
Qu’est-ce que le endpoint Cloudflare /crawl ?
Le endpoint /crawl de Cloudflare fait partie de leur API Browser Rendering, actuellement en bêta ouverte. Il récupère le contenu à partir d’une URL de départ, suit les liens à travers le site jusqu’à une profondeur ou une limite de pages configurable, et renvoie les résultats sous forme de HTML, Markdown ou JSON structuré alimenté par Workers AI. Cloudflare le positionne comme un outil pour entraîner des modèles, construire des pipelines RAG, et rechercher ou surveiller du contenu à travers un site.
Le endpoint fonctionne comme un agent signé qui respecte le robots.txt et le contrôle AI Crawl de Cloudflare par défaut, ce qui est un choix de conception notable. Il est conçu pour faciliter la conformité des développeurs aux règles des sites web et rendre plus difficile pour les crawlers d’ignorer les directives des propriétaires de sites.
Le endpoint est accessible à :
https://api.cloudflare.com/client/v4/accounts/<account_id>/browser-rendering/crawl
Vous avez besoin d’un token API Cloudflare avec la permission Browser Rendering Edit pour l’utiliser.
Comment ça fonctionne
Le crawl s’exécute comme une tâche asynchrone en deux étapes :
- Démarrer le crawl avec une requête POST contenant une URL de départ. L’API renvoie immédiatement un identifiant de tâche.
- Interroger les résultats avec des requêtes GET utilisant cet identifiant de tâche. Lorsque le statut de la tâche passe de
runningàcompleted, vos données crawlées sont prêtes.
Les tâches peuvent s’exécuter pendant sept jours maximum. Les résultats sont conservés pendant 14 jours après la fin.
Ce que vous envoyez
Au minimum, vous envoyez une URL :
curl -X POST 'https://api.cloudflare.com/client/v4/accounts/{account_id}/browser-rendering/crawl' \
-H 'Authorization: Bearer <apiToken>' \
-H 'Content-Type: application/json' \
-d '{
"url": "https://example.com"
}'
Paramètres clés
| Paramètre | Par défaut | Ce qu’il fait |
|---|---|---|
limit |
10 | Nombre maximum de pages à crawler (jusqu’à 100 000) |
depth |
100 000 | Profondeur maximale des liens depuis l’URL de départ |
source |
all |
Où découvrir les URLs : all, sitemaps ou links |
formats |
HTML | Format de réponse : html, markdown ou json |
render |
true | Exécuter JavaScript (true) ou récupération HTML rapide (false) |
maxAge |
86 400 | TTL du cache en secondes (max 604 800) |
modifiedSince |
aucun | Horodatage Unix : ne crawler que les pages modifiées après cette date |
options.includePatterns |
aucun | Ne crawler que les URLs correspondant à ces modèles de wildcards |
options.excludePatterns |
aucun | Ignorer les URLs correspondant à ces modèles |
Ce que vous recevez en retour
Chaque page crawlée est renvoyée sous forme d’enregistrement avec l’URL, le statut, le contenu dans le format choisi, et des métadonnées de base (code de statut HTTP, titre de page, URL finale après redirections). Avec render: true, vous obtenez également les balises Open Graph. La réponse inclut aussi browserSecondsUsed pour la visibilité de la facturation, et un cursor pour paginer les résultats dépassant 10 Mo.
Voici la réponse réelle au niveau de la tâche pour un crawl rendu de 24 pages d’une boutique Shopify en production :
{
"job_id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890",
"status": "completed",
"total": 24,
"finished": 24,
"browserSecondsUsed": 58.38,
"record_count": 24,
"records": [
{
"url": "https://www.example-store.com/products/premium-widget-bundle",
"status": "completed",
"metadata": {
"status": 200,
"title": "Premium Widget Bundle | Example Store",
"url": "https://www.example-store.com/products/premium-widget-bundle",
"lastModified": "",
"og:type": "product",
"og:site_name": "Example Store",
"og:title": "Premium Widget Bundle | Example Store",
"og:image": "https://www.example-store.com/cdn/shop/files/product-image.jpg",
"og:description": "Our best-selling bundle with everything you need..."
},
"markdown": "Store\n\nexample-store\n\nURL\n\nhttps://www.example-store.com\n\nCurrency\n\nUSD\n\n# Premium Widget Bundle\n\nOur best-selling bundle with everything you need..."
}
]
}
Avec render: true, l’objet metadata inclut l’ensemble complet des champs Open Graph : type, nom du site, titre, URL de l’image et description. Ceux-ci sont extraits des balises meta OG de la page pendant le rendu navigateur. Avec render: false, les métadonnées ne contiennent que le code de statut HTTP, le titre de la page et l’URL finale. Aucun champ Open Graph n’est extrait.
Le champ markdown contient la sortie complète de la page, pas seulement le contenu principal. Les menus de navigation, les méga-menus, les pieds de page et les blocs de modèle répétés sont tous inclus dans chaque enregistrement. Dans nos tests, la page moyenne renvoyait environ 158 Ko de markdown, dont environ 90 % était du contenu passe-partout répété. Si vous injectez cela dans un LLM ou un pipeline RAG, vous aurez besoin de votre propre logique d’extraction de contenu pour supprimer le modèle et isoler le contenu réel de la page.
Voici ce que la même boutique a renvoyé lorsque nous avons exécuté render: false :
{
"job_id": "f9e8d7c6-b5a4-3210-fedc-ba9876543210",
"status": "completed",
"total": 266,
"finished": 266,
"browserSecondsUsed": 0,
"record_count": 256,
"records": [
{
"url": "https://www.example-store.com/products/classic-knit-sweater",
"status": "completed",
"metadata": {
"status": 200,
"title": "Classic Knit Sweater | Example Store",
"url": "https://www.example-store.com/products/classic-knit-sweater",
"lastModified": ""
},
"markdown": "Skip to content\n\nFree Shipping $150+\n\n# Classic Knit Sweater\n\nOur best-selling sweater made from premium natural fibers..."
}
]
}
Zéro seconde navigateur, 256 enregistrements sur 266 pages. Les métadonnées sont minimales par rapport à la version rendue : pas de champs Open Graph, juste le statut HTTP, le titre de la page et l’URL. Mais le markdown contient toujours le contenu complet de la page, y compris la navigation, les détails produit et le pied de page. Pour les boutiques Shopify rendues côté serveur, le HTML statique contient déjà tout ce dont vous avez besoin.
Découverte d’URLs
Le crawler découvre les URLs via trois sources (lorsque source est défini sur all) :
- L’URL de départ que vous fournissez
- Les liens de sitemap trouvés sur le domaine
- Les liens internes trouvés sur les pages crawlées
Vous pouvez restreindre cela aux sitemaps uniquement ou aux liens de page uniquement en utilisant le paramètre source. excludePatterns a toujours la priorité sur includePatterns, vous pouvez donc ratisser large puis exclure les sections dont vous n’avez pas besoin.
