
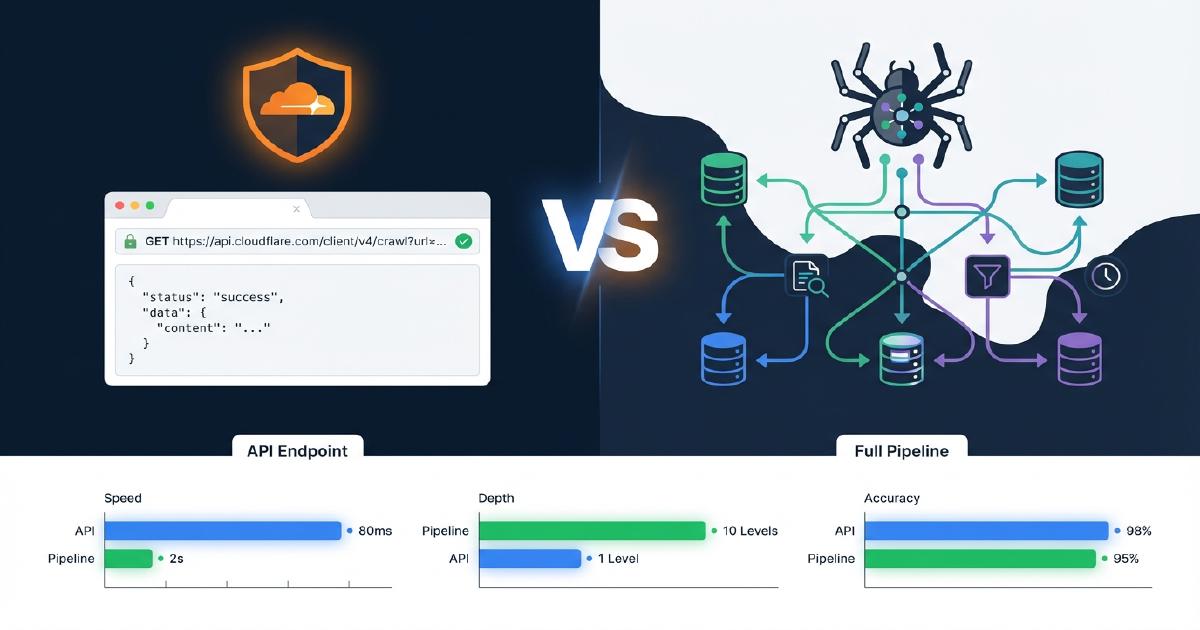
Cloudflare /crawl Endpoint’i Nedir?
Cloudflare’in /crawl endpoint’i, su anda acik betada olan Browser Rendering API’lerinin bir parcasidir. Bir baslangic URL’sinden icerik toplar, yapilandirilabilir bir derinlik veya sayfa sinirina kadar site genelinde baglantilari takip eder ve sonuclari HTML, Markdown veya Workers AI tarafindan desteklenen yapisal JSON olarak dondurur. Cloudflare, bunu modelleri egitmek, RAG boru hatlari olusturmak ve bir sitedeki icerigi arastirmak veya izlemek icin bir arac olarak konumlandirir.
Endpoint, varsayilan olarak robots.txt ve Cloudflare’in AI Crawl Control’unu destekleyen imzali bir ajan olarak calisir, bu da dikkate deger bir tasarim tercihi. Gelistiricilerin web sitesi kurallarina uymasini kolaylastirmak ve tarayicilarin site sahibi rehberligini gormezden gelmesini zorlastirmak icin tasarlanmistir.
Endpoint su adreste bulunur:
https://api.cloudflare.com/client/v4/accounts/<account_id>/browser-rendering/crawl
Kullanmak icin Browser Rendering Edit iznine sahip bir Cloudflare API anahtarina ihtiyaciniz vardir.
Nasil Calisiyor
Tarama, iki adimda asenkron bir is olarak calisir:
- Baslangic URL’si iceren bir POST istegi ile taramayi baslatma. API hemen bir is kimligini dondurur.
- Bu is kimligini kullanarak GET istekleriyle sonuclari sorgulama. Is durumu
running‘dencompleted‘a degistiginde, taranan verileriniz hazirdir.
Isler yedi gune kadar calisabilir. Sonuclar tamamlandiktan sonra 14 gun boyunca saklanir.
Ne Gonderiyorsunuz
Minimum olarak bir URL gonderirsiniz:
curl -X POST 'https://api.cloudflare.com/client/v4/accounts/{account_id}/browser-rendering/crawl' \
-H 'Authorization: Bearer <apiToken>' \
-H 'Content-Type: application/json' \
-d '{
"url": "https://example.com"
}'
Temel Parametreler
| Parametre | Varsayilan | Ne Yapar |
|---|---|---|
limit |
10 | Taranacak maksimum sayfa (100.000’e kadar) |
depth |
100,000 | Baslangic URL’sinden maksimum baglanti derinligi |
source |
all |
URL’lerin nereden kesfedilecegi: all, sitemaps veya links |
formats |
HTML | Yanit formati: html, markdown veya json |
render |
true | JavaScript’i calistir (true) veya hizli HTML getirme (false) |
maxAge |
86,400 | Saniye cinsinden onbellek TTL’si (maksimum 604.800) |
modifiedSince |
yok | Unix zaman damgasi: yalnizca bu zamandan sonra degistirilen sayfalari tara |
options.includePatterns |
yok | Yalnizca bu joker karakter kaliplariyla eslesen URL’leri tara |
options.excludePatterns |
yok | Bu kaliplarla eslesen URL’leri atla |
Ne Geri Aliyorsunuz
Taranan her sayfa, URL, durum, sectiginiz formatta icerik ve temel meta veriler (HTTP durum kodu, sayfa basligi, yonlendirmelerden sonraki son URL) iceren bir kayit olarak doner. render: true ile Open Graph etiketlerini de alirsiniz. Yanit ayrica faturalama gorunurlugu icin browserSecondsUsed ve 10 MB’yi asan sonuclari sayfalandirmak icin bir cursor icerir.
Canli bir Shopify magazasinin 24 sayflik render edilmis taramasindan gelen gercek is duzeyindeki yanit:
{
"job_id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890",
"status": "completed",
"total": 24,
"finished": 24,
"browserSecondsUsed": 58.38,
"record_count": 24,
"records": [
{
"url": "https://www.example-store.com/products/premium-widget-bundle",
"status": "completed",
"metadata": {
"status": 200,
"title": "Premium Widget Bundle | Example Store",
"url": "https://www.example-store.com/products/premium-widget-bundle",
"lastModified": "",
"og:type": "product",
"og:site_name": "Example Store",
"og:title": "Premium Widget Bundle | Example Store",
"og:image": "https://www.example-store.com/cdn/shop/files/product-image.jpg",
"og:description": "Our best-selling bundle with everything you need..."
