
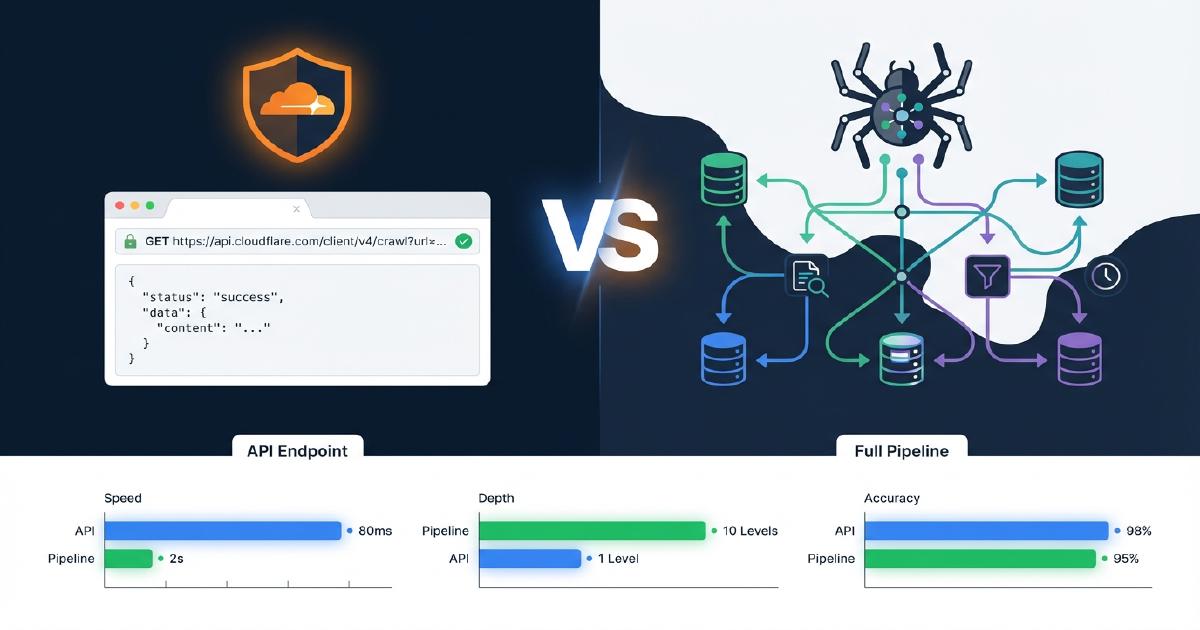
Що таке ендпоінт Cloudflare /crawl?
Ендпоінт /crawl від Cloudflare є частиною їхнього Browser Rendering API, який наразі перебуває у відкритій бета-версії. Він збирає контент зі стартового URL, переходить за посиланнями по сайту до налаштованої глибини або ліміту сторінок та повертає результати у вигляді HTML, Markdown або структурованого JSON на базі Workers AI. Cloudflare позиціонує його як інструмент для навчання моделей, побудови RAG-конвеєрів та дослідження або моніторингу контенту на сайті.
Ендпоінт працює як підписаний агент, який за замовчуванням дотримується robots.txt та Cloudflare AI Crawl Control, що є помітним дизайнерським рішенням. Він створений для того, щоб розробникам було легко дотримуватися правил вебсайтів, а краулерам було складніше ігнорувати настанови власників сайтів.
Ендпоінт розташований за адресою:
https://api.cloudflare.com/client/v4/accounts/<account_id>/browser-rendering/crawl
Для використання потрібен API-токен Cloudflare з дозволом Browser Rendering Edit.
Як це працює
Обхід виконується як асинхронне завдання у два кроки:
- Запуск обходу POST-запитом зі стартовим URL. API одразу повертає ідентифікатор завдання.
- Опитування результатів GET-запитами з використанням цього ідентифікатора завдання. Коли статус завдання змінюється з
runningнаcompleted, ваші зібрані дані готові.
Завдання можуть виконуватися до семи днів. Результати зберігаються протягом 14 днів після завершення.
Що ви надсилаєте
Як мінімум, ви надсилаєте URL:
curl -X POST 'https://api.cloudflare.com/client/v4/accounts/{account_id}/browser-rendering/crawl' \
-H 'Authorization: Bearer <apiToken>' \
-H 'Content-Type: application/json' \
-d '{
"url": "https://example.com"
}'
Ключові параметри
| Параметр | За замовчуванням | Що робить |
|---|---|---|
limit |
10 | Максимум сторінок для обходу (до 100 000) |
depth |
100,000 | Максимальна глибина посилань від стартового URL |
source |
all |
Де виявляти URL: all, sitemaps або links |
formats |
HTML | Формат відповіді: html, markdown або json |
render |
true | Виконувати JavaScript (true) або швидке завантаження HTML (false) |
maxAge |
86,400 | TTL кешу в секундах (максимум 604 800) |
modifiedSince |
немає | Unix timestamp: обходити лише сторінки, змінені після цього часу |
options.includePatterns |
немає | Обходити лише URL, що відповідають цим шаблонам з підстановками |
options.excludePatterns |
немає | Пропускати URL, що відповідають цим шаблонам |
Що ви отримуєте назад
Кожна обійдена сторінка повертається як запис з URL, статусом, контентом у вибраному форматі та базовими метаданими (HTTP-код стану, заголовок сторінки, кінцевий URL після перенаправлень). З render: true ви також отримуєте теги Open Graph. Відповідь також включає browserSecondsUsed для прозорості білінгу та cursor для пагінації результатів, що перевищують 10 МБ.
Ось фактична відповідь на рівні завдання від обходу з рендерингом 24 сторінок реального магазину Shopify:
{
"job_id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890",
"status": "completed",
"total": 24,
"finished": 24,
"browserSecondsUsed": 58.38,
"record_count": 24,
"records": [
{
"url": "https://www.example-store.com/products/premium-widget-bundle",
"status": "completed",
"metadata": {
"status": 200,
"title": "Premium Widget Bundle | Example Store",
"url": "https://www.example-store.com/products/premium-widget-bundle",
"lastModified": "",
"og:type": "product",
"og:site_name": "Example Store",
"og:title": "Premium Widget Bundle | Example Store",
"og:image": "https://www.example-store.com/cdn/shop/files/product-image.jpg",
"og:description": "Our best-selling bundle with everything you need..."
},
"markdown": "Store\n\nexample-store\n\nURL\n\nhttps://www.example-store.com\n\nCurrency\n\nUSD\n\n# Premium Widget Bundle\n\nOur best-selling bundle with everything you need..."