Rendu vs. récupération rapide
render: true (la valeur par défaut) lance un navigateur headless, exécute le JavaScript et attend que la page soit entièrement chargée. C’est nécessaire pour les applications monopage et le contenu rendu par JavaScript, mais cela utilise des secondes navigateur qui sont facturées.
render: false effectue une récupération HTML rapide sans exécuter de JavaScript. Pendant la bêta, ces récupérations ne sont pas facturées. C’est le bon choix pour les sites statiques ou les pages rendues côté serveur où le contenu est déjà dans le HTML initial.
Facturation et disponibilité
Le endpoint est disponible sur les plans Workers Free et Paid. Les crawls rendus sont facturés selon la tarification Browser Rendering de Cloudflare à 0,09 $ par heure de navigateur au-delà de votre allocation incluse.
Workers Free : 10 minutes de temps navigateur par jour. Le endpoint /crawl est limité à 5 tâches par jour, 100 pages par crawl et 6 requêtes API par minute.
Workers Paid (5 $/mois) : 10 heures de temps navigateur par mois incluses. Pas de limite de pages par crawl. 600 requêtes API par minute. Les heures navigateur supplémentaires sont à 0,09 $ chacune.
Les crawls render: false utilisent zéro temps navigateur. Ils sont gratuits pendant la bêta mais seront éventuellement soumis à la tarification standard Workers.
Qu’est-ce que le temps réel d’exécution ?
Le temps réel d’exécution est le temps total écoulé entre le début et la fin d’un crawl, mesuré de la même façon que si vous le chronomètriez avec un chronomètre. Il inclut tout : la latence réseau, le temps de file d’attente interne de Cloudflare, les recherches DNS, le temps de réponse du serveur, et (si le rendu est activé) le temps d’exécution du navigateur.
Le temps réel d’exécution est différent du temps navigateur. Le temps navigateur ne compte que les secondes où le navigateur headless de Cloudflare rend activement les pages. Un crawl peut utiliser 22 minutes de temps navigateur mais prendre 25 minutes en temps réel à cause de la file d’attente et du surcoût réseau. Les crawls sans rendu utilisent zéro temps navigateur mais ont toujours un temps réel d’exécution lié au processus de récupération et de mise en file d’attente.
Dans nos benchmarks, nous rapportons les deux chiffres pour que vous puissiez voir ce que vous payez (temps navigateur) par rapport à combien de temps vous attendez réellement (temps réel d’exécution).
Les petits caractères
Le endpoint respecte les directives robots.txt y compris crawl-delay. Il s’identifie comme CloudflareBrowserRenderingCrawler/1.0. Il ne contourne pas les CAPTCHAs, les challenges Turnstile, ni les autres protections anti-bot. Si vous crawlez votre propre site et êtes bloqué, vous devez créer une règle WAF d’exception pour mettre le crawler en liste blanche.
Comment Cloudflare /crawl se comporte sur cinq boutiques Shopify
Nous avons exécuté le endpoint /crawl sur cinq boutiques Shopify en production pour mesurer la vitesse, le taux de succès, le coût, et comment le crawler interagit avec chaque site. Chaque nom de boutique est anonymisé. Ce sont de vrais chiffres issus de vrais crawls. Les temps réels sont des estimations approximatives. Certains tests initiaux utilisaient des scripts avec une gestion d’erreurs limitée, ce qui a pu affecter les taux de succès rapportés pour certaines boutiques. Lorsque cela s’applique, nous le signalons ci-dessous.
Ce n’est pas un endpoint qu’on configure et qu’on oublie. Chaque boutique a répondu différemment aux requêtes du endpoint. Certaines nécessitaient le blocage de ressources pour terminer un crawl rendu. D’autres renvoyaient des erreurs 429 sur un mode mais fonctionnaient bien sur l’autre. Les directives crawl-delay, le nombre de pages et l’architecture de la boutique ont tous changé le résultat. Prévoyez de tester et d’ajuster les paramètres pour chaque site que vous crawlez.
Test 1 : grand catalogue e-commerce (Store A)
Nous avons pointé le endpoint /crawl sur une grande boutique Shopify avec près de 3 000 pages. Le contenu est revenu rapidement, le markdown était exploitable, et le endpoint n’a eu aucun problème à récupérer les pages produits, les pages collections et le contenu blog. Pas de problèmes de proxy, pas de blocages, pas de limitation de débit.
Nous avons exécuté plusieurs crawls à différentes échelles :
| Taille du crawl | Pages renvoyées | Mode | Temps navigateur | Temps réel |
|---|---|---|---|---|
| Échantillon de 20 pages | 20 / 20 (100 %) | no-render | 0s | ~1 min |
| Crawl de 500 pages | 500 / 500 (100 %) | no-render | 0s | ~18 min |
| 5 pages rendues | 4 / 5 (80 %) | render: true | 0,9s | ~10s |
Le crawl sans rendu JavaScript a atteint 100 % de succès aux deux échelles. Le rendu complet du navigateur a renvoyé 4 pages sur 5 dans un petit test d’échantillon. Sur un échantillon aussi petit, la page manquante pourrait être un timeout du navigateur, une erreur transitoire, ou un problème côté script.
Test 2 : petite boutique Shopify (Store D, 24 pages)
Une boutique plus petite où nous avons testé le workflow complet :
Le crawl sans rendu a renvoyé des erreurs. Notre test initial a renvoyé des réponses 429 lors de la récupération HTML brute. Nous n’avons pas re-testé cette boutique avec une gestion d’erreurs améliorée, nous ne pouvons donc pas confirmer si les 429 provenaient de la limitation de débit de la boutique ou de problèmes transitoires pendant le test.
Le rendu complet avec découverte par sitemap a été un succès total. 24 pages sur 24 crawlées, 100 % de complétion.
| Type de page | Nombre |
|---|---|
| Produits | 9 |
| Collections | 4 |
| Pages | 3 |
| Blogs/Actualités | 5 |
| Autres (accueil, index blog) | 3 |
Une découverte importante : le mode de découverte d’URL par défaut n’a trouvé qu’une seule page car la page d’accueil avait très peu de liens internes. Passer à la découverte par sitemap a trouvé les 24 pages. Si votre page d’accueil est minimaliste ou lourde en JavaScript, le crawler pourrait ne pas trouver de pages par les liens seuls.