},
"markdown": "Store\n\nexample-store\n\nURL\n\nhttps://www.example-store.com\n\nCurrency\n\nUSD\n\n# Premium Widget Bundle\n\nOur best-selling bundle with everything you need..."
}
]
}
render: true ile meta veri nesnesi, Open Graph alanlarinin tam setini icerir: tur, site adi, baslik, gorsel URL’si ve aciklama. Bunlar tarayici render sirasinda sayfanin OG meta etiketlerinden cekilir. render: false ile meta veri yalnizca HTTP durum kodunu, sayfa basligini ve son URL’yi icerir. Hicbir Open Graph alani cikarilmaz.
Markdown alani yalnizca ana icerigi degil, tum sayfa ciktisini icerir. Gezinme menuleri, mega menuler, alt bilgiler ve tekrarlanan sablon bloklarinin hepsi her kayitta yer alir. Testlerimizde, ortalama sayfa yaklasik 158 KB markdown dondurdu ve bunun yaklasik %90’i tekrarlanan sablondu. Bunu bir LLM veya RAG boru hattina besliyorsaniz, sablonu soyup gercek sayfa icerigini yalitmak icin kendi icerik cikarma mantiginiza ihtiyaciniz olacak.
Ayni magazanin render: false calistirdigimizda dondurukleri:
{
"job_id": "f9e8d7c6-b5a4-3210-fedc-ba9876543210",
"status": "completed",
"total": 266,
"finished": 266,
"browserSecondsUsed": 0,
"record_count": 256,
"records": [
{
"url": "https://www.example-store.com/products/classic-knit-sweater",
"status": "completed",
"metadata": {
"status": 200,
"title": "Classic Knit Sweater | Example Store",
"url": "https://www.example-store.com/products/classic-knit-sweater",
"lastModified": ""
},
"markdown": "Skip to content\n\nFree Shipping $150+\n\n# Classic Knit Sweater\n\nOur best-selling sweater made from premium natural fibers..."
}
]
}
Sifir tarayici saniyesi, 266 sayfanin 256 kaydi. Meta veri, render edilmis versiyona kiyasla minimumda: Open Graph alanlari yok, yalnizca HTTP durumu, sayfa basligi ve URL. Ancak markdown, gezinme, urun detaylari ve alt bilgi dahil tam sayfa icerigini iceriyor. Sunucu tarafindan render edilen Shopify magazalari icin, statik HTML zaten ihtiyaciniz olan her seye sahip.
URL Kesfi
Tarayici, URL’leri uc kaynaktan kesfeder (source, all olarak ayarlandiginda):
- Saglediginiz baslangic URL’si
- Alan adinda bulunan site haritasi baglantilari
- Taranan sayfalarda bulunan dahili baglantilar
Bunu source parametresini kullanarak yalnizca site haritalari veya yalnizca sayfa baglantilari ile sinirlandirabilirsiniz. excludePatterns her zaman includePatterns‘a gore oncelik tasir, boylece genis bir ag atabilir ve ardindan ihtiyaciniz olmayan bolumleri disari cikarabilirsiniz.
Render Etme vs. Hizli Getirme
render: true (varsayilan), basliksiz bir tarayici baslatir, JavaScript’i calistirir ve sayfanin tamamen yuklenmesini bekler. Bu, tek sayfa uygulamalari ve JavaScript ile render edilen icerik icin gereklidir, ancak faturalandirilan tarayici saniyelerini kullanir.
render: false, JavaScript calistirmadan hizli bir HTML getirme yapar. Beta doneminde bu getirmeler faturalandirilmaz. Bu, icerigin zaten ilk HTML’de oldugu statik siteler veya sunucu tarafindan render edilen sayfalar icin dogru secimdir.
Faturalandirma ve Kullanilabilirlik
Endpoint, hem Workers Free hem de Paid planlarinda kullanilabilir. Render edilen taramalar, dahil edilen tahsisinizin otesinde Cloudflare’in Browser Rendering fiyatlandirmasi kapsaminda tarayici saati basina 0,09 $ olarak faturalandirilir.
Workers Free: Gunluk 10 dakika tarayici suresi. /crawl endpoint’i gunde 5 is, tarama basina 100 sayfa ve dakikada 6 API istegi ile sinirlidir.
Workers Paid (aylik 5 $): Ayda 10 saat tarayici suresi dahil. Tarama basina sayfa siniri yok. Dakikada 600 API istegi. Ek tarayici saatleri her biri 0,09 $‘dir.
render: false taramalari sifir tarayici suresi kullanir. Beta doneminde ucretsizdir ancak sonunda standart Workers fiyatlandirmasi kapsamina girecektir.
Duvar Saati Suresi Nedir?
Duvar saati suresi, bir taramanin baslamasindan bitisine kadar gecen toplam suredir, bir kronometreyle olcersiniz gibi ayni sekilde olculur. Her seyi icerir: ag gecikmesi, Cloudflare’in dahili kuyruk suresi, DNS aramalari, sunucu yanit suresi ve (render etkinse) tarayici yurutme suresi.
Duvar saati suresi, tarayici suresinden farklidir. Tarayici suresi yalnizca Cloudflare’in basliksiz tarayicisinin sayfalar aktif olarak render ederken harcadigi saniyeleri sayar. Bir tarama 22 dakika tarayici suresi kullanabilir ancak kuyruk ve ag yuku nedeniyle 25 dakika duvar saati surebilir. Render edilmeyen taramalar sifir tarayici suresi kullanir ancak yine de getirme ve kuyruk surecindan duvar saati suresine sahiptir.
Karsilastirma sonuclarimizda, ne icin odediginizi (tarayici suresi) ve gercekte ne kadar beklediginizi (duvar saati suresi) gorebilmeniz icin her iki sayiyi da raporluyoruz.
Ince Detaylar
Endpoint, crawl-delay dahil robots.txt direktiflerini destekler. Kendisini CloudflareBrowserRenderingCrawler/1.0 olarak tanimlar. CAPTCHA’lari, Turnstile sorgulamalarini veya diger bot korumalarini atlamaz. Kendi sitenizi tariyorsaniz ve engelleniyorsaniz, tarayiciyi beyaz listeye almak icin bir WAF atlama kurali olusturmaniz gerekir.