}
]
}
З render: true об’єкт metadata включає повний набір полів Open Graph: тип, назву сайту, заголовок, URL зображення та опис. Вони витягуються з OG мета-тегів сторінки під час рендерингу браузером. З render: false metadata містить лише HTTP-код стану, заголовок сторінки та кінцевий URL. Поля Open Graph не витягуються.
Поле markdown містить весь вивід сторінки, а не лише основний контент. Навігаційні меню, мега-меню, футери та повторювані шаблонні блоки включені в кожен запис. У наших тестах середня сторінка повернула приблизно 158 КБ markdown, з яких приблизно 90% складав повторюваний шаблонний код. Якщо ви подаєте це в LLM або RAG-конвеєр, вам знадобиться власна логіка витягування контенту для видалення шаблону та виділення фактичного контенту сторінки.
Ось що той самий магазин повернув, коли ми запустили render: false:
{
"job_id": "f9e8d7c6-b5a4-3210-fedc-ba9876543210",
"status": "completed",
"total": 266,
"finished": 266,
"browserSecondsUsed": 0,
"record_count": 256,
"records": [
{
"url": "https://www.example-store.com/products/classic-knit-sweater",
"status": "completed",
"metadata": {
"status": 200,
"title": "Classic Knit Sweater | Example Store",
"url": "https://www.example-store.com/products/classic-knit-sweater",
"lastModified": ""
},
"markdown": "Skip to content\n\nFree Shipping $150+\n\n# Classic Knit Sweater\n\nOur best-selling sweater made from premium natural fibers..."
}
]
}
Нуль браузерних секунд, 256 записів із 266 сторінок. Metadata мінімальні порівняно з версією з рендерингом: жодних полів Open Graph, лише HTTP-статус, заголовок сторінки та URL. Але markdown все одно містить повний контент сторінки, включаючи навігацію, деталі товарів та футер. Для магазинів Shopify із серверним рендерингом статичний HTML вже має все необхідне.
Виявлення URL
Краулер виявляє URL через три джерела (коли source встановлено на all):
- Стартовий URL, який ви надаєте
- Посилання з карти сайту, знайдені на домені
- Внутрішні посилання, знайдені на обійдених сторінках
Ви можете обмежити це лише картами сайту або лише посиланнями на сторінках за допомогою параметра source. excludePatterns завжди має пріоритет над includePatterns, тому ви можете закинути широку сітку, а потім вирізати секції, які вам не потрібні.
Рендеринг проти швидкого завантаження
render: true (за замовчуванням) запускає headless-браузер, виконує JavaScript та чекає повного завантаження сторінки. Це необхідно для односторінкових додатків та контенту, що рендериться через JavaScript, але використовує браузерні секунди, за які стягується плата.
render: false виконує швидке завантаження HTML без виконання JavaScript. Під час бета-версії ці запити не тарифікуються. Це правильний вибір для статичних сайтів або сторінок із серверним рендерингом, де контент вже є у початковому HTML.
Білінг та доступність
Ендпоінт доступний як на безкоштовному, так і на платному планах Workers. Обходи з рендерингом тарифікуються за цінами Cloudflare Browser Rendering: $0.09 за годину браузерного часу понад включений обсяг.
Workers Free: 10 хвилин браузерного часу на день. Ендпоінт /crawl обмежений 5 завданнями на день, 100 сторінками на обхід та 6 API-запитами на хвилину.
Workers Paid ($5/місяць): 10 годин браузерного часу на місяць включено. Без обмежень на обхід. 600 API-запитів на хвилину. Додаткові браузерні години коштують $0.09 кожна.
Обходи з render: false не використовують браузерний час. Вони безкоштовні під час бета-версії, але з часом підпадуть під стандартну тарифікацію Workers.
Що таке фактичний час?
Фактичний час (wall clock time), це загальний час від початку обходу до його завершення, виміряний так само, як ви б заміряли його секундоміром. Він включає все: мережеву затримку, внутрішній час черги Cloudflare, DNS-запити, час відповіді сервера та (якщо рендеринг увімкнено) час виконання браузера.
Фактичний час відрізняється від браузерного часу. Браузерний час враховує лише секунди, протягом яких headless-браузер Cloudflare активно рендерить сторінки. Обхід може використати 22 хвилини браузерного часу, але зайняти 25 хвилин фактичного через черги та мережеві накладні витрати. Обходи без рендерингу використовують нуль браузерного часу, але все одно мають фактичний час через процес завантаження та черги.
У наших бенчмарках ми наводимо обидва показники, щоб ви бачили, за що платите (браузерний час) та скільки фактично чекаєте (фактичний час).
Дрібний шрифт
Ендпоінт дотримується директив robots.txt, включаючи crawl-delay. Він ідентифікує себе як CloudflareBrowserRenderingCrawler/1.0. Він не обходить CAPTCHA, виклики Turnstile або інший захист від ботів. Якщо ви обходите власний сайт і вас блокують, потрібно створити правило пропуску WAF для дозволу краулера.
Як Cloudflare /crawl поводиться на п’яти магазинах Shopify
Ми запустили ендпоінт /crawl на п’яти реальних магазинах Shopify для вимірювання швидкості, успішності, вартості та взаємодії краулера з кожним сайтом. Усі назви магазинів анонімізовані. Це реальні числа з реальних обходів. Фактичний час є приблизними оцінками. Деякі ранні тести використовували скрипти з обмеженою обробкою помилок, що могло вплинути на повідомлені показники успішності для деяких магазинів. Де це застосовується, ми зазначаємо це нижче.
Це не ендпоінт, який налаштовується один раз і працює самостійно. Кожен магазин реагував по-різному на запити ендпоінта. Деяким потрібне блокування ресурсів для завершення обходу з рендерингом. Інші повертали помилки 429 в одному режимі, але працювали нормально в іншому. Директиви crawl-delay, кількість сторінок та архітектура магазину впливали на результат. Плануйте тестування та налаштування параметрів для кожного сайту, який ви обходите.
Тест 1: великий каталог інтернет-магазину (Store A)
Ми направили ендпоінт /crawl на великий магазин Shopify з майже 3 000 сторінками. Контент надходив швидко, markdown був придатний для використання, і ендпоінт без проблем отримував сторінки товарів, колекцій та блогу. Жодних проблем з проксі, блокувань чи обмежень швидкості.