Test 3 : boutique prêt-à-porter de taille moyenne (Store B, 256 pages), avec et sans rendu
Notre test le plus détaillé. Une boutique de prêt-à-porter de taille moyenne avec 256 pages indexables : produits, collections, articles de blog et pages informatives. Nous avons exécuté les deux modes sur le site complet pour mesurer la différence réelle.
| Métrique | render: false | render: true | Différence |
|---|---|---|---|
| Pages crawlées | 256 / 266 | 256 / 266 | Identique |
| Sortie markdown totale | 11,0 Mo | 12,5 Mo | +14 % |
| Temps navigateur | 0s | 1 338s (22 min) | +22 min |
| Coût estimé | 0 $ (bêta) | ~0,03 $ | +0,03 $ |
| Temps réel | ~5 min | ~25 min | 5x plus lent |
Test 4 : détaillant santé et compléments (Store C), succès partiel à grande échelle
Un grand détaillant de produits de santé avec un catalogue massif. Nous avons exécuté deux crawls sans rendu à différentes échelles :
| Taille du crawl | Pages renvoyées | Taux de succès | Temps réel |
|---|---|---|---|
| Échantillon de 5 pages | 2 / 5 | 40 % | ~25s |
| Crawl de 100 pages | 89 / 100 | 89 % | ~3,5 min |
Le taux de succès partiel pourrait indiquer que l’infrastructure de cette boutique rejette certaines requêtes non-navigateur, mais notre test initial manquait de récupération d’erreurs robuste, donc certains de ces échecs auraient pu être récupérables avec une meilleure gestion des tentatives de notre côté. Le taux de succès est passé de 40 % à 89 % à plus grande échelle. Nous n’avons pas re-testé cette boutique avec une gestion d’erreurs améliorée pour isoler la cause.
Test 5 : grande boutique multi-catégories (Store E, ~1 200 pages)
Notre test le plus grand et le plus révélateur. Une boutique Shopify avec environ 1 200 URLs réparties sur quatre sitemaps : 521 produits, 626 collections, 22 pages et 31 articles de blog.
| Métrique | render: false | render: true (optimisé) |
|---|---|---|
| Pages crawlées | 1 200 / 1 200 | 100 / 100 |
| Sortie markdown totale | 148,5 Mo | 11,3 Mo |
| Temps navigateur | 0s | 475s (~8 min) |
| Coût estimé | 0 $ (bêta) | ~0,012 $ |
| Temps réel | ~55 min | ~12 min |
Le crawl sans rendu a atteint 100 % de succès sur les 1 200 pages avec zéro coût navigateur. Le crawl rendu a été exécuté sur un échantillon de 100 pages avec des optimisations de blocage de ressources activées.
Le blocage de ressources a fait la différence entre un crawl bloqué et un crawl propre. Sans blocage de ressources, le crawl rendu s’est bloqué à 99 pages sur 100 indéfiniment et a consommé 649 secondes de temps navigateur pour ces 99 pages. L’activation du blocage de ressources (images, médias, polices, feuilles de style) avec une condition d’attente domcontentloaded a terminé les 100 pages en 475 secondes, soit une réduction de 27 % du temps navigateur sans blocage.
Le crawl-delay dans robots.txt a créé des pauses visibles. Le robots.txt de Store E spécifie un crawl-delay de 10 secondes pour certains bots. Dans nos données de sondage sans rendu, cela apparaissait comme des plateaux de plusieurs minutes où le compteur de pages stagnait avant de reprendre. Le crawler Cloudflare respecte les directives crawl-delay, ce qui prolonge directement le temps réel d’exécution sur les sites qui les définissent.
Ce que le endpoint /crawl accepte réellement
Le endpoint prend une seule URL de départ, pas une liste. Il découvre les pages en explorant vers l’extérieur à partir de cette URL via les sitemaps, les liens de page, ou les deux. Si vous avez déjà une liste d’URLs d’un crawl Scrapy et souhaitez utiliser Cloudflare pour la conversion markdown, vous devriez appeler les endpoints séparés /markdown ou /scrape individuellement par URL.
Que fait réellement Cloudflare /crawl côté serveur ?
Nous avons extrait les logs serveur complets pendant un crawl entièrement rendu de Store D (25 pages) pour analyser l’empreinte réelle du trafic. Les résultats révèlent des différences fondamentales entre le crawl rendu par navigateur et le crawl bot traditionnel, avec des effets secondaires non intentionnels pour les analytics, la charge serveur et la surveillance du trafic bot.
| Métrique | Valeur |
|---|---|
| User-Agent | CloudflareBrowserRenderingCrawler/1.0 (100 % des hits) |
| Fenêtre de crawl | 134 secondes (~2 minutes) |
| Débit maximal | 82 requêtes/seconde |
| IPs uniques | 23, réparties sur 5 centres de données Cloudflare |
| Requêtes GET | 2 071 |
| Requêtes POST | 163 |
| Requêtes totales | 2 234 |
| Pages effectivement rendues | ~25 |
| Requêtes par page | ~89x amplification |
Combien de trafic un crawl Cloudflare /crawl entièrement rendu génère-t-il réellement ?
Le constat principal : seulement 1,1 % des 2 234 requêtes concernaient du contenu de page réel. Les 98,9 % restants étaient du JavaScript, du CSS, des balises d’analyse, des pixels de suivi et des préchargements de checkout déclenchés par le navigateur chargeant chaque page comme le ferait un vrai visiteur.
Un bot sans rendu comme Amazonbot ou ChatGPT-User génère 1 requête par page. Le moteur de rendu navigateur Cloudflare en génère 89.
Cloudflare /crawl gonfle-t-il les analytics Shopify ?
Les 163 requêtes POST dans nos logs étaient entièrement des endpoints d’analyse et de suivi Shopify se déclenchant pendant le crawl. Ce sont les mêmes événements qui se déclenchent lorsqu’un vrai client visite votre boutique. Du point de vue de Shopify Analytics, le crawler Cloudflare ressemble à un visiteur parcourant toutes les pages de votre site en 2 minutes.
À quelle vitesse Cloudflare /crawl sollicite-t-il votre serveur ?
Les 2 234 requêtes ont atterri dans une fenêtre de 134 secondes. Le débit maximal a atteint 82 requêtes par seconde. Le crawler a rendu l’intégralité du site de 25 pages en un peu plus de 2 minutes, mais le serveur a vu un pic de trafic soutenu qui ne ressemble en rien aux schémas de navigation organiques.
Pour les petites boutiques, c’est gérable. Pour les boutiques plus grandes avec des milliers de pages, l’amplification des requêtes (89x par page) combinée à un débit soutenu pourrait créer une charge significative sur le serveur d’origine, surtout si vous êtes sur un hébergement partagé ou avez une limitation de débit agressive en place.
D’où provient Cloudflare /crawl ?
Le crawl a été distribué sur 5 centres de données Cloudflare aux États-Unis :
| Centre de données | % des requêtes | Emplacement |
|---|---|---|
| ATL | 38 % | Atlanta |
| ORD | 25 % | Chicago |
| MIA | 23 % | Miami |
| EWR | 9 % | Newark |
| IAD | 5 % | Washington DC |
Ce n’est pas un seul serveur qui fait des requêtes. Cloudflare distribue la charge de travail de rendu à travers son réseau edge. Les 23 IPs étaient toutes dans la plage 104.28.x.x, et le user-agent était CloudflareBrowserRenderingCrawler/1.0 sur chaque requête.