Cloudflare /crawl Bes Shopify Magazasinda Nasil Davranir
/crawl endpoint’ini hiz, basari orani, maliyet ve tarayicinin her site ile nasil etkilestigini olcmek icin bes canli Shopify magazasina karsi calistirdik. Tum magaza adlari anonimlestirilmistir. Bunlar gercek taramalardan gelen gercek sayilardir. Duvar saati sureleri yaklasik tahminlerdir. Bazi erken testler sinirli hata islemeli betikler kullandi, bu da belirli magazalardaki raporlanan basari oranlarini etkilemis olabilir. Bunun gecerli oldugu yerlerde, asagida not ediyoruz.
Bu, ayarla ve unut turunden bir endpoint degildir. Her magaza, endpoint isteklerine farkli yanit verdi. Bazilari, render edilen bir taramayi tamamlamak icin kaynak engelleme gerektirdi. Digerleri bir modda 429 hatalari dondurdu ancak digerinde sorunsuz calisti. Tarama gecikmesi direktifleri, sayfa sayisi ve magaza mimarisi sonucu degistirdi. Taradiginiz her site icin ayarlari test etmeyi ve ayarlamayi planlayin.
Test 1: Buyuk E-Ticaret Katalogu (Store A)
/crawl endpoint’ini yaklasik 3.000 sayfali buyuk bir Shopify magazasina yonelttik. Icerik hizla geldi, markdown kullanisilirdi ve endpoint’in urun sayfalari, koleksiyon sayfalari ve blog icerigini getirmede hicbir sorunu olmadi. Proxy sorunlari yok, engellemeler yok, hiz sinirlamasi yok.
Farkli olceklerde birden fazla tarama gerceklestirdik:
| Tarama Boyutu | Donen Sayfalar | Mod | Tarayici Suresi | Duvar Saati |
|---|---|---|---|---|
| 20 sayfalik ornek | 20 / 20 (%100) | no-render | 0s | ~1 dk |
| 500 sayfalik tarama | 500 / 500 (%100) | no-render | 0s | ~18 dk |
| 5 sayfalik render | 4 / 5 (%80) | render: true | 0,9s | ~10s |
JavaScript render olmadan tarama, her iki olcekte de %100 basari elde etti. Tam tarayici render, kucuk bir ornek testte 5 sayfanin 4’unu dondurdu. Bu kadar kucuk bir ornekte, eksik tek sayfa bir tarayici zaman asimi, gecici bir hata veya betik tarafli bir sorun olabilir.
Test 2: Kucuk Shopify Magazasi (Store D, 24 sayfa)
Tam is akisini test ettigimiz daha kucuk bir magaza:
Render olmadan tarama hatalar dondurdu. Ilk testimiz, duz HTML getirmede 429 yanitlari dondurdu. Bu magazayi iyilestirilmis hata isleme ile yeniden test etmedik, bu nedenle 429’larin magazanin hiz sinirlamasindan mi yoksa test sirasindaki gecici sorunlardan mi kaynaklandigini dogrulayamiyoruz.
Site haritasi tabanli kesfle tam render, tam bir basariydi. 24 sayfanin 24’u tarandi, %100 tamamlama.
| Sayfa Turu | Sayi |
|---|---|
| Urunler | 9 |
| Koleksiyonlar | 4 |
| Sayfalar | 3 |
| Bloglar/Haberler | 5 |
| Diger (ana sayfa, blog dizini) | 3 |
Onemli bir kesif: varsayilan URL kesif modu, ana sayfanin neredeyse hic dahili baglantisi olmadigi icin yalnizca 1 sayfa buldu. Site haritasi tabanli kesfiye gecmek 24 sayfanin tamamini buldu. Ana sayfaniz minimal veya JavaScript agirliksaysa, tarayici yalnizca baglantilar araciligiyla sayfa bulamayabilir.
Test 3: Orta Olcekli Giyim Magazasi (Store B, 256 sayfa), Render Ile ve Render Olmadan
En detayli testimiz. 256 dizinlenebilir sayfali orta olcekli bir giyim magazasi: urunler, koleksiyonlar, blog yazilari ve bilgi sayfalari. Gercek farki olcmek icin her iki modu tam site uzerinde calistirdik.
| Metrik | render: false | render: true | Fark |
|---|---|---|---|
| Taranan sayfalar | 256 / 266 | 256 / 266 | Ayni |
| Toplam markdown ciktisi | 11,0 MB | 12,5 MB | +%14 |
| Tarayici suresi | 0s | 1.338s (22 dk) | +22 dk |
| Tahmini maliyet | 0 $ (beta) | ~0,03 $ | +0,03 $ |
| Duvar saati suresi | ~5 dk | ~25 dk | 5 kat daha yavas |
Test 4: Saglik ve Takviye Perakendecisi (Store C), Olcekte Kismi Basari
Devasa bir kataloga sahip buyuk bir saglik urunleri perakendecisi. Farkli olceklerde render olmadan iki tarama gerceklestirdik:
| Tarama Boyutu | Donen Sayfalar | Basari Orani | Duvar Saati |
|---|---|---|---|
| 5 sayfalik ornek | 2 / 5 | %40 | ~25s |
| 100 sayfalik tarama | 89 / 100 | %89 | ~3,5 dk |
Kismi basari orani, bu magazanin altyapisinin bazi tarayici olmayan istekleri dusurdugunü gosterebilir, ancak ilk testimiz saglam hata kurtarma eksikti, bu nedenle bu basarisizliklardan bazilari tarafimizda daha iyi yeniden deneme islemesiyle kurtarilabilir olabilirdi. Basari orani buyuk olcekte %40’tan %89’a yikseldi. Nedeni yalitmak icin bu magazayi iyilestirilmis hata isleme ile yeniden test etmedik.
Test 5: Buyuk Cok Kategorili Magaza (Store E, ~1.200 sayfa)
En buyuk ve en aydinlatici testimiz. Dort site haritasina dagilmis yaklasik 1.200 URL’ye sahip bir Shopify magazasi: 521 urun, 626 koleksiyon, 22 sayfa ve 31 blog yazisi.
| Metrik | render: false | render: true (optimize edilmis) |
|---|---|---|
| Taranan sayfalar | 1.200 / 1.200 | 100 / 100 |
| Toplam markdown ciktisi | 148,5 MB | 11,3 MB |
| Tarayici suresi | 0s | 475s (~8 dk) |
| Tahmini maliyet | 0 $ (beta) | ~0,012 $ |
| Duvar saati suresi | ~55 dk | ~12 dk |
Render olmayan tarama, sifir tarayici maliyetiyle tum 1.200 sayfada %100 basari elde etti. Render edilen tarama, kaynak engelleme optimizasyonlari etkinlestirilerek 100 sayfalk bir ornekte calistirildi.