Ми провели кілька обходів різного масштабу:
| Розмір обходу | Повернуто сторінок | Режим | Браузерний час | Фактичний час |
|---|---|---|---|---|
| Вибірка 20 сторінок | 20 / 20 (100%) | no-render | 0s | ~1 хв |
| Обхід 500 сторінок | 500 / 500 (100%) | no-render | 0s | ~18 хв |
| 5 сторінок з рендерингом | 4 / 5 (80%) | render: true | 0.9s | ~10s |
Обхід без рендерингу JavaScript досяг 100% успіху на обох масштабах. Повний рендеринг у браузері повернув 4 з 5 сторінок у маленькому тестовому зразку. На такій малій вибірці одна відсутня сторінка могла бути тайм-аутом браузера, тимчасовою помилкою або проблемою зі скриптом.
Тест 2: малий магазин Shopify (Store D, 24 сторінки)
Менший магазин, де ми протестували повний робочий процес:
Обхід без рендерингу повернув помилки. Наш початковий тест повернув відповіді 429 при звичайному завантаженні HTML. Ми не перетестовували цей магазин з покращеною обробкою помилок, тому не можемо підтвердити, чи 429 виникли через обмеження швидкості магазину, чи через тимчасові проблеми під час тесту.
Повний рендеринг з виявленням через карту сайту був повністю успішним. 24 з 24 сторінок обійдено, 100% завершення.
| Тип сторінки | Кількість |
|---|---|
| Товари | 9 |
| Колекції | 4 |
| Сторінки | 3 |
| Блоги/Новини | 5 |
| Інше (головна, індекс блогу) | 3 |
Важливе відкриття: стандартний режим виявлення URL знайшов лише 1 сторінку, тому що на головній було майже нуль внутрішніх посилань. Перемикання на виявлення через карту сайту знайшло всі 24. Якщо ваша головна сторінка мінімалістична або побудована на JavaScript, краулер може не знайти сторінки лише через посилання.
Тест 3: середній магазин одягу (Store B, 256 сторінок), з рендерингом та без
Наш найдетальніший тест. Середній магазин одягу з 256 індексованими сторінками: товари, колекції, записи блогу та інформаційні сторінки. Ми запустили обидва режими на повному сайті для вимірювання фактичної різниці.
| Метрика | render: false | render: true | Різниця |
|---|---|---|---|
| Обійдено сторінок | 256 / 266 | 256 / 266 | Однаково |
| Загальний вивід markdown | 11.0 МБ | 12.5 МБ | +14% |
| Браузерний час | 0s | 1 338s (22 хв) | +22 хв |
| Орієнтовна вартість | $0 (бета) | ~$0.03 | +$0.03 |
| Фактичний час | ~5 хв | ~25 хв | У 5 разів повільніше |
Тест 4: роздрібний продавець товарів для здоров’я та добавок (Store C), частковий успіх при масштабуванні
Великий роздрібний продавець товарів для здоров’я з масивним каталогом. Ми провели два обходи без рендерингу різного масштабу:
| Розмір обходу | Повернуто сторінок | Успішність | Фактичний час |
|---|---|---|---|
| Вибірка 5 сторінок | 2 / 5 | 40% | ~25s |
| Обхід 100 сторінок | 89 / 100 | 89% | ~3.5 хв |
Часткова успішність може вказувати на те, що інфраструктура цього магазину відхиляє деякі небраузерні запити, але наш початковий тест не мав надійного відновлення після помилок, тому деякі з цих збоїв могли бути відновлювальними при кращій обробці повторних спроб з нашого боку. Успішність зросла з 40% до 89% при більшому масштабі. Ми не перетестовували цей магазин з покращеною обробкою помилок для ізоляції причини.
Тест 5: великий мультикатегорійний магазин (Store E, ~1 200 сторінок)
Наш найбільший та найбільш показовий тест. Магазин Shopify з приблизно 1 200 URL, розподіленими між чотирма картами сайту: 521 товар, 626 колекцій, 22 сторінки та 31 запис блогу.
| Метрика | render: false | render: true (оптимізований) |
|---|---|---|
| Обійдено сторінок | 1,200 / 1,200 | 100 / 100 |
| Загальний вивід markdown | 148.5 МБ | 11.3 МБ |
| Браузерний час | 0s | 475s (~8 хв) |
| Орієнтовна вартість | $0 (бета) | ~$0.012 |
| Фактичний час | ~55 хв | ~12 хв |
Обхід без рендерингу досяг 100% успіху на всіх 1 200 сторінках з нульовою вартістю браузерного часу. Обхід з рендерингом проводився на вибірці з 100 сторінок з увімкненими оптимізаціями блокування ресурсів.
Блокування ресурсів стало різницею між застряглим обходом та чистим. Без блокування ресурсів обхід з рендерингом зависав на 99 із 100 сторінок на невизначений час та споживав 649 секунд браузерного часу для цих 99 сторінок. Увімкнення блокування ресурсів (зображення, медіа, шрифти, стилі) з умовою очікування domcontentloaded завершило всі 100 сторінок за 475 секунд, що означає зменшення браузерного часу на 27% без зависань.
Crawl-delay у robots.txt створив помітні затримки. robots.txt магазину Store E вказує 10-секундну crawl-delay для певних ботів. У наших даних опитування без рендерингу це проявлялося як багатохвилинні плато, де кількість сторінок зупинялася перед відновленням. Краулер Cloudflare дотримується директив crawl-delay, що безпосередньо подовжує фактичний час на сайтах, які їх встановлюють.
Що ендпоінт /crawl фактично приймає
Ендпоінт приймає один стартовий URL, а не список. Він виявляє сторінки шляхом обходу від цього URL через карти сайту, посилання на сторінках або обидва способи. Якщо у вас вже є список URL з обходу Scrapy і ви хочете використати Cloudflare для конвертації в markdown, вам потрібно буде викликати окремі ендпоінти /markdown або /scrape індивідуально для кожного URL.
Що Cloudflare /crawl фактично робить на стороні сервера?
Ми витягнули повні серверні логи під час повного обходу з рендерингом Store D (25 сторінок), щоб проаналізувати реальний відбиток трафіку. Результати виявляють фундаментальні відмінності між обходом з браузерним рендерингом та традиційним бот-обходом, з ненавмисними побічними ефектами для аналітики, серверного навантаження та моніторингу бот-трафіку.
| Метрика | Значення |
|---|---|
| User-Agent | CloudflareBrowserRenderingCrawler/1.0 (100% запитів) |
| Вікно обходу | 134 секунди (~2 хвилини) |
| Пікова пропускна здатність | 82 запити/секунду |
| Унікальних IP | 23, розподілених між 5 дата-центрами Cloudflare |
| GET-запити | 2 071 |
| POST-запити | 163 |
| Всього запитів | 2 234 |
| Фактично відрендерено сторінок | ~25 |
| Запитів на сторінку | ~89x підсилення |
Скільки трафіку фактично генерує повністю відрендерований обхід Cloudflare /crawl?
