ($5/mes), que incluye 10 horas de tiempo de navegador por mes sin limites por rastreo. render: false usa cero tiempo de navegador y es gratuito durante la beta en cualquier plan.
Tiene Cloudflare /crawl un error conocido de resolucion de URLs?
Si. En nuestra prueba, 233 de 908 enlaces en una sola pagina de producto tenian rutas malformadas. El convertidor de markdown antepone la URL de la pagina a rutas relativas como //www.example.com/cdn/..., creando URLs de doble ruta rotas. Esto afecta cualquier analisis de grafo de enlaces o auditoria de enlaces internos construida a partir de la salida de markdown.
Por que Cloudflare /crawl con render false devuelve errores 429 en algunas tiendas Shopify?
render: false hace una obtencion de HTML sin procesar sin un navegador headless. En una de nuestras pruebas, render: false devolvio errores 429 mientras que render: true funciono con 100% de exito en la misma tienda. No hemos vuelto a probar esto con manejo de errores mejorado, por lo que los 429 pueden haber sido causados por la limitacion de velocidad de la tienda, problemas transitorios de la API, o una combinacion. Si ves errores 429 sin renderizado, prueba render: true como primer paso.
Acepta Cloudflare /crawl una lista de URLs?
No. El endpoint toma una unica URL de inicio y descubre paginas rastreando hacia afuera a traves de sitemaps, enlaces de pagina, o ambos. Si ya tienes una lista de URLs y quieres la conversion a markdown de Cloudflare, usa los endpoints separados /markdown o /scrape, que aceptan URLs individuales por solicitud.
Por que Cloudflare /crawl con source all solo encuentra una pagina en algunos sitios?
El source: all predeterminado descubre URLs tanto de sitemaps como de enlaces de pagina. Si la URL de inicio tiene muy pocos enlaces internos (comun en paginas de inicio minimalistas o SPAs con mucho JavaScript), el rastreador puede no encontrar paginas adicionales solo a traves del descubrimiento por enlaces. Cambia a source: sitemaps para asegurar que el rastreador lea el sitemap.xml completo y descubra todas las URLs listadas.
Cual es la mejor manera de usar Cloudflare /crawl con un pipeline de rastreo completo?
Usa primero el pipeline de rastreo completo (Scrapy o equivalente) para descubrir URLs, construir el grafo de enlaces, extraer datos estructurados, capturar 404s y clasificar contenido. Luego usa los endpoints /markdown o /scrape de Cloudflare para obtener markdown limpio para puntuacion de preparacion para LLM, analisis de calidad de contenido o ingestion RAG donde necesites el texto real de la pagina en lugar de metadatos estructurados.
Cuanto mas rapido es Cloudflare /crawl con render false comparado con render true?
En nuestra prueba directa en el mismo sitio de 256 paginas, render: false se completo en aproximadamente 5 minutos. render: true tardo aproximadamente 25 minutos para las mismas paginas. Eso es una diferencia de velocidad de 5x. La diferencia en tiempo real proviene de aproximadamente 5 segundos de ejecucion del navegador agregados por pagina cuando el renderizado esta habilitado. render: false costo $0 durante la beta. render: true costo aproximadamente $0.03 para el mismo rastreo.
Cuanto contenido adicional captura Cloudflare /crawl con render true comparado con render false?
En nuestra prueba de 256 paginas, render: true produjo 12.5 MB de markdown versus 11.0 MB de render: false, un aumento del 14%. El contenido adicional provino casi en su totalidad de elementos cargados por JavaScript en la pagina de inicio y las paginas de indice del blog. Las paginas de productos individuales y los articulos del blog fueron casi identicos entre ambos modos. Para sitios con contenido mayormente renderizado en el servidor, render: false captura mas del 90% del texto util a costo cero y velocidad 5x mas rapida.
Funciona Cloudflare /crawl de manera confiable en todas las tiendas Shopify?