Kaynak engelleme, takilan bir tarama ile temiz bir tarama arasindaki farki yaratti. Kaynaklari engellemeden, render edilen tarama 100 sayfanin 99’unda suresiz olarak takildi ve bu 99 sayfa icin 649 saniye tarayici suresi harcadi. Kaynak engellemeyi (gorseller, medya, fontlar, stil dosyalari) bir domcontentloaded bekleme kosuluyla etkinlestirmek, tarayici suresinde %27 azalma ile tum 100 sayfayi 475 saniyede tamamladi, takilma olmadi.
robots.txt’deki crawl-delay gorunur duraklamalara neden oldu. Store E’nin robots.txt’si belirli botlar icin 10 saniyelik bir crawl-delay belirtir. Render olmayan yoklama verilerimizde, bu sayfa sayisinin devam etmeden once duraldigi cok dakikalik platolar olarak goruldu. Cloudflare tarayicisi crawl-delay direktiflerini destekler, bu da bunlari ayarlayan sitelerde duvar saati suresini dogrudan uzatir.
/crawl Endpoint’i Gercekte Ne Kabul Eder
Endpoint, bir liste degil, tek bir baslangic URL’si alir. Bu URL’den disa dogru site haritalari, sayfa baglantilari veya her ikisi araciligiyla tarayarak sayfalari kesfeder. Zaten bir Scrapy taramasindan URL listeniz varsa ve markdown donusumu icin Cloudflare kullanmak istiyorsaniz, bunun yerine URL basina ayri ayri /markdown veya /scrape endpoint’lerini cagirmaniz gerekecektir.
Cloudflare /crawl Sunucu Tarafinda Gercekte Ne Yapar?
Store D’nin (25 sayfa) tam render edilmis taramasi sirasinda gercek trafik ayak izini analiz etmek icin tam sunucu loglarini cektik. Sonuclar, tarayici render edilmis tarama ile geleneksel bot tarama arasindaki temel farklari, analitik, sunucu yuku ve bot trafigi izleme icin istenmeyen yan etkileriyle ortaya koyuyor.
| Metrik | Deger |
|---|---|
| User-Agent | CloudflareBrowserRenderingCrawler/1.0 (isabetlerin %100’u) |
| Tarama penceresi | 134 saniye (~2 dakika) |
| Tepe verimi | 82 istek/saniye |
| Benzersiz IP’ler | 23, 5 Cloudflare veri merkezinde |
| GET istekleri | 2.071 |
| POST istekleri | 163 |
| Toplam istekler | 2.234 |
| Render edilen gercek sayfalar | ~25 |
| Sayfa basina istek | ~89 kat amplifikasyon |
Tam Render Edilmis Bir Cloudflare /crawl Gercekte Ne Kadar Trafik Olusturur?
En buyuk bulgu: 2.234 istegin yalnizca %1,1’i gercek sayfa icerigiydi. Geri kalan %98,9’u, gercek bir ziyaretcinin yapacagi gibi her sayfayi yukleyen tarayici tarafindan tetiklenen JavaScript, CSS, analitik isaretcileri, izleme pikselleri ve odeme on yuklemeleriydi.
Amazonbot veya ChatGPT-User gibi render etmeyen bir bot, sayfa basina 1 istek olusturur. Cloudflare tarayici render’i 89 istek olusturur.
Cloudflare /crawl Shopify Analitiklerini Sisiyor mu?
Loglarimizda 163 POST istegi tamamen tarama sirasinda ateslenen Shopify analitik ve izleme endpoint’leriydi. Bunlar, gercek bir musteri magazanizi ziyaret ettiginde ateslenen ayni olaylardir. Shopify Analytics’in perspektifinden, Cloudflare tarayicisi magazanizda her sayfayi 2 dakikada gezen bir ziyaretci gibi gorunur.
Cloudflare /crawl Sunucunuza Ne Kadar Hizli Isabet Eder?
Tum 2.234 istek 134 saniyelik bir pencerede indi. Tepe verimi saniyede 82 istege ulasti. Tarayici tum 25 sayflik siteyi 2 dakikanin biraz uzerinde render etti, ancak sunucu, organik gezinme kaliplarinin hicbirine benzemeyen surdurulen bir trafik patlamasi gordu.
Kucuk magazalar icin bu yonetilebilir. Binlerce sayfali daha buyuk magazalar icin, istek amplifikasyonu (sayfa basina 89 kat) surdurulen verimle birlestiginde, ozellikle paylasimli barindirma planindaysaniz veya agresif hiz sinirlamaniz varsa, kaynak sunucuda anlamli bir yuk olusturabilir.
Cloudflare /crawl Nereden Geliyor?
Tarama, ABD’deki 5 Cloudflare veri merkezine dagildi:
| Veri Merkezi | Istek Yuzdesi | Konum |
|---|---|---|
| ATL | %38 | Atlanta |
| ORD | %25 | Chicago |
| MIA | %23 | Miami |
| EWR | %9 | Newark |
| IAD | %5 | Washington DC |
Bu, istek yapan tek bir sunucu degildir. Cloudflare, render is yukunu edge agi uzerinde dagitir. Tum 23 IP 104.28.x.x araliginda kaldi ve user-agent, her bir istekte CloudflareBrowserRenderingCrawler/1.0 idi.
Cloudflare /crawl Hangi Tarayici Parmak Izini Birakir?
Render edici, gercek bir Chrome tarayicisini taklit eden uygun Sec-Fetch basliklarini gonderir:
| Baslik | Deger | Gercek Chrome? |
|---|---|---|
sec-fetch-dest |
script, document, vb. |
Evet, eslesiyor |
sec-fetch-mode |
cors, navigate |
Evet, eslesiyor |
sec-fetch-site |
same-origin, cross-site |
Evet, eslesiyor |
sec-ch-ua (Client Hints) |
Gonderilmiyor | Hayir, gercek Chrome bunu gonderir |
| HTTP surumu | HTTP/1.1 | Hayir, gercek Chrome HTTP/2 veya HTTP/3 muzakere eder |
Iki parmak izi bosugu one cikiyor: render edici sec-ch-ua Client Hints basliklarini tamamen atliyor (gercek bir Chrome tarayicisi bunlari her zaman gonderir) ve tum istekler HTTP/2 veya HTTP/3 yerine HTTP/1.1 kullaniyor. Bot tespit kurallari olusturuyorsaniz, bunlar Cloudflare’in tarayici render’ini gercek ziyaretci trafiginden ayirt etmek icin guvenilir sinyallerdir.