Найголовніше відкриття: лише 1.1% із 2 234 запитів були фактичним контентом сторінок. Решта 98.9% складали JavaScript, CSS, аналітичні маяки, трекінг-пікселі та попереднє завантаження checkout, спровоковані браузером, що завантажував кожну сторінку як реальний відвідувач.
Бот без рендерингу, як Amazonbot або ChatGPT-User, генерує 1 запит на сторінку. Браузерний рендерер Cloudflare генерує 89.
Чи спотворює Cloudflare /crawl аналітику Shopify?
163 POST-запити в наших логах були повністю аналітичними та трекінговими ендпоінтами Shopify, що спрацьовували під час обходу. Це ті самі події, що спрацьовують, коли реальний клієнт відвідує ваш магазин. З точки зору Shopify Analytics, краулер Cloudflare виглядає як відвідувач, що переглядає кожну сторінку вашого магазину за 2 хвилини.
Як швидко Cloudflare /crawl навантажує ваш сервер?
Усі 2 234 запити прийшли у 134-секундному вікні. Пікова пропускна здатність досягла 82 запитів на секунду. Краулер відрендерив увесь сайт з 25 сторінками трохи більш ніж за 2 хвилини, але сервер отримав стійкий сплеск трафіку, який зовсім не схожий на органічні патерни перегляду.
Для малих магазинів це прийнятно. Для більших магазинів з тисячами сторінок підсилення запитів (89x на сторінку) у поєднанні зі стійкою пропускною здатністю може створити значне навантаження на вихідний сервер, особливо якщо ви на спільному хостингу або маєте агресивне обмеження швидкості.
Звідки приходить Cloudflare /crawl?
Обхід був розподілений між 5 дата-центрами Cloudflare у США:
| Дата-центр | % запитів | Розташування |
|---|---|---|
| ATL | 38% | Атланта |
| ORD | 25% | Чикаго |
| MIA | 23% | Маямі |
| EWR | 9% | Ньюарк |
| IAD | 5% | Вашингтон |
Це не один сервер, що надсилає запити. Cloudflare розподіляє робоче навантаження рендерингу по своїй edge-мережі. Усі 23 IP потрапляли в діапазон 104.28.x.x, а user-agent був CloudflareBrowserRenderingCrawler/1.0 на кожному окремому запиті.
Який відбиток браузера залишає Cloudflare /crawl?
Рендерер надсилає належні заголовки Sec-Fetch, що імітують реальний браузер Chrome:
| Заголовок | Значення | Як у реальному Chrome? |
|---|---|---|
sec-fetch-dest |
script, document тощо |
Так, збігається |
sec-fetch-mode |
cors, navigate |
Так, збігається |
sec-fetch-site |
same-origin, cross-site |
Так, збігається |
sec-ch-ua (Client Hints) |
Не надсилається | Ні, реальний Chrome надсилає |
| Версія HTTP | HTTP/1.1 | Ні, реальний Chrome узгоджує HTTP/2 або HTTP/3 |
Два прогалини у відбитку виділяються: рендерер повністю пропускає заголовки sec-ch-ua Client Hints (реальний браузер Chrome завжди їх надсилає), і всі запити використовують HTTP/1.1 замість HTTP/2 або HTTP/3. Якщо ви будуєте правила виявлення ботів, це надійні сигнали для розрізнення браузерного рендерера Cloudflare від реального відвідувальницького трафіку.
Як Cloudflare /crawl порівнюється з іншими AI-ботами в серверних логах?
Ми порівняли обхід Cloudflare з іншими ботами, що зверталися до того ж магазину в тому ж 12-годинному вікні:
Amazonbot та ChatGPT-User завантажують сирий HTML: один запит, одна сторінка, без виконання JavaScript. AhrefsBot обходить карти сайту для виявлення. Браузерний рендерер Cloudflare виконує повну вітрину Shopify на кожній сторінці, активуючи кожен скрипт, піксель та попереднє завантаження так, ніби реальний клієнт переглядає магазин.
Швидкість та вартість Cloudflare /crawl: повний бенчмарк
Кожен обхід, який ми провели, в одній таблиці. Усі магазини анонімізовані, усі числа з реальних тестів. Фактичний час є приблизним. Показники успішності для Store C та Store D могли бути вплинуті обмеженою обробкою помилок у наших початкових тестових скриптах.
| Магазин | Сторінки | Режим | Успішність | Браузерний час | Фактичний час | Вартість |
|---|---|---|---|---|---|---|
| A: Великий інтернет-магазин | 500 / 500 | no-render | 100% | 0s | ~18 хв | $0 |
| B: Середній одяг | 256 / 266 | no-render | 96% | 0s | ~5 хв | $0 |
| C: Здоров’я та добавки | 89 / 100 | no-render | 89% | 0s | ~3.5 хв | $0 |
| D: Малий Shopify | 24 / 24 | render: true | 100% | 58s | ~2 хв | ~$0.002 |
| E: Великий мультикатегорійний | 1,200 / 1,200 | no-render | 100% | 0s | ~55 хв | $0 |
Наскільки швидкий Cloudflare /crawl з рендерингом та без?
Найчіткіше порівняння дає Store B, де ми запустили обидва режими на тих самих 256 сторінках:
Патерн у всіх одинадцяти обходах є послідовним: обхід без рендерингу значно швидший. Фактичний час без рендерингу складається переважно з внутрішніх накладних витрат черги та завантаження Cloudflare. Повний рендеринг додає приблизно 5 секунд браузерного часу на сторінку поверх цього базового рівня.
Скільки коштує повністю відрендерований обхід Cloudflare на сторінку?
Ціноутворення Cloudflare Browser Rendering базується на браузерних годинах, тобто часі, який їхній headless-браузер витрачає на активний рендеринг ваших сторінок. Обхід без рендерингу використовує нуль браузерних годин і є безкоштовним під час бета-версії.
Безкоштовний план Workers: 10 хвилин браузерного часу на день. Ендпоінт /crawl додатково обмежений 5 завданнями обходу на день з максимумом 100 сторінок на обхід.