Quelle empreinte navigateur Cloudflare /crawl laisse-t-il ?
Le moteur de rendu envoie des en-têtes Sec-Fetch corrects qui imitent un vrai navigateur Chrome :
| En-tête | Valeur | Vrai Chrome ? |
|---|---|---|
sec-fetch-dest |
script, document, etc. |
Oui, correspond |
sec-fetch-mode |
cors, navigate |
Oui, correspond |
sec-fetch-site |
same-origin, cross-site |
Oui, correspond |
sec-ch-ua (Client Hints) |
Non envoyé | Non, le vrai Chrome l’envoie |
| Version HTTP | HTTP/1.1 | Non, le vrai Chrome négocie HTTP/2 ou HTTP/3 |
Deux lacunes d’empreinte se distinguent : le moteur de rendu omet entièrement les en-têtes sec-ch-ua Client Hints (un vrai navigateur Chrome les envoie toujours), et toutes les requêtes utilisent HTTP/1.1 au lieu de HTTP/2 ou HTTP/3. Si vous construisez des règles de détection de bots, ce sont des signaux fiables pour distinguer le moteur de rendu navigateur de Cloudflare du trafic réel des visiteurs.
Comment Cloudflare /crawl se compare-t-il aux autres bots IA dans les logs serveur ?
Nous avons comparé le crawl Cloudflare aux autres bots qui ont touché la même boutique dans la même fenêtre de 12 heures :
Amazonbot et ChatGPT-User récupèrent le HTML brut : une requête, une page, pas d’exécution JavaScript. AhrefsBot explore les sitemaps pour la découverte. Le moteur de rendu navigateur Cloudflare exécute un storefront Shopify complet sur chaque page, déclenchant chaque script, pixel et préchargement comme si un vrai client naviguait.
Vitesse et coût de Cloudflare /crawl : le benchmark complet
Chaque crawl que nous avons exécuté, dans un seul tableau. Toutes les boutiques anonymisées, tous les chiffres issus de vrais tests. Les temps réels sont approximatifs. Les taux de succès pour Stores C et D ont pu être affectés par une gestion d’erreurs limitée dans nos scripts de test initiaux.
| Boutique | Pages | Mode | Taux de succès | Temps navigateur | Temps réel | Coût |
|---|---|---|---|---|---|---|
| A: Grand e-commerce | 500 / 500 | no-render | 100 % | 0s | ~18 min | 0 $ |
| B: Prêt-à-porter moyen | 256 / 266 | no-render | 96 % | 0s | ~5 min | 0 $ |
| C: Santé et compléments | 89 / 100 | no-render | 89 % | 0s | ~3,5 min | 0 $ |
| D: Petite boutique Shopify | 24 / 24 | render: true | 100 % | 58s | ~2 min | ~0,002 $ |
| E: Grand multi-catégories | 1 200 / 1 200 | no-render | 100 % | 0s | ~55 min | 0 $ |
Quelle est la vitesse de Cloudflare /crawl avec vs. sans rendu ?
La comparaison la plus claire vient de Store B, où nous avons exécuté les deux modes sur exactement les mêmes 256 pages :
Le schéma sur l’ensemble des onze crawls est cohérent : le crawl sans rendu est considérablement plus rapide. Le temps réel sans rendu correspond principalement à la file d’attente interne et au surcoût de récupération de Cloudflare. Le rendu complet ajoute environ 5 secondes de temps navigateur par page en plus de cette base.
Combien coûte un crawl Cloudflare entièrement rendu par page ?
La tarification Browser Rendering de Cloudflare est basée sur les heures navigateur, le temps que leur navigateur headless passe à rendre activement vos pages. Le crawl sans rendu utilise zéro heure navigateur et est gratuit pendant la bêta.
Plan Workers Free : 10 minutes de temps navigateur par jour. Le endpoint /crawl est en outre limité à 5 tâches de crawl par jour, avec un maximum de 100 pages par crawl.
Plan Workers Paid (5 $/mois) : 10 heures de temps navigateur par mois incluses. Au-delà, vous payez 0,09 $ par heure navigateur supplémentaire. Pas de limites par crawl sur le endpoint /crawl. Jusqu’à 600 requêtes API par minute.
Voici ce que nos crawls de test ont réellement coûté à 0,09 $/h :
| Crawl | Temps navigateur utilisé | Coût à 0,09 $/h |
|---|---|---|
| Store D : 24 pages rendues | 58 secondes | ~0,002 $ |
| Store B : 256 pages rendues | 1 338 secondes (~22 min) | ~0,03 $ |
| Catalogue de 3 000 pages (estimé) | ~4 heures | ~0,36 $ |
À environ 5 secondes de temps navigateur par page, tous ces coûts restent largement dans les 10 heures incluses dans le plan payant. Un crawl rendu de 3 000 pages utiliserait environ 4 de vos 10 heures incluses, ce qui signifie que vous pourriez exécuter deux crawls complets par mois avant de payer quoi que ce soit au-delà des 5 $ de base. Le crawl sans rendu est gratuit et n’a aucun coût de temps navigateur sur aucun des deux plans.
Quand faut-il désactiver le rendu vs. utiliser le rendu complet sur Cloudflare /crawl ?
Le bilan
Pour la plupart des boutiques Shopify avec un contenu rendu côté serveur, le crawl sans rendu vous donne plus de 90 % du contenu utile à coût zéro en une fraction du temps.
Ce que nous avons appris en testant Cloudflare /crawl sur des boutiques Shopify
Après avoir exécuté 11 crawls sur 5 boutiques Shopify en production et analysé les logs serveur complets, voici les constats les plus importants.
90 % du contenu est récupéré sans rendu
Pour les boutiques Shopify avec des pages standard rendues côté serveur, le crawl sans rendu JavaScript a capturé plus de 90 % du contenu utile. L’augmentation de 14 % du contenu avec le rendu complet provenait presque entièrement d’éléments chargés par JavaScript sur les pages d’accueil et d’index. Les pages produits et articles de blog individuels étaient presque identiques dans les deux cas. À moins que votre boutique ne soit construite comme une application monopage, vous n’avez probablement pas besoin du rendu complet.
Le rendu complet crée un multiplicateur de trafic de 89x
Le rendu de 25 pages a généré 2 234 requêtes serveur. Seulement 25 d’entre elles concernaient du contenu de page réel. Les 98,9 % restants étaient des fichiers JavaScript (75 %), des balises d’analyse (6,3 %), du CSS (4,3 %), des pixels de suivi (3,4 %) et des préchargements de checkout (3,3 %). Chaque page rendue déclenche toute la pile client Shopify comme si un vrai client naviguait.