Cloudflare /crawl Sunucu Loglarinda Diger Yapay Zeka Botlariyla Nasil Karsilastiriliyor?
Cloudflare taramasini ayni 12 saatlik pencerede ayni magazaya gelen diger botlarla karsilastirdik:
Amazonbot ve ChatGPT-User ham HTML getirir: bir istek, bir sayfa, JavaScript yurutme yok. AhrefsBot, kesif icin site haritalarini tarar. Cloudflare tarayici render’i, gercek bir musteri geziyor gibi her sayfada tam bir Shopify vitrinini calistirarak her betigi, pikseli ve on yuklemeyi tetikler.
Cloudflare /crawl Hiz ve Maliyet: Tam Karsilastirma
Gerceklestirdigimiz her tarama, tek bir tabloda. Tum magazalar anonimlestirildi, tum sayilar gercek testlerden. Duvar saati sureleri yaklasiktir. Store C ve D icin basari oranlari, ilk test betiklerimizdeki sinirli hata islemeden etkilenmis olabilir.
| Magaza | Sayfalar | Mod | Basari Orani | Tarayici Suresi | Duvar Saati | Maliyet |
|---|---|---|---|---|---|---|
| A: Buyuk E-Ticaret | 500 / 500 | no-render | %100 | 0s | ~18 dk | 0 $ |
| B: Orta Olcekli Giyim | 256 / 266 | no-render | %96 | 0s | ~5 dk | 0 $ |
| C: Saglik ve Takviyeler | 89 / 100 | no-render | %89 | 0s | ~3,5 dk | 0 $ |
| D: Kucuk Shopify | 24 / 24 | render: true | %100 | 58s | ~2 dk | ~0,002 $ |
| E: Buyuk Cok Kategorili | 1.200 / 1.200 | no-render | %100 | 0s | ~55 dk | 0 $ |
Cloudflare /crawl Render Ile ve Render Olmadan Ne Kadar Hizli?
En net karsilastirma, her iki modu da ayni 256 sayfa uzerinde calistirdigimiz Store B’den geliyor:
On bir taramanin tamamindaki kalip tutarlidir: render olmadan tarama onemli olcude daha hizlidir. Render olmadan duvar saati suresi, cogunlukla Cloudflare’in dahili kuyruk ve getirme yukudur. Tam render, bu taban cizginin uzerine sayfa basina yaklasik 5 saniyelik tarayici suresi ekler.
Tam Render Edilmis Bir Cloudflare Taramasinin Sayfa Basina Maliyeti Ne Kadar?
Cloudflare’in Browser Rendering fiyatlandirmasi, basliksiz tarayicisinin sayfalarinizi aktif olarak render etmek icin harcadigi sure olan tarayici saatlerine dayanir. Render olmadan tarama, sifir tarayici saati kullanir ve beta doneminde ucretsizdir.
Workers Free Plani: Gunluk 10 dakika tarayici suresi. /crawl endpoint’i ayrica gunde 5 tarama isi ve tarama basina en fazla 100 sayfa ile sinirlidir.
Workers Paid Plani (aylik 5 $): Ayda 10 saat tarayici suresi dahil. Bunun otesinde, ek tarayici saati basina 0,09 $ odersiniz. /crawl endpoint’inde tarama basina sinir yoktur. Dakikada 600 API istegine kadar.
Test taramalarimizin 0,09 $/saat uzerinden gercek maliyetleri:
| Tarama | Kullanilan Tarayici Suresi | 0,09 $/saat Maliyet |
|---|---|---|
| Store D: 24 sayfa render edildi | 58 saniye | ~0,002 $ |
| Store B: 256 sayfa render edildi | 1.338 saniye (~22 dk) | ~0,03 $ |
| 3.000 sayflik katalog (tahmini) | ~4 saat | ~0,36 $ |
Sayfa basina yaklasik 5 saniyelik tarayici suresiyle, bu maliyetlerin hepsi ucretli plana dahil 10 saatin altinda kaliyor. 3.000 sayflik render edilmis bir tarama, dahil edilen 10 saatinizin yaklasik 4’unu kullanir, yani 5 $ taban ucretin otesinde herhangi bir sey odemeden once ayda iki tam tarama calistirabilirsiniz. Render olmadan tarama, her iki planda da ucretsizdir ve tarayici suresi maliyeti yoktur.
Cloudflare /crawl’da Render’i Ne Zaman Atlamali, Ne Zaman Tam Render Kullanmali?
Sonuc
Sunucu tarafindan render edilen icerge sahip cogu Shopify magazasi icin, render olmadan tarama, surenin bir kisminda sifir maliyetle yararli icerigin %90’indan fazlasini elde eder.
Cloudflare /crawl’i Shopify Magazalarinda Test Ederek Ogrendiklerimiz
5 canli Shopify magazasinda 11 tarama gerceklestirdikten ve tam sunucu loglarini analiz ettikten sonra, en onemli bulgular bunlardir.
Icerigin %90’i Render Olmadan Geliyor
Standart sunucu tarafindan render edilen sayfalara sahip Shopify magazalari icin, JavaScript render olmadan tarama, yararli icerigin %90’indan fazlasini yakaladi. Tam render’dan gelen %14’luk icerik artisi neredeyse tamamen ana sayfalar ve dizin sayfalarindaki JavaScript ile yuklenen ogelerden geldi. Bireysel urun sayfalari ve blog makaleleri her iki sekilde de neredeyse aynidir. Magazaniz tek sayfa uygulamasi olarak yapilmadikca, muhtemelen tam render’a ihtiyaciniz yoktur.
Tam Render 89 Katlik Bir Trafik Carpani Olusturuyor
25 sayfanin render edilmesi 2.234 sunucu istegi olusturdu. Bunlardan yalnizca 25’i gercek sayfa icerigiydi. Diger %98,9’u JavaScript dosyalari (%75), analitik isaretcileri (%6,3), CSS (%4,3), izleme pikselleri (%3,4) ve odeme on yuklemeleri (%3,3) idi. Render edilen her sayfa, gercek bir musteri geziyor gibi tam Shopify istemci tarafli yigini tetikler.