Платний план Workers ($5/місяць): 10 годин браузерного часу на місяць включено. Понад це ви платите $0.09 за кожну додаткову браузерну годину. Без обмежень на обхід ендпоінта /crawl. До 600 API-запитів на хвилину.
Ось фактична вартість наших тестових обходів при $0.09/год:
| Обхід | Використано браузерного часу | Вартість при $0.09/год |
|---|---|---|
| Store D: 24 сторінки з рендерингом | 58 секунд | ~$0.002 |
| Store B: 256 сторінок з рендерингом | 1 338 секунд (~22 хв) | ~$0.03 |
| Каталог 3 000 сторінок (оцінка) | ~4 години | ~$0.36 |
При приблизно 5 секундах браузерного часу на сторінку всі ці витрати комфортно вкладаються в 10 годин, включених у платний план. Обхід з рендерингом 3 000 сторінок використає приблизно 4 з ваших 10 включених годин, тобто ви зможете провести два повних обходи на місяць без додаткової оплати понад базові $5. Обхід без рендерингу безкоштовний і не має вартості браузерного часу на жодному плані.
Коли пропускати рендеринг, а коли використовувати повний рендеринг у Cloudflare /crawl?
Підсумок
Для більшості магазинів Shopify із серверним рендерингом контенту обхід без рендерингу дає вам понад 90% корисного контенту без витрат за частку часу.
Що ми дізналися, тестуючи Cloudflare /crawl на магазинах Shopify
Після проведення 11 обходів на 5 реальних магазинах Shopify та аналізу повних серверних логів, ось відкриття, які мають найбільше значення.
90% контенту надходить без рендерингу
Для магазинів Shopify зі стандартними сторінками із серверним рендерингом обхід без рендерингу JavaScript захопив понад 90% корисного контенту. 14% збільшення контенту від повного рендерингу прийшло майже повністю від JavaScript-завантажених елементів на головних та індексних сторінках. Окремі сторінки товарів та статті блогу були практично ідентичними в обох випадках. Якщо ваш магазин не побудований як односторінковий додаток, вам, ймовірно, не потрібен повний рендеринг.
Повний рендеринг створює 89-кратний множник трафіку
Рендеринг 25 сторінок згенерував 2 234 серверних запити. Лише 25 з них були фактичним контентом сторінок. Решта 98.9% складали JavaScript-файли (75%), аналітичні маяки (6.3%), CSS (4.3%), трекінг-пікселі (3.4%) та попереднє завантаження checkout (3.3%). Кожна відрендерена сторінка активує повний клієнтський стек Shopify так, ніби реальний клієнт переглядає магазин.
Ваша аналітика Shopify, ймовірно, спотворюється
Обходи з рендерингом активують повний стек аналітики Shopify: маяки monorail, трекінг-події, попереднє завантаження Shop Pay та скрипти web-pixel. Ми вважаємо, що це означає, що Shopify Analytics рахує їх як реальні сесії відвідувачів. Якщо це так, один обхід з рендерингом може спотворити кількість сесій, перегляди сторінок та дані воронки конверсії. Ми не підтвердили це безпосередньо у звітності Shopify, але серверні логи показують усі ті самі аналітичні події, які спрацьовували б для реального клієнта.
Повний рендеринг може обійти обмеження швидкості магазину
Store D повертав помилки 429 на кожній сторінці без рендерингу. Перемикання на повний рендеринг на тому ж магазині дало 100% успіху. Якщо ви зіткнулися з обмеженнями швидкості без рендерингу, повний рендеринг є вашим рішенням.
Виявлення через карту сайту надійніше за виявлення через посилання
Стандартне виявлення через посилання майже нічого не знайшло на Store D, тому що на головній сторінці було дуже мало внутрішніх посилань. Перемикання на виявлення через карту сайту знайшло всі 24 сторінки. Завжди використовуйте виявлення через карту сайту.
Краулер приходить з 5 дата-центрів у США
Cloudflare розподіляє робоче навантаження рендерингу по своїй edge-мережі. Наш обхід прийшов з 23 унікальних IP з Атланти (38%), Чикаго (25%), Маямі (23%), Ньюарка (9%) та Вашингтона (5%). Усі IP потрапляють у діапазон 104.28.x.x.
Дві прогалини у відбитку ідентифікують його як бота
Рендерер пропускає заголовки sec-ch-ua Client Hints (реальний Chrome завжди їх надсилає) та використовує HTTP/1.1 замість HTTP/2 або HTTP/3. Якщо ви будуєте правила виявлення ботів, це надійні сигнали.
Рендеринг може фактично повертати менше контенту
На Store E обхід без рендерингу повернув на 6.8% більше контенту на сторінку, ніж обхід з рендерингом. Блокування зображень, шрифтів та стилів для оптимізації браузерного часу також запобігло деякому JavaScript заповнювати динамічні елементи. Статичний HTML вже мав усе. Для магазинів Shopify із серверним рендерингом, рендеринг не гарантує захоплення більшого обсягу контенту.
Блокування ресурсів запобігає застряглим обходам
Без блокування ресурсів обхід з рендерингом на Store E зависав на 99 із 100 сторінок і ніколи не завершувався. Увімкнення блокування зображень, медіа, шрифтів та стилів з умовою очікування domcontentloaded завершило всі 100 сторінок та зменшило браузерний час на 27%. Якщо ваші обходи з рендерингом зависають перед завершенням, блокування ресурсів є рішенням.
robots.txt crawl-delay подовжує фактичний час
robots.txt магазину Store E вказує 10-секундну crawl-delay. У наших даних опитування без рендерингу це проявлялося як багатохвилинні плато, де кількість сторінок зупинялася перед відновленням. Краулер Cloudflare дотримується директив crawl-delay, тому сайти з агресивними затримками матимуть значно довший фактичний час, ніж можна було б очікувати лише з кількості сторінок.
Вартість низька, але безкоштовний план має обмеження
Рендеринг 256 сторінок коштував приблизно $0.03 при $0.09 за браузерну годину. Рендеринг 24 сторінок коштував приблизно $0.002. Безкоштовний план Workers обмежує браузерний час до 10 хвилин на день з максимумом 5 завдань обходу та 100 сторінок на обхід. Платний план Workers ($5/місяць) включає 10 годин браузерного часу на місяць без обмежень на обхід. Обхід з рендерингом 3 000 сторінок використає приблизно 4 з цих 10 включених годин, тому більшість магазинів комфортно вкладається в платний план без перевитрат. Обхід без рендерингу використовує нуль браузерного часу і є безкоштовним на обох планах під час бета-версії.