Vos analytics Shopify sont probablement gonflées
Les crawls rendus déclenchent toute la pile analytique de Shopify : balises monorail, événements de suivi, préchargements Shop Pay et scripts web-pixel. Nous pensons que cela signifie que Shopify Analytics compte ceux-ci comme de vraies sessions de visiteurs. Si c’est le cas, un seul crawl rendu pourrait gonfler vos compteurs de sessions, de pages vues et les données de votre tunnel de conversion. Nous ne l’avons pas confirmé directement dans les rapports Shopify, mais les logs serveur montrent tous les mêmes événements analytiques se déclenchant que pour un vrai client.
Le rendu complet peut contourner les limites de débit de la boutique
Store D a renvoyé des erreurs 429 sur chaque page sans rendu. Passer au rendu complet sur la même boutique a produit un taux de succès de 100 %. Si vous atteignez des limites de débit sans rendu, le rendu complet est votre solution.
La découverte par sitemap est plus fiable que la découverte par liens
La découverte par liens par défaut n’a presque rien trouvé sur Store D car la page d’accueil avait très peu de liens internes. Passer à la découverte par sitemap a trouvé les 24 pages. Utilisez toujours la découverte par sitemap.
Le crawler provient de 5 centres de données américains
Cloudflare distribue la charge de travail de rendu à travers son réseau edge. Notre crawl provenait de 23 IPs uniques réparties entre Atlanta (38 %), Chicago (25 %), Miami (23 %), Newark (9 %) et Washington DC (5 %). Toutes les IPs sont dans la plage 104.28.x.x.
Deux lacunes d’empreinte l’identifient comme un bot
Le moteur de rendu omet les en-têtes sec-ch-ua Client Hints (le vrai Chrome les envoie toujours) et utilise HTTP/1.1 au lieu de HTTP/2 ou HTTP/3. Si vous construisez des règles de détection de bots, ce sont des signaux fiables.
Le rendu peut en fait renvoyer moins de contenu
Sur Store E, le crawl sans rendu a renvoyé 6,8 % de contenu en plus par page que le crawl rendu. Le blocage des images, polices et feuilles de style pour optimiser le temps navigateur a également empêché certains JavaScript de peupler des éléments dynamiques. Le HTML statique contenait déjà tout. Pour les boutiques Shopify rendues côté serveur, le rendu ne garantit pas de capturer plus de contenu.
Le blocage de ressources empêche les crawls bloqués
Sans blocage de ressources, le crawl rendu sur Store E s’est bloqué à 99 pages sur 100 et ne s’est jamais terminé. L’activation du blocage des images, médias, polices et feuilles de style avec une condition d’attente domcontentloaded a terminé les 100 pages et réduit le temps navigateur de 27 %. Si vos crawls rendus stagnent avant de se terminer, le blocage de ressources est la solution.
Le crawl-delay de robots.txt prolonge le temps réel d’exécution
Le robots.txt de Store E spécifie un crawl-delay de 10 secondes. Dans nos données de sondage sans rendu, cela apparaissait comme des plateaux de plusieurs minutes où le compteur de pages stagnait avant de reprendre. Le crawler Cloudflare respecte les directives crawl-delay, donc les sites avec des délais agressifs auront des temps réels d’exécution significativement plus longs que ce que le nombre de pages seul suggérerait.
Le coût est faible mais le plan gratuit a des limites
Le rendu de 256 pages a coûté environ 0,03 $ à 0,09 $ par heure navigateur. Le rendu de 24 pages a coûté environ 0,002 $. Le plan Workers Free plafonne le temps navigateur à 10 minutes par jour avec un maximum de 5 tâches de crawl et 100 pages par crawl. Le plan Workers Paid (5 $/mois) inclut 10 heures de temps navigateur par mois sans limite par crawl. Un crawl rendu de 3 000 pages utiliserait environ 4 de ces 10 heures incluses, donc la plupart des boutiques tiennent confortablement dans le plan payant sans dépassement. Le crawl sans rendu utilise zéro temps navigateur et est gratuit sur l’un ou l’autre plan pendant la bêta.
Les avantages
Vitesse
Les pages sont récupérées quasi instantanément par rapport à un crawl Scrapy de plusieurs heures avec autothrottle. Pas de file d’attente, pas de délais de politesse, pas d’attente que votre spider traite des milliers de requêtes à un rythme respectueux.
Sortie Markdown
Le endpoint renvoie du HTML-to-Markdown pré-converti pour chaque page. C’est directement utilisable pour l’ingestion LLM, les pipelines RAG et l’analyse de contenu sans aucun post-traitement. Vous sautez toute la couche d’extraction et passez directement au texte propre. Pour les équipes construisant des applications IA sur du contenu web, cela supprime une étape du pipeline.
Option de mode de rendu
Définir render: true exécute le JavaScript et extrait automatiquement les métadonnées Open Graph (og:title, og:description, og:image, og:site_name). Pour les sites lourds en JavaScript où le contenu est rendu côté client, c’est la différence entre voir la vraie page et voir une coquille vide.
Pas de soucis de proxy ni de limitation de débit
Cloudflare gère les mesures anti-bot et la limitation de débit sur sa propre infrastructure. Vous n’avez pas besoin de gérer des pools de proxy, de faire tourner les user-agents, ni de gérer les CAPTCHAs. Un seul appel API.
Crawl incrémental
Les paramètres modifiedSince et maxAge vous permettent d’ignorer les pages qui n’ont pas changé ou qui ont été récemment récupérées. Pour les crawls récurrents où vous surveillez les changements de contenu, cela économise du temps et du coût en ne traitant que les pages réellement nouvelles ou mises à jour.
Simplicité
Un seul appel API. Réponse JSON. Pas de code spider, pas de middleware, pas de pipelines d’items, pas de fichiers de configuration.
Bot bien comporté par défaut
Le crawler est un agent signé qui respecte le robots.txt, le crawl-delay et le contrôle AI Crawl de Cloudflare. Il s’identifie comme CloudflareBrowserRenderingCrawler/1.0 et ne peut pas contourner la protection bot ou les CAPTCHAs. Vous obtenez la conformité éthique du crawl sans construire la logique vous-même.