Shopify Analitikleriniz Muhtemelen Sisiriliyor
Render edilen taramalar, Shopify’in tam analitik yiginini atesler: monorail isaretcileri, izleme olaylari, Shop Pay on yuklemeleri ve web piksel betikleri. Shopify Analytics’in bunlari gercek ziyaretci oturumlari olarak saydgina inaniyoruz. Durum buyse, tek bir render edilmis tarama oturum sayilarinizi, sayfa goruntulemelerinizi ve donusum hunisi verilerinizi sisiribilir. Bunu dogrudan Shopify’in raporlamasinda dogrulamadik, ancak sunucu loglari, gercek bir musteri icin ateslenen ayni analitik olaylarinin ateslendigini gosteriyor.
Tam Render, Magaza Hiz Sinirlarini Atlayabilir
Store D, render olmadan her sayfada 429 hatalari dondurdu. Ayni magazada tam render’a gecmek %100 basari uretti. Render olmadan hiz sinirlariya karsilasirssaniz, tam render cozumunuzdur.
Site Haritasi Kesfi, Baglanti Kesfinden Daha Guvenilir
Varsayilan baglanti tabanli kesif, ana sayfanin cok az dahili baglantisi nedeniyle Store D’de neredeyse hicbir sey bulamadi. Site haritasi tabanli kesfiye gecmek 24 sayfanin tamamini buldu. Her zaman site haritasi kesfini kullanin.
Tarayici 5 ABD Veri Merkezinden Geliyor
Cloudflare, render is yukunu edge agi uzerinde dagitir. Taramarmiz Atlanta (%38), Chicago (%25), Miami (%23), Newark (%9) ve Washington DC (%5) genelinde 23 benzersiz IP’den geldi. Tum IP’ler 104.28.x.x araliginda kaliyor.
Iki Parmak Izi Bosugu Onu Bot Olarak Tanimliyor
Render edici sec-ch-ua Client Hints basliklarini atliyor (gercek Chrome bunlari her zaman gonderir) ve HTTP/2 veya HTTP/3 yerine HTTP/1.1 kullaniyor. Bot tespit kurallari olusturuyorsaniz, bunlar guvenilir sinyallerdir.
Render Etme Aslinda Daha Az Icerik Dondurebilir
Store E’de, render olmayan tarama, render edilen taramadan sayfa basina %6,8 daha fazla icerik dondurdu. Tarayici suresini optimize etmek icin gorselleri, fontlari ve stil dosyalarini engellemek, bazi JavaScript’in dinamik ogeleri doldurmasini da engelledi. Statik HTML zaten her seye sahipti. Sunucu tarafindan render edilen Shopify magazalari icin, render’in daha fazla icerik yakalayacagi garanti degildir.
Kaynak Engelleme Takilan Taramalari Onler
Kaynak engelleme olmadan, Store E’deki render edilen tarama 100 sayfanin 99’unda takildi ve hic tamamlanmadi. Gorseller, medya, fontlar ve stil dosyalari icin engellemeyi bir domcontentloaded bekleme kosuluyla etkinlestirmek, tum 100 sayfayi tamamladi ve tarayici suresini %27 azaltti. Render edilen taramalariniz bitmeden duruyorsa, kaynak engelleme cozumdur.
robots.txt Crawl-Delay Duvar Saati Suresini Uzatiyor
Store E’nin robots.txt’si 10 saniyelik bir crawl-delay belirtir. Render olmayan yoklama verilerimizde, bu sayfa sayisinin devam etmeden once duraldigi cok dakikalik platolar olarak goruldu. Cloudflare tarayicisi crawl-delay direktiflerini destekler, bu nedenle agresif gecikmelere sahip sitelerin duvar saati sureleri, sayfa sayisinin tek basina onerdiginden onemli olcude daha uzun olacaktir.
Maliyet Dusuk Ama Ucretsiz Planin Sinirlari Var
256 sayfanin render edilmesi, tarayici saati basina 0,09 $ uzerinden yaklasik 0,03 $‘a mal oldu. 24 sayfanin render edilmesi yaklasik 0,002 $‘a mal oldu. Workers Free plani, tarayici suresini gunde 10 dakikayla, en fazla 5 tarama isi ve tarama basina 100 sayfa ile sinirlar. Workers Paid plani (aylik 5 $), tarama basina sinir olmadan ayda 10 saat tarayici suresi icerir. 3.000 sayflik render edilmis bir tarama, bu dahil edilen 10 saatin yaklasik 4’unu kullanir, bu nedenle cogu magaza fazlallik olmadan ucretli plana rahatca sigar. Render olmadan tarama, beta doneminde her iki planda da sifir tarayici suresi kullanir ve ucretsizdir.
Artilar
Hiz
Sayfalar, otomatik yavaslatma ile cok saatlik bir Scrapy taramasina kiyasla neredeyse aninda getirilir. Kuyruk yok, kibarlk gecikmeleri yok, spider’inizin binlerce istegi saygli bir hizda islemesini bekleme yok.
Markdown Ciktisi
Endpoint, her sayfa icin onceden donusturulmus HTML-Markdown dondurur. Bu, herhangi bir son isleme olmadan LLM beslemesi, RAG boru hatlari ve icerik analizi icin dogrudan kullanislidir. Tum cikarma katmanini atlayip dogrudan temiz metne gidersiniz. Web sitesi icerigi uzerine yapay zeka uygulamalari olusturan ekipler icin, bu boru hattindan bir adimi kaldirir.
Render Modu Secenegi
render: true ayarlamak JavaScript’i calistirir ve otomatik olarak Open Graph meta verilerini cikarir (og:title, og:description, og:image, og:site_name). Icerigin istemci tarafinda render edildigi JavaScript agirlikli siteler icin, bu gercek sayfayi gormek ile bos bir kabuk gormek arasindaki farktir.
Proxy veya Hiz Siniri Sorunu Yok
Cloudflare, anti-bot onlemlerini ve hiz sinirlamasini kendi altyapisinda yonetir. Proxy havuzlarini yonetmenize, user-agent’lari dondurmenize veya CAPTCHA’larla ugrasmaniza gerek yoktur. Tek bir API cagrisi.
Artimli Tarama
modifiedSince ve maxAge parametreleri, degismemis veya yakin zamanda getirilmis sayfalari atlamaniza olanak tanir. Icerik degisikliklerini izlediginiz tekrarlayan taramalar icin, bu yalnizca gercekten yeni veya guncellenenmis sayfalari isleyerek hem zaman hem de maliyet tasarrufu saglar.