Переваги
Швидкість
Сторінки завантажуються майже миттєво порівняно з багатогодинним обходом Scrapy з autothrottle. Без черг, без затримок ввічливості, без очікування, поки ваш spider опрацює тисячі запитів з поважним темпом.
Вивід у Markdown
Ендпоінт повертає попередньо конвертований HTML-to-Markdown для кожної сторінки. Це безпосередньо корисно для інтеграції в LLM, RAG-конвеєрів та аналізу контенту без будь-якої постобробки. Ви пропускаєте весь рівень витягування і переходите одразу до чистого тексту. Для команд, що будують AI-застосунки на основі контенту вебсайтів, це прибирає один крок з конвеєра.
Опція режиму рендерингу
Встановлення render: true виконує JavaScript та автоматично витягує метадані Open Graph (og:title, og:description, og:image, og:site_name). Для JavaScript-важких сайтів, де контент рендериться на клієнтській стороні, це різниця між баченням реальної сторінки та порожньої оболонки.
Без проблем з проксі або обмеженнями швидкості
Cloudflare обробляє засоби захисту від ботів та обмеження швидкості на власній інфраструктурі. Вам не потрібно керувати пулами проксі, ротувати user-agent або боротися з CAPTCHA. Один API-виклик.
Інкрементальний обхід
Параметри modifiedSince та maxAge дозволяють пропускати сторінки, які не змінилися або були нещодавно завантажені. Для регулярних обходів, де ви моніторите зміни контенту, це економить час та витрати, обробляючи лише сторінки, які фактично є новими або оновленими.
Простота
Один API-виклик. JSON-відповідь. Без коду spider, без middleware, без item-конвеєрів, без файлів налаштувань.
Коректний бот за замовчуванням
Краулер є підписаним агентом, який дотримується robots.txt, crawl-delay та Cloudflare AI Crawl Control. Він ідентифікує себе як CloudflareBrowserRenderingCrawler/1.0 і не може обійти захист від ботів або CAPTCHA. Ви отримуєте етичну відповідність обходу без побудови логіки самостійно.
Що не підтримує ендпоінт Cloudflare Crawl
Чим Cloudflare /crawl відрізняється від повного конвеєра обходу?
Таблиця нижче показує, які саме можливості присутні в ендпоінті /crawl від Cloudflare порівняно з виробничим конвеєром Scrapy. Це засновано на наших реальних тестах на магазинах Shopify.
| Можливість | Cloudflare /crawl | Конвеєр Scrapy |
|---|---|---|
| Отримання контенту (HTML/Markdown) | Так | Так |
| Рендеринг JavaScript | Так (render: true) |
Так (Splash/Playwright) |
| Виявлення посилань / обхід | Так (плоский список) | Так (повний граф обходу) |
| Відображення батьківських та дочірніх посилань | Ні | Так |
| Виявлення сирітських сторінок | Ні | Так |
| Відстеження ланцюжків перенаправлень | Ні | Так |
| Витягування JSON-LD | Ні | Так |
| Витягування Microdata | Ні | Так |
| Валідація схем + звітування про проблеми | Ні | Так |
| Не-200 коди стану (404, 403) | Ні | Так (захоплено 2 547 404-х у нашому тесті) |
| Ліміт URL | 100 000 | Немає |
Які структуровані дані витягує Cloudflare /crawl?
З render: false, жодних. Ні JSON-LD, ні Microdata, ні парсингу OpenGraph.
З render: true, лише базові OG-теги (og:title, og:description, og:image, og:site_name). JSON-LD та розмітка schema.org не парсяться, не витягуються та не валідуються.
Для порівняння, наш конвеєр Scrapy створює schemas_found, issues (відсутній contactPoint, address тощо), top_level_schemas та nested_schemas для кожного URL. Ви можете бачити, які сторінки мають Product schema, яким бракує Organization розмітки та які мають помилки валідації, що можуть спричинити неправильне читання контенту AI-системами.
Які HTTP-коди стану повертає Cloudflare /crawl?
Лише відповіді 200. Наш обхід Scrapy того ж сайту захопив 2 547 помилок 404, плюс відповіді 403 та помилки з’єднання. Виявлення 404 є критичним для аналізу привидних сторінок, виправлення зламаних посилань та створення карти перенаправлень. Без цього ви пропускаєте сторінки, які активно витрачають посилальну вагу та плутають AI-краулерів.
Скільки URL може обробити Cloudflare /crawl?
До 100 000 за завдання. Це покриває більшість сайтів, але великі каталоги інтернет-магазинів з сотнями тисяч сторінок товарів, URL варіантів та відфільтрованих сторінок колекцій перевищать ліміт. Scrapy не має вбудованого обмеження URL.
Чи має Cloudflare /crawl баг з розпізнаванням URL?
Ми виявили 233 із 908 посилань на одній сторінці товару зі зламаними шляхами. Конвертер markdown неправильно розпізнає відносні URL відносно URL сторінки, створюючи URL з подвійними шляхами, як /products/slug//www.example.com/.... Це підтверджений баг у конвертері Cloudflare, який впливає на будь-який подальший аналіз посилань.
Скільки шаблонного коду в markdown-виводі Cloudflare /crawl?
Середня сторінка повернула 158 КБ markdown. Приблизно 90% складає повторюваний шаблонний контент: повна навігація, мега-меню та футер у кожному окремому записі. Для аналізу контенту це означає значну роботу з дедуплікації, а для використання токенів LLM витрати швидко накопичуються. Вам потрібна власна логіка витягування контенту поверх markdown для виділення фактичного контенту сторінки.
Що Cloudflare /crawl не класифікує?
Немає тегування типу контенту. Сторінки товарів, сторінки колекцій, записи блогу та головні сторінки повертаються як недиференційовані записи. Scrapy класифікує кожен URL за типом, що є необхідним для розуміння покриття обходу за категорією сторінок та для визначення, які типи контенту пріоритизують AI-боти.
Які фінальні функції відсутні у Cloudflare /crawl?
Немає скріншотів привидних сторінок. Немає порівняння рендерингу JavaScript (що бачить бот проти того, що бачить браузер). Немає аналізу AI-ботів у robots.txt. Немає звіту про якість обходу. Немає маніфесту клієнта. Немає синхронізації CDN. Дані Cloudflare є лише сирим контентом. Кожен елемент конвеєра звітності та аналізу потрібно було б будувати окремо.