Ce que le endpoint Cloudflare Crawl ne prend pas en charge
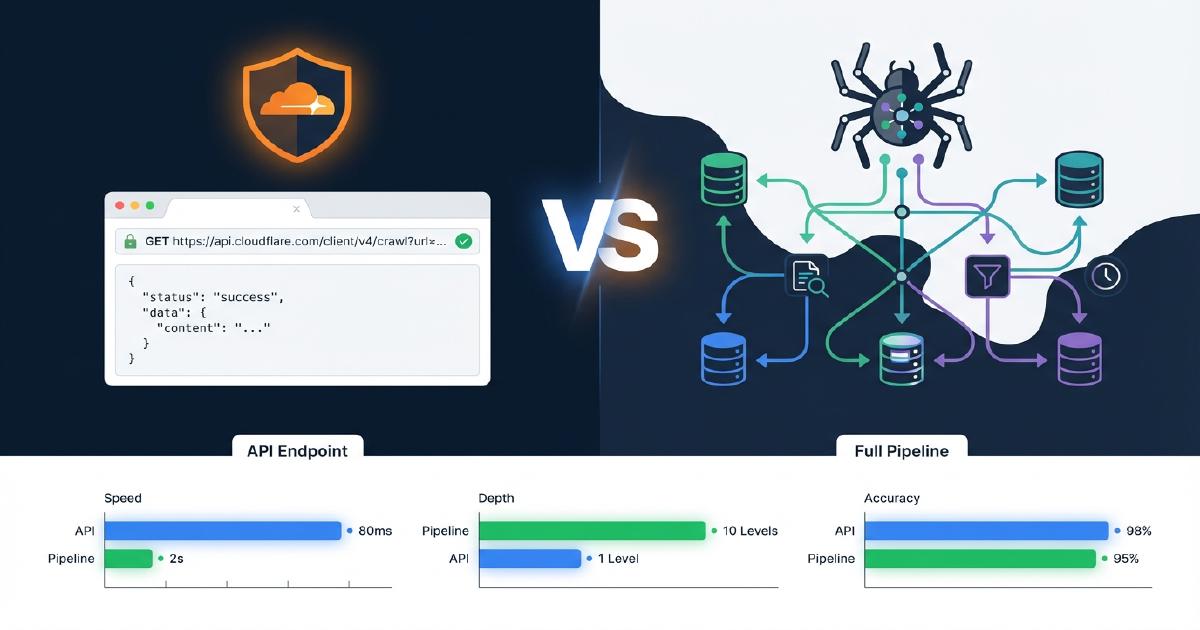
En quoi Cloudflare /crawl diffère-t-il d’un pipeline de crawl complet ?
Le tableau ci-dessous montre exactement quelles capacités sont présentes dans le endpoint /crawl de Cloudflare par rapport à un pipeline Scrapy de production. Ceci est basé sur nos tests réels contre des boutiques Shopify.
| Capacité | Cloudflare /crawl | Pipeline Scrapy |
|---|---|---|
| Récupération de contenu (HTML/Markdown) | Oui | Oui |
| Rendu JavaScript | Oui (render: true) |
Oui (Splash/Playwright) |
| Découverte de liens / spidering | Oui (liste plate) | Oui (graphe de crawl complet) |
| Mapping des liens parent-enfant | Non | Oui |
| Détection des pages orphelines | Non | Oui |
| Suivi des chaînes de redirection | Non | Oui |
| Extraction JSON-LD | Non | Oui |
| Extraction Microdata | Non | Oui |
| Validation de schema + rapports d’erreurs | Non | Oui |
| Codes de statut non-200 (404, 403) | Non | Oui (2 547 erreurs 404 capturées dans notre test) |
| Limite d’URLs | 100 000 | Aucune |
Quelles données structurées Cloudflare /crawl extrait-il ?
Avec render: false, aucune. Pas de JSON-LD, pas de Microdata, pas d’analyse OpenGraph.
Avec render: true, uniquement les balises OG basiques (og:title, og:description, og:image, og:site_name). Le JSON-LD et le balisage schema.org ne sont ni analysés, ni extraits, ni validés.
À titre de comparaison, notre pipeline Scrapy produit schemas_found, issues (contactPoint manquant, adresse, etc.), top_level_schemas et nested_schemas pour chaque URL. Vous pouvez voir quelles pages ont un schema Product, lesquelles n’ont pas de balisage Organization, et lesquelles ont des erreurs de validation qui amèneraient les systèmes IA à mal interpréter le contenu.
Quels codes de statut HTTP Cloudflare /crawl renvoie-t-il ?
Uniquement les réponses 200. Notre crawl Scrapy du même site a capturé 2 547 erreurs 404, plus des réponses 403 et des erreurs de connexion. La détection des 404 est critique pour l’analyse des pages fantômes, la correction des liens cassés et le mapping des redirections. Sans cela, vous manquez les pages qui fuient activement l’équité des liens et perturbent les crawlers IA.
Combien d’URLs Cloudflare /crawl peut-il traiter ?
Jusqu’à 100 000 par tâche. Cela couvre la plupart des sites, mais les grands catalogues e-commerce avec des centaines de milliers de pages produits, d’URLs de variantes et de pages de collections filtrées dépasseront le plafond. Scrapy n’a pas de limite d’URL intégrée.
Cloudflare /crawl a-t-il un bug de résolution d’URL ?
Nous avons trouvé 233 des 908 liens sur une seule page produit avec des chemins cassés. Le convertisseur markdown résout incorrectement les URLs relatives par rapport à l’URL de la page, produisant des URLs à double chemin comme /products/slug//www.example.com/.... C’est un bug confirmé dans le convertisseur de Cloudflare qui affecte toute analyse de liens en aval.
Quelle quantité de contenu passe-partout y a-t-il dans la sortie markdown de Cloudflare /crawl ?
La page moyenne renvoyait 158 Ko de markdown. Environ 90 % est du contenu de modèle répété : navigation complète, méga-menu et pied de page sur chaque enregistrement. Pour l’analyse de contenu, cela signifie un lourd travail de dédoublonnage, et pour l’utilisation de tokens LLM, le coût s’accumule rapidement. Vous avez besoin de votre propre logique d’extraction de contenu en plus du markdown pour isoler le contenu réel de la page.
Que ne classifie pas Cloudflare /crawl ?
Il n’y a pas de taggage par type de contenu. Les pages produits, pages collections, articles de blog et pages d’accueil reviennent tous comme des enregistrements indifférenciés. Scrapy classifie chaque URL par type, ce qui est essentiel pour comprendre la couverture du crawl par catégorie de page et pour identifier quels types de contenu les bots IA priorisent.
Quelles fonctionnalités de finalisation manquent à Cloudflare /crawl ?
Pas de captures d’écran de pages fantômes. Pas de comparaison de rendu JavaScript (ce que le bot voit par rapport à ce que le navigateur voit). Pas d’analyse des bots IA dans robots.txt. Pas de rapport de qualité de crawl. Pas de manifeste client. Pas de synchronisation CDN. Les données Cloudflare sont du contenu brut uniquement. Chaque élément du pipeline de reporting et d’analyse devrait être construit séparément.
Combien coûte Cloudflare /crawl pour les grands sites ?