Depende de la tienda y del modo de renderizado. En nuestras pruebas en cinco tiendas Shopify: Store A (catalogo grande) logro 100% de exito con render: false. Store B (ropa mediana) logro 96% de exito con ambos modos. Store C (salud y suplementos) logro 40% en una muestra de 5 paginas y 89% en un rastreo de 100 paginas con render: false, aunque nuestra prueba inicial carecia de recuperacion robusta de errores y algunos fallos pueden haber sido recuperables. Store D (tienda pequena) devolvio errores 429 con render: false pero logro 100% con render: true. Store E (grande multi-categoria, ~1,200 paginas) logro 100% de exito con render: false y 100% en una muestra renderizada de 100 paginas con optimizaciones de bloqueo de recursos. No hemos vuelto a probar las tiendas C y D con manejo de errores mejorado. Prueba ambos modos en tu tienda especifica antes de comprometerte con una estrategia de rastreo.
Cual es el tiempo real para un Cloudflare /crawl de 500 paginas con render false?
En nuestra prueba, un rastreo render: false de 500 paginas se completo en aproximadamente 18 minutos con una tasa de exito del 100%. Un rastreo de 256 paginas en una tienda diferente se completo en aproximadamente 5 minutos. Un rastreo de 100 paginas se completo en aproximadamente 3.5 minutos. Estos tiempos reales son estimaciones basadas en intervalos de sondeo, no mediciones precisas. El tiempo real es principalmente la sobrecarga interna de cola y obtencion HTTP de Cloudflare, no el renderizado del navegador, ya que no se usan segundos de navegador con render: false.
Cuantas solicitudes al servidor genera un Cloudflare /crawl con render true?
En nuestro analisis de registros del servidor, un solo rastreo render: true de 25 paginas genero 2,234 solicitudes totales: 2,071 GETs y 163 POSTs. Eso es aproximadamente 89 solicitudes al servidor por pagina realmente renderizada. Solo el 1.1% de las solicitudes fueron contenido de pagina real. El 98.9% restante fueron archivos JavaScript (75%), beacons de analiticas (6.3%), CSS (4.3%), pixeles de seguimiento (3.4%) y precargas de checkout (3.3%). Si estas monitoreando trafico de bots o gestionando carga del servidor, espera que un rastreo renderizado genere 89x el numero de solicitudes de pagina reales en tus registros del servidor.
Que user-agent usa Cloudflare /crawl y de que rango de IPs proviene?
El rastreador se identifica como CloudflareBrowserRenderingCrawler/1.0 en el 100% de las solicitudes. En nuestros registros, todas las solicitudes provinieron de 23 IPs unicas en el rango 104.28.x.x distribuidas en 5 centros de datos de Cloudflare en EE.UU.: ATL (38%), ORD (25%), MIA (23%), EWR (9%) e IAD (5%). No hay rotacion de user-agent ni camuflaje de IP. El rastreador es un bot firmado e identificable por diseno.
Infla Cloudflare /crawl las analiticas de Shopify y los conteos de visitantes?
Creemos que si, pero no lo hemos confirmado directamente en los informes de Shopify. Debido a que render: true ejecuta JavaScript, dispara la pila completa de analiticas de Shopify en cada pagina: beacons monorail, eventos de seguimiento /api/collect, precargas de checkout de Shop Pay y scripts de web-pixel sandbox. En nuestra prueba, 163 de 2,234 solicitudes fueron solicitudes POST a endpoints de analiticas de Shopify. Estos son los mismos eventos que se disparan para clientes reales. Si Shopify cuenta estos como sesiones reales, tus conteos de sesiones, vistas de pagina y datos del embudo de conversion estarian inflados.
Como se puede detectar Cloudflare /crawl en los registros del servidor frente al trafico real del navegador?
Dos brechas de huella digital confiables: el renderizador de navegador de Cloudflare omite las cabeceras sec-ch-ua Client Hints (un navegador Chrome real siempre las envia), y todas las solicitudes usan HTTP/1.1 en lugar de HTTP/2 o HTTP/3 que un navegador real negociaria. Si envia cabeceras apropiadas de sec-fetch-dest, sec-fetch-mode y sec-fetch-site que coinciden con Chrome real. El user-agent siempre es CloudflareBrowserRenderingCrawler/1.0 y todas las IPs caen en el rango 104.28.x.x.