Скільки коштує Cloudflare /crawl для великих сайтів?
У наших тестах render: true в середньому використовував приблизно 5 секунд браузерного виконання на сторінку. Обхід 256 сторінок використав 1 338 браузерних секунд (22 хвилини) і коштував приблизно $0.03 при $0.09 за браузерну годину. Обхід 24 сторінок використав 58 браузерних секунд і коштував приблизно $0.002. Екстраполяція на каталог 3 000 сторінок: приблизно 4 години браузерного часу. Безкоштовний план Workers обмежений 10 хвилинами браузерного часу на день, 5 завданнями обходу на день та 100 сторінками на обхід. Платний план Workers ($5/місяць) включає 10 годин браузерного часу на місяць без обмежень на обхід, тому обхід 3 000 сторінок використає приблизно 4 з цих 10 включених годин. render: false не використовує браузерний час і є безкоштовним під час бета-версії на обох планах.
Підсумок
Ендпоінт crawl від Cloudflare чудово підходить для:
- Швидких знімків контенту, коли вам потрібен текст сторінки швидко
- LLM-готового markdown для RAG-конвеєрів та інтеграції контенту
- Перевірок окремих сторінок, коли ви знаєте точні URL, які вам потрібні
- Швидкого отримання контенту всього сайту, коли потрібен markdown-текст без побудови spider
Він не може замінити повний конвеєр обходу, тому що цінність конвеєра полягає в:
- Повному графі обходу з топологією посилань, виявленням сиріт та покриттям 404
- Витягуванні та валідації структурованих даних (JSON-LD, Microdata, OpenGraph)
- Класифікації контенту за типом сторінки
- Повному конвеєрі фіналізації, включаючи аналіз привидних сторінок, порівняння рендерингу JavaScript, звіти про схеми та оцінку готовності до LLM
Найкращий гібридний підхід
Використовуйте Cloudflare як допоміжне джерело даних. Після того як повний обхід визначить ваші URL, використовуйте markdown-вивід Cloudflare для подачі в оцінку готовності до LLM або аналіз якості контенту, де вам потрібен фактичний текст сторінки, а не структуровані метадані. Конвеєр обходу виявляє та класифікує. Ендпоінт Cloudflare надає чистий текст для сторінок, які мають значення.
Хочете побачити повний конвеєр обходу в дії?
Запланувати дзвінокЧасті запитання
Які функції аудиту вебсайтів не підтримуються Cloudflare /crawl?
Cloudflare /crawl не підтримує: побудову повного графу обходу, відображення батьківських та дочірніх посилань, виявлення сирітських сторінок, відстеження ланцюжків перенаправлень, витягування JSON-LD або Microdata, валідацію схем, захоплення не-200 кодів стану (404, 403), класифікацію типу контенту, вимірювання розміру сторінки в байтах, виявлення привидних сторінок, порівняння рендерингу JS та HTML, аналіз AI-ботів у robots.txt або перехресне порівняння зворотних посилань. Це інструмент для отримання контенту, а не для аудиту сайту.
Чим Cloudflare /crawl відрізняється від Scrapy для обходу інтернет-магазинів?
Cloudflare /crawl отримує контент швидко без необхідності керувати інфраструктурою. Scrapy будує повний граф обходу з топологією посилань, витягує та валідує структуровані дані (JSON-LD, Microdata, OpenGraph), захоплює всі HTTP-коди стану включаючи 404, класифікує сторінки за типом контенту та передає дані в нижчий конвеєр для аналізу привидних сторінок, звітів про схеми та оцінки готовності до LLM. Cloudflare дає вам текст сторінки, Scrapy дає вам повну архітектуру сайту.
Який точний ліміт URL для Cloudflare /crawl?
100 000 URL на одне завдання обходу. Стандартний limit становить 10, тому його потрібно встановлювати явно. Максимальна depth також 100 000. Для сайтів, що перевищують 100K сторінок, потрібен Scrapy або інший краулер без вбудованого обмеження URL.
Чи витягує Cloudflare /crawl JSON-LD або валідує розмітку schema?
Ні. З render: false структуровані дані не витягуються взагалі. З render: true повертаються лише базові теги Open Graph (og:title, og:description, og:image, og:site_name). JSON-LD, Microdata та розмітка schema.org не парсяться, не витягуються та не валідуються в жодному режимі.
Скільки коштує Cloudflare /crawl для рендерингу великих сайтів?
У наших тестах render: true в середньому використовував приблизно 5 секунд браузерного часу на сторінку. Сайт із 256 сторінками використав 1 338 браузерних секунд (22 хвилини) і коштував приблизно $0.03 при $0.09 за браузерну годину. Сайт із 24 сторінками використав 58 секунд і коштував приблизно $0.002. Екстраполяція на каталог 3 000 сторінок: приблизно 4 години браузерного часу. Безкоштовний план Workers обмежений 10 хвилинами на день, 5 завданнями обходу на день та 100 сторінками на обхід, тому великі обходи з рендерингом потребують платного плану Workers ($5/місяць), який включає 10 годин браузерного часу на місяць без обмежень на обхід. render: false не використовує браузерний час і є безкоштовним під час бета-версії на обох планах.
Чи має Cloudflare /crawl відомий баг з розпізнаванням URL?
Так. У нашому тесті 233 із 908 посилань на одній сторінці товару мали неправильні шляхи. Конвертер markdown додає URL сторінки до відносних шляхів, як //www.example.com/cdn/..., створюючи зламані URL з подвійними шляхами. Це впливає на будь-який подальший аналіз графу посилань або аудит внутрішніх посилань, побудований на основі markdown-виводу.
Чому Cloudflare /crawl з render false повертає помилки 429 на деяких магазинах Shopify?
render: false виконує сирий запит HTML без headless-браузера. В одному з наших тестів render: false повертав помилки 429, тоді як render: true працював зі 100% успіхом на тому ж магазині. Ми не перетестовували це з покращеною обробкою помилок, тому 429 могли бути спричинені обмеженням швидкості магазину, тимчасовими проблемами API або їх комбінацією. Якщо ви бачите помилки 429 без рендерингу, спробуйте render: true як перший крок.
Чи приймає Cloudflare /crawl список URL?
Ні. Ендпоінт приймає один стартовий URL і виявляє сторінки шляхом обходу через карти сайту, посилання на сторінках або обидва способи. Якщо у вас вже є список URL і ви хочете використати конвертацію в markdown від Cloudflare, використовуйте окремі ендпоінти /markdown або /scrape, які приймають окремі URL на запит.