À travers nos tests, render: true a nécessité en moyenne environ 5 secondes d’exécution navigateur par page. Un crawl de 256 pages a utilisé 1 338 secondes navigateur (22 minutes) et a coûté environ 0,03 $ à 0,09 $ par heure navigateur. Un crawl de 24 pages a utilisé 58 secondes navigateur et a coûté environ 0,002 $. Extrapolation à un catalogue de 3 000 pages : environ 4 heures de temps navigateur. Le plan Workers Free est limité à 10 minutes de temps navigateur par jour, 5 tâches de crawl par jour et 100 pages par crawl. Le plan Workers Paid (5 $/mois) inclut 10 heures de temps navigateur par mois sans limite par crawl, donc un crawl de 3 000 pages utiliserait environ 4 de ces 10 heures incluses. render: false utilise zéro temps navigateur et est gratuit pendant la bêta sur l’un ou l’autre plan.
Le verdict
Le endpoint crawl de Cloudflare est idéal pour :
- Des instantanés de contenu rapides quand vous avez besoin du texte de la page rapidement
- Du markdown prêt pour LLM pour les pipelines RAG et l’ingestion de contenu
- Des vérifications de pages ad hoc quand vous connaissez les URLs exactes dont vous avez besoin
- Des extractions de contenu à l’échelle du site quand vous avez besoin de texte markdown sans construire un spider
Il ne peut pas remplacer un pipeline de crawl complet car la valeur du pipeline réside dans :
- Le graphe de crawl complet avec topologie des liens, détection des orphelins et couverture des 404
- L’extraction et la validation des données structurées (JSON-LD, Microdata, OpenGraph)
- La classification du contenu par type de page
- L’ensemble du pipeline de finalisation incluant l’analyse des pages fantômes, la comparaison de rendu JavaScript, les rapports de schema et le scoring de préparation LLM
La meilleure approche hybride
Utilisez Cloudflare comme source de données complémentaire. Après qu’un crawl complet a identifié vos URLs, utilisez la sortie markdown de Cloudflare pour alimenter le scoring de préparation LLM ou l’analyse de qualité du contenu là où vous avez besoin du texte réel de la page plutôt que des métadonnées structurées. Le pipeline de crawl découvre et classifie. Le endpoint Cloudflare livre du texte propre pour les pages qui comptent.
Vous souhaitez voir le pipeline de crawl complet en action ?
Planifier un appelQuestions fréquemment posées
Quelles fonctionnalités d'audit de site ne sont pas prises en charge par Cloudflare /crawl ?
Cloudflare /crawl ne prend pas en charge : la construction d'un graphe de crawl complet, le mapping des liens parent-enfant, la détection des pages orphelines, le suivi des chaînes de redirection, l'extraction JSON-LD ou Microdata, la validation de schema, la capture des codes de statut non-200 (404, 403), la classification par type de contenu, la mesure de la taille en octets des pages, la détection des pages fantômes, la comparaison du rendu JS vs HTML, l'analyse des bots IA dans robots.txt, ni le croisement des backlinks. C'est un outil de récupération de contenu, pas un outil d'audit de site.
En quoi Cloudflare /crawl diffère-t-il de Scrapy pour le crawl e-commerce ?
Cloudflare /crawl récupère le contenu rapidement sans infrastructure à gérer. Scrapy construit un graphe de crawl complet avec la topologie des liens, extrait et valide les données structurées (JSON-LD, Microdata, OpenGraph), capture tous les codes de statut HTTP y compris les 404, classifie les pages par type de contenu, et alimente un pipeline en aval pour l'analyse des pages fantômes, les rapports de schema et le scoring de préparation LLM. Cloudflare vous donne le texte de la page ; Scrapy vous donne l'architecture complète du site.
Quelle est la limite exacte d'URL pour Cloudflare /crawl ?
100 000 URLs par tâche de crawl. La valeur par défaut de limit est 10, vous devez donc la définir explicitement. La profondeur maximale (depth) est également de 100 000. Pour les sites dépassant 100K pages, Scrapy ou un autre crawler sans plafond d'URL intégré est nécessaire.
Cloudflare /crawl extrait-il le JSON-LD ou valide-t-il le balisage schema ?
Non. Avec render: false, aucune donnée structurée n'est extraite. Avec render: true, seules les balises Open Graph basiques sont renvoyées (og:title, og:description, og:image, og:site_name). Le JSON-LD, les Microdata et le balisage schema.org ne sont ni analysés, ni extraits, ni validés dans aucun des deux modes.
Combien coûte Cloudflare /crawl pour le rendu de grands sites ?
À travers nos tests, render: true a nécessité en moyenne environ 5 secondes de temps navigateur par page. Un site de 256 pages a utilisé 1 338 secondes navigateur (22 minutes) et a coûté environ 0,03 $ à 0,09 $ par heure navigateur. Un site de 24 pages a utilisé 58 secondes et a coûté environ 0,002 $. Extrapolation à un catalogue de 3 000 pages : environ 4 heures de temps navigateur. Le plan Workers Free est limité à 10 minutes par jour, 5 tâches de crawl par jour et 100 pages par crawl, donc les grands crawls rendus nécessitent le plan Workers Paid (5 $/mois), qui inclut 10 heures de temps navigateur par mois sans limite par crawl. render: false utilise zéro temps navigateur et est gratuit pendant la bêta sur l'un ou l'autre plan.
Cloudflare /crawl a-t-il un bug connu de résolution d'URL ?
Oui. Dans notre test, 233 des 908 liens sur une seule page produit avaient des chemins malformés. Le convertisseur markdown ajoute l'URL de la page devant les chemins relatifs comme //www.example.com/cdn/..., créant des URLs à double chemin cassées. Cela affecte toute analyse de graphe de liens ou audit de liens internes construit à partir de la sortie markdown.
Pourquoi Cloudflare /crawl avec render false renvoie-t-il des erreurs 429 sur certaines boutiques Shopify ?
render: false effectue une récupération HTML brute sans navigateur headless. Dans l'un de nos tests, render: false a renvoyé des erreurs 429 tandis que render: true a fonctionné avec un taux de succès de 100 % sur la même boutique. Nous n'avons pas re-testé cela avec une gestion d'erreurs améliorée, donc les 429 ont pu être causés par la limitation de débit de la boutique, des problèmes transitoires de l'API, ou une combinaison des deux. Si vous voyez des erreurs 429 sans rendu, essayez render: true en premier recours.
Cloudflare /crawl accepte-t-il une liste d'URLs ?
Non. Le endpoint prend une seule URL de départ et découvre les pages en explorant vers l'extérieur via les sitemaps, les liens de page, ou les deux. Si vous avez déjà une liste d'URLs et souhaitez la conversion markdown de Cloudflare, utilisez les endpoints séparés /markdown ou /scrape, qui acceptent des URLs individuelles par requête.
Pourquoi Cloudflare /crawl avec source all ne trouve-t-il qu'une seule page sur certains sites ?