Basitlik
Tek API cagrisi. JSON yaniti. Spider kodu yok, ara yazilim yok, oge boru hatlari yok, ayar dosyalari yok.
Varsayilan Olarak Kuralli Bot
Tarayici, robots.txt, crawl-delay ve Cloudflare’in AI Crawl Control’unu destekleyen imzali bir ajandır. Kendisini CloudflareBrowserRenderingCrawler/1.0 olarak tanimlar ve bot korumasini veya CAPTCHA’lari atlayamaz. Mantigi kendiniz olusturmadan etik tarama uyumlulugunuzu elde edersiniz.
Cloudflare Crawl Endpoint’inin Desteklemedikleri
Cloudflare /crawl Tam Bir Tarama Boru Hattindan Nasil Farklidir?
Asagidaki tablo, Cloudflare’in /crawl endpoint’inde ve bir uretim Scrapy boru hattinda tam olarak hangi yeteneklerin bulundugunu gosteriyor. Bu, Shopify magazalarina karsi yapilan gercek testlerimize dayanmaktadir.
| Yetenek | Cloudflare /crawl | Scrapy Boru Hatti |
|---|---|---|
| Icerik getirme (HTML/Markdown) | Evet | Evet |
| JavaScript render | Evet (render: true) |
Evet (Splash/Playwright) |
| Baglanti kesfi / tarama | Evet (duz liste) | Evet (tam tarama grafigi) |
| Ust-alt baglanti haritalamasi | Hayir | Evet |
| Yetim sayfa tespiti | Hayir | Evet |
| Yonlendirme zinciri takibi | Hayir | Evet |
| JSON-LD cikarimi | Hayir | Evet |
| Microdata cikarimi | Hayir | Evet |
| Sema dogrulamasi + sorun raporlamasi | Hayir | Evet |
| 200 olmayan durum kodlari (404’ler, 403’ler) | Hayir | Evet (testimizde 2.547 adet 404 yakalandi) |
| URL siniri | 100.000 | Yok |
Cloudflare /crawl Hangi Yapisal Verileri Cikarir?
render: false ile hicbiri. JSON-LD yok, Microdata yok, OpenGraph ayristirmasi yok.
render: true ile yalnizca temel OG etiketleri (og:title, og:description, og:image, og:site_name). JSON-LD ve schema.org isaretlemesi ayristirilmaz, cikarilmaz veya dogrulanmaz.
Karsilastirma icin, Scrapy boru hattimiz her URL icin schemas_found, issues (eksik contactPoint, address vb.), top_level_schemas ve nested_schemas uretir. Hangi sayfalarin Product semasina sahip oldugunu, hangilerinin Organization isaretlemesinin eksik oldugunu ve hangi dogrulama hatalarinin yapay zeka sistemlerinin icerigi yanlis okumasina neden olacagini gorebilirsiniz.
Cloudflare /crawl Hangi HTTP Durum Kodlarini Dondurur?
Yalnizca 200 yanitlari. Ayni sitenin Scrapy taramasi 2.547 adet 404 hatasi, arti 403 yanitlari ve baglanti hatalari yakaladi. 404 tespiti, hayalet sayfa analizi, kirik baglanti duzeltmesi ve yonlendirme haritalamasi icin kritik oneme sahiptir. Bu olmadan, aktif olarak baglanti degerini sizdiran ve yapay zeka tarayicilarini karistan sayfalari kacirisyorsunuz.
Cloudflare /crawl Kac URL Isleyebilir?
Is basina 100.000’e kadar. Bu, cogu siteyi kapsar, ancak yuz binlerce urun sayfasi, varyant URL’si ve filtreli koleksiyon sayfasi olan buyuk e-ticaret kataloglari siniri asacaktir. Scrapy’nin dogal bir URL siniri yoktur.
Cloudflare /crawl’da URL Cozumleme Hatasi Var mi?
Tek bir urun sayfasindaki 908 baglantinan 233’unun bozuk yollara sahip oldugunu bulduk. Markdown donusturucu, goreceli URL’leri sayfa URL’sine karsi yanlis cozumleyerek /products/slug//www.example.com/... gibi cift yollu URL’ler uretiyor. Bu, herhangi bir alt baglanti analizini etkileyen, Cloudflare’in donusturucusundeki dogrulanmis bir hatadir.
Cloudflare /crawl Markdown Ciktisinda Ne Kadar Sablon Var?
Ortalama sayfa 158 KB markdown dondurdu. Yaklasik %90’i tekrarlanan sablon icerigi: tam gezinme, mega menu ve her kayitta alt bilgi. Icerik analizi icin bu, agir tekilsizlestirme calismasi anlamina gelir ve LLM jeton kullanimi icin maliyet hizla birikir. Gercek sayfa icerigini yalitmak icin markdown’un uzerine kendi icerik cikarma mantiginize ihtiyaciniz var.
Cloudflare /crawl Neyi Siniflandirmiyor?
Icerik turu etiketlemesi yoktur. Urun sayfalari, koleksiyon sayfalari, blog yazilari ve ana sayfalar farklilasmamis kayitlar olarak doner. Scrapy, sayfa kategorisine gore tarama kapsamini anlamak ve yapay zeka botlarinin hangi icerik turlerine oncelik verdigini belirlemek icin gerekli olan her URL’yi ture gore siniflandirir.
Cloudflare /crawl’da Hangi Sonuclandirma Ozellikleri Eksik?
Hayalet sayfa ekran goruntusu yok. JavaScript render karsilastirmasi (botun gordugu ile tarayicinin gordugu) yok. robots.txt yapay zeka bot analizi yok. Tarama kalite raporu yok. Istemci manifesti yok. CDN senkronizasyonu yok. Cloudflare verisi yalnizca ham icerik. Raporlama ve analiz boru hattinin her parcasinin ayri olarak olusturulmasi gerekecektir.
Cloudflare /crawl Buyuk Siteler Icin Ne Kadara Mal Olur?
Testlerimiz genelinde, render: true sayfa basina ortalama yaklasik 5 saniyelik tarayici yurutme suresi kullandi. 256 sayflik bir tarama, 1.338 tarayici saniyesi (22 dakika) kullandi ve tarayici saati basina 0,09 $ uzerinden yaklasik 0,03 $‘a mal oldu. 24 sayflik bir tarama, 58 tarayici saniyesi kullandi ve yaklasik 0,002 $‘a mal oldu. 3.000 sayflik bir katalogu tahmin etmek: yaklasik 4 saat tarayici suresi. Workers Free plani, gunde 10 dakika tarayici suresi, gunde 5 tarama isi ve tarama basina 100 sayfa ile sinirlidir. Workers Paid plani (aylik 5 $), tarama basina sinir olmadan ayda 10 saat tarayici suresi icerir, bu nedenle 3.000 sayflik bir tarama, bu dahil edilen 10 saatin yaklasik 4’unu kullanir. render: false, sifir tarayici suresi kullanir ve beta doneminde her iki planda da ucretsizdir.