Чому Cloudflare /crawl з source all знаходить лише одну сторінку на деяких сайтах?
Стандартний source: all виявляє URL як із карт сайту, так і з посилань на сторінках. Якщо стартовий URL має дуже мало внутрішніх посилань (типово для мінімалістичних домашніх сторінок або JavaScript-важких SPA), краулер може не знайти додаткових сторінок через виявлення посилань. Перемкніться на source: sitemaps, щоб краулер прочитав повний sitemap.xml та виявив усі перелічені URL.
Який найкращий спосіб використання Cloudflare /crawl з повним конвеєром обходу?
Спочатку використовуйте повний конвеєр обходу (Scrapy або еквівалент) для виявлення URL, побудови графу посилань, витягування структурованих даних, захоплення 404-х та класифікації контенту. Потім використовуйте ендпоінти /markdown або /scrape від Cloudflare для отримання чистого markdown для оцінки готовності до LLM, аналізу якості контенту або інтеграції в RAG, де вам потрібен фактичний текст сторінки, а не структуровані метадані.
Наскільки швидше Cloudflare /crawl render false порівняно з render true?
У нашому прямому тесті на тому ж сайті з 256 сторінками render: false завершився приблизно за 5 хвилин. render: true зайняв приблизно 25 хвилин для тих самих сторінок. Це 5-кратна різниця у швидкості. Різниця у фактичному часі виникає через приблизно 5 секунд браузерного виконання, що додаються на кожну сторінку при увімкненому рендерингу. render: false коштував $0 під час бета-версії. render: true коштував приблизно $0.03 за той самий обхід.
Скільки додаткового контенту захоплює Cloudflare /crawl render true порівняно з render false?
У нашому тесті на 256 сторінках render: true створив 12.5 МБ markdown проти 11.0 МБ від render: false, збільшення на 14%. Додатковий контент прийшов майже повністю від JavaScript-завантажених елементів на головній сторінці та індексних сторінках блогу. Окремі сторінки товарів та статті блогу були практично ідентичними між режимами. Для сайтів із переважно серверним рендерингом контенту render: false захоплює понад 90% корисного тексту без витрат та у 5 разів швидше.
Чи працює Cloudflare /crawl надійно на всіх магазинах Shopify?
Це залежить від магазину та режиму рендерингу. У наших тестах на п'яти магазинах Shopify: Store A (великий каталог) досяг 100% успіху з render: false. Store B (середній одяг) досяг 96% успіху з обома режимами. Store C (здоров'я та добавки) досяг 40% на вибірці з 5 сторінок та 89% на обході 100 сторінок з render: false, хоча наш початковий тест не мав надійного відновлення після помилок і деякі збої могли бути відновлювальними. Store D (малий магазин) повертав помилки 429 з render: false, але досяг 100% з render: true. Store E (великий мультикатегорійний, ~1 200 сторінок) досяг 100% успіху з render: false та 100% на вибірці з 100 сторінок з рендерингом та оптимізаціями блокування ресурсів. Ми не перетестовували Store C та Store D з покращеною обробкою помилок. Протестуйте обидва режими на вашому конкретному магазині перед вибором стратегії обходу.
Який фактичний час для обходу 500 сторінок Cloudflare /crawl з render false?
У нашому тесті обхід 500 сторінок з render: false завершився приблизно за 18 хвилин зі 100% успіхом. Обхід 256 сторінок на іншому магазині завершився приблизно за 5 хвилин. Обхід 100 сторінок завершився приблизно за 3.5 хвилини. Ці показники фактичного часу є оцінками на основі інтервалів опитування, а не точними вимірюваннями. Фактичний час складається переважно з внутрішніх накладних витрат черги та HTTP-завантаження Cloudflare, а не браузерного рендерингу, оскільки з render: false браузерні секунди не використовуються.
Скільки серверних запитів генерує Cloudflare /crawl render true?
В нашому аналізі серверних логів один обхід render: true з 25 сторінок згенерував 2 234 загальних запити: 2 071 GET та 163 POST. Це приблизно 89 серверних запитів на кожну фактично відрендерену сторінку. Лише 1.1% запитів були фактичним контентом сторінок. Решта 98.9% складали JavaScript-файли (75%), аналітичні маяки (6.3%), CSS (4.3%), трекінг-пікселі (3.4%) та попереднє завантаження checkout (3.3%). Якщо ви моніторите бот-трафік або керуєте серверним навантаженням, очікуйте, що обхід з рендерингом згенерує у 89 разів більше запитів, ніж фактичних запитів сторінок, у ваших серверних логах.
Який user-agent використовує Cloudflare /crawl та з якого діапазону IP?
Краулер ідентифікує себе як CloudflareBrowserRenderingCrawler/1.0 у 100% запитів. У наших логах усі запити надходили з 23 унікальних IP у діапазоні 104.28.x.x, розподілених між 5 дата-центрами Cloudflare у США: ATL (38%), ORD (25%), MIA (23%), EWR (9%) та IAD (5%). Ротація user-agent або маскування IP відсутні. Краулер є підписаним, ідентифікованим ботом за задумом.
Чи спотворює Cloudflare /crawl аналітику Shopify та кількість відвідувачів?
Ми вважаємо, що так, але не підтвердили це безпосередньо у звітності Shopify. Оскільки render: true виконує JavaScript, він активує повний стек аналітики Shopify на кожній сторінці: маяки monorail, трекінг-події /api/collect, попереднє завантаження Shop Pay checkout та скрипти web-pixel sandbox. У нашому тесті 163 із 2 234 запитів були POST-запитами до аналітичних ендпоінтів Shopify. Це ті самі події, що спрацьовують для реальних клієнтів. Якщо Shopify рахує їх як реальні сесії, ваші кількості сесій, перегляди сторінок та дані воронки конверсії будуть спотворені.
Як виявити Cloudflare /crawl у серверних логах порівняно з реальним браузерним трафіком?
Два надійні відбитки: браузерний рендерер Cloudflare пропускає заголовки sec-ch-ua Client Hints (реальний браузер Chrome завжди їх надсилає), і всі запити використовують HTTP/1.1 замість HTTP/2 або HTTP/3, які б узгодив реальний браузер. Він надсилає належні заголовки sec-fetch-dest, sec-fetch-mode та sec-fetch-site, що збігаються з реальним Chrome. User-agent завжди CloudflareBrowserRenderingCrawler/1.0, а всі IP потрапляють у діапазон 104.28.x.x.