Le source: all par défaut découvre les URLs à partir des sitemaps et des liens de page. Si l'URL de départ a très peu de liens internes (courant sur les pages d'accueil minimalistes ou les SPAs lourdes en JavaScript), le crawler peut ne pas trouver de pages supplémentaires par la découverte de liens seule. Passez à source: sitemaps pour vous assurer que le crawler lit le fichier sitemap.xml complet et découvre toutes les URLs listées.
Quelle est la meilleure façon d'utiliser Cloudflare /crawl avec un pipeline de crawl complet ?
Utilisez d'abord le pipeline de crawl complet (Scrapy ou équivalent) pour découvrir les URLs, construire le graphe de liens, extraire les données structurées, capturer les 404 et classifier le contenu. Ensuite, utilisez les endpoints /markdown ou /scrape de Cloudflare pour récupérer du markdown propre pour le scoring de préparation LLM, l'analyse de qualité du contenu, ou l'ingestion RAG là où vous avez besoin du texte réel de la page plutôt que des métadonnées structurées.
Quelle est la différence de vitesse entre Cloudflare /crawl render false et render true ?
Dans notre test comparatif direct sur le même site de 256 pages, render: false s'est terminé en environ 5 minutes. render: true a pris environ 25 minutes pour les mêmes pages. C'est une différence de vitesse de 5x. L'écart de temps réel provient d'environ 5 secondes d'exécution navigateur ajoutées par page lorsque le rendu est activé. render: false a coûté 0 $ pendant la bêta. render: true a coûté environ 0,03 $ pour le même crawl.
Combien de contenu supplémentaire Cloudflare /crawl render true capture-t-il par rapport à render false ?
Dans notre test de 256 pages, render: true a produit 12,5 Mo de markdown contre 11,0 Mo avec render: false, soit une augmentation de 14 %. Le contenu supplémentaire provenait presque entièrement d'éléments chargés par JavaScript sur la page d'accueil et les pages d'index de blog. Les pages produits et articles de blog individuels étaient presque identiques entre les deux modes. Pour les sites avec du contenu principalement rendu côté serveur, render: false capture plus de 90 % du texte utile à coût zéro et 5x plus rapidement.
Cloudflare /crawl fonctionne-t-il de manière fiable sur toutes les boutiques Shopify ?
Cela dépend de la boutique et du mode de rendu. Dans nos tests sur cinq boutiques Shopify : Store A (grand catalogue) a atteint 100 % de succès avec render: false. Store B (prêt-à-porter moyen) a atteint 96 % de succès avec les deux modes. Store C (santé et compléments) a atteint 40 % sur un échantillon de 5 pages et 89 % sur un crawl de 100 pages avec render: false, bien que notre test initial manquait de récupération d'erreurs robuste et certains échecs auraient pu être récupérables. Store D (petite boutique) a renvoyé des erreurs 429 avec render: false mais a atteint 100 % avec render: true. Store E (grand multi-catégories, ~1 200 pages) a atteint 100 % de succès avec render: false et 100 % sur un échantillon rendu de 100 pages avec des optimisations de blocage de ressources. Nous n'avons pas re-testé Stores C et D avec une gestion d'erreurs améliorée. Testez les deux modes sur votre boutique spécifique avant de vous engager dans une stratégie de crawl.
Quel est le temps réel d'exécution pour un Cloudflare /crawl de 500 pages avec render false ?
Dans notre test, un crawl render: false de 500 pages s'est terminé en environ 18 minutes avec un taux de succès de 100 %. Un crawl de 256 pages sur une autre boutique s'est terminé en environ 5 minutes. Un crawl de 100 pages s'est terminé en environ 3,5 minutes. Ces temps réels sont des estimations basées sur les intervalles de sondage, pas des mesures précises. Le temps réel d'exécution correspond principalement à la file d'attente interne et au surcoût de récupération HTTP de Cloudflare, pas au rendu navigateur, puisque aucune seconde navigateur n'est utilisée avec render: false.
Combien de requêtes serveur un Cloudflare /crawl render true génère-t-il ?
Dans notre analyse des logs serveur, un seul crawl render: true de 25 pages a généré 2 234 requêtes au total : 2 071 GET et 163 POST. Soit environ 89 requêtes serveur par page effectivement rendue. Seulement 1,1 % des requêtes concernaient du contenu de page réel. Les 98,9 % restants étaient des fichiers JavaScript (75 %), des balises d'analyse (6,3 %), du CSS (4,3 %), des pixels de suivi (3,4 %) et des préchargements de checkout (3,3 %). Si vous surveillez le trafic bot ou gérez la charge serveur, attendez-vous à ce qu'un crawl rendu génère 89x le nombre de requêtes de pages réelles dans vos logs serveur.
Quel user-agent utilise Cloudflare /crawl et quelle est sa plage d'IP ?
Le crawler s'identifie comme CloudflareBrowserRenderingCrawler/1.0 sur 100 % des requêtes. Dans nos logs, toutes les requêtes provenaient de 23 IPs uniques dans la plage 104.28.x.x réparties sur 5 centres de données Cloudflare aux États-Unis : ATL (38 %), ORD (25 %), MIA (23 %), EWR (9 %) et IAD (5 %). Il n'y a pas de rotation de user-agent ni de masquage d'IP. Le crawler est un bot signé et identifiable par conception.
Cloudflare /crawl gonfle-t-il les analytics et le nombre de visiteurs Shopify ?
Nous le pensons, mais ne l'avons pas confirmé directement dans les rapports Shopify. Parce que render: true exécute le JavaScript, il déclenche toute la pile analytique de Shopify sur chaque page : balises monorail, événements de suivi /api/collect, préchargements de checkout Shop Pay et scripts web-pixel sandbox. Dans notre test, 163 des 2 234 requêtes étaient des requêtes POST vers des endpoints analytiques Shopify. Ce sont les mêmes événements qui se déclenchent pour les vrais clients. Si Shopify les compte comme de vraies sessions, vos compteurs de sessions, pages vues et données de tunnel de conversion seraient gonflés.
Comment détecter Cloudflare /crawl dans les logs serveur par rapport au trafic de vrais navigateurs ?
Deux lacunes d'empreinte fiables : le moteur de rendu navigateur de Cloudflare omet les en-têtes sec-ch-ua Client Hints (un vrai navigateur Chrome les envoie toujours), et toutes les requêtes utilisent HTTP/1.1 au lieu de HTTP/2 ou HTTP/3 qu'un vrai navigateur négocierait. Il envoie bien les en-têtes sec-fetch-dest, sec-fetch-mode et sec-fetch-site corrects qui correspondent au vrai Chrome. Le user-agent est toujours CloudflareBrowserRenderingCrawler/1.0 et toutes les IPs sont dans la plage 104.28.x.x.