Sonuc
Cloudflare’in crawl endpoint’i sunlar icin harika:
- Hizli icerik anlık goruntumleri, sayfa metnine hizla ihtiyac duydugunuzda
- LLM’ye hazir markdown, RAG boru hatlari ve icerik beslemesi icin
- Anlık sayfa kontrolleri, ihtiyaciniz olan kesin URL’leri bildiginizde
- Hizli site geneli icerik cekmeleri, spider olusturmadan markdown metnine ihtiyac duydugunuzda
Tam bir tarama boru hattinin yerini alamaz, cunku boru hattinin degeri sunlardadir:
- Tam tarama grafigi, baglanti topolojisi, yetim tespiti ve 404 kapsamiyla
- Yapisal veri cikarimi ve dogrulamasi (JSON-LD, Microdata, OpenGraph)
- Icerik siniflandirmasi, sayfa turune gore
- Hayalet sayfa analizi, JavaScript render karsilastirmasi, sema raporlari ve LLM hazirligi puanlamasi dahil tam sonuclandirma boru hatti
En Iyi Hibrit Yaklasim
Cloudflare’i tamamlayici bir veri kaynagi olarak kullanin. Tam bir tarama URL’lerinizi tespit ettikten sonra, yapisal meta veriler yerine gercek sayfa metnine ihtiyac duydugunuz LLM hazirligi puanlamasi veya icerik kalitesi analizi icin Cloudflare’in markdown ciktisini kullanin. Tarama boru hatti kesfeder ve siniflandirir. Cloudflare endpoint’i onemli sayfalar icin temiz metin sunar.
Tam tarama boru hattini calisirken gormek ister misiniz?
Gorusme PlanlayinSikca Sorulan Sorular
Cloudflare /crawl tarafindan desteklenmeyen web sitesi denetim ozellikleri hangileridir?
Cloudflare /crawl su ozellikleri desteklemiyor: tam tarama grafigi olusturma, ust-alt baglanti haritalamasi, yetim sayfa tespiti, yonlendirme zinciri takibi, JSON-LD veya Microdata cikarimi, sema dogrulamasi, 200 olmayan durum kodu yakalama (404'ler, 403'ler), icerik turu siniflandirmasi, sayfa bayt boyutu olcumu, hayalet sayfa tespiti, JS ile HTML render karsilastirmasi, robots.txt yapay zeka bot analizi veya geri baglanti capraz referanslamasi. Bu bir icerik toplayicidir, site denetim araci degildir.
Cloudflare /crawl, e-ticaret taramasi icin Scrapy'den nasil farklidir?
Cloudflare /crawl, yonetilecek altyapi olmadan icerigi hizla toplar. Scrapy, baglanti topolojisi ile tam bir tarama grafigi olusturur, yapisal verileri cikarir ve dogrular (JSON-LD, Microdata, OpenGraph), 404'ler dahil tum HTTP durum kodlarini yakalar, sayfalari icerik turune gore siniflandirir ve hayalet sayfa analizi, sema raporlari ve LLM hazirligi puanlamasi icin bir alt boru hattini besler. Cloudflare size sayfa metnini verir; Scrapy size tam site mimarisini verir.
Cloudflare /crawl icin kesin URL siniri nedir?
Tarama basi 100.000 URL. Varsayilan limit 10'dur, bu nedenle bunu acikca ayarlamaniz gerekir. Maksimum depth de 100.000'dir. 100K sayfayi asan siteler icin, dogal bir URL siniri olmayan Scrapy veya baska bir tarayici gereklidir.
Cloudflare /crawl, JSON-LD cikarir mi veya sema isaretlemesini dogrular mi?
Hayir. render: false ile sifir yapisal veri cikarilir. render: true ile yalnizca temel Open Graph etiketleri dondurulur (og:title, og:description, og:image, og:site_name). JSON-LD, Microdata ve schema.org isaretlemesi her iki modda da ayristirilmaz, cikarilmaz veya dogrulanmaz.
Cloudflare /crawl'in buyuk siteleri render etme maliyeti ne kadardir?
Testlerimiz genelinde, render: true sayfa basina ortalama yaklasik 5 saniyelik tarayici suresi kullandi. 256 sayflik bir site, 1.338 tarayici saniyesi (22 dakika) kullandi ve tarayici saati basina 0,09 $ uzerinden yaklasik 0,03 $'a mal oldu. 24 sayflik bir site, 58 saniye kullandi ve yaklasik 0,002 $'a mal oldu. 3.000 sayflik bir katalogu tahmin etmek: yaklasik 4 saat tarayici suresi. Workers Free plani gunde 10 dakika, gunde 5 tarama isi ve tarama basina 100 sayfa ile sinirlidir, bu nedenle buyuk render edilmis taramalar Workers Paid planini (aylik 5 $) gerektirir; bu plan tarama basina sinir olmadan ayda 10 saat tarayici suresi icerir. render: false, sifir tarayici suresi kullanir ve beta doneminde her iki planda da ucretsizdir.
Cloudflare /crawl'da bilinen bir URL cozumleme hatasi var mi?
Evet. Testimizde, tek bir urun sayfasindaki 908 baglantinan 233'u bozuk yollara sahipti. Markdown donusturucu, //www.example.com/cdn/... gibi goreceli yollarin basina sayfa URL'sini ekleyerek bozuk cift yollu URL'ler olusturuyor. Bu, markdown ciktisindan olusturulan tum alt baglanti grafigi analizini veya dahili baglanti denetimini etkiler.
Cloudflare /crawl, render false ile neden bazi Shopify magazalarinda 429 hatalari donduruyor?
render: false, basliksiz bir tarayici olmadan ham bir HTML getirme yapar. Testlerimizden birinde, render: false 429 hatalari dondururken, render: true ayni magazada %100 basariyla calisti. Iyilestirilmis hata isleme ile yeniden test etmedik, bu nedenle 429'lar magazanin hiz sinirlamasi, gecici API sorunlari veya bir kombinasyondan kaynaklanmis olabilir. Render olmadan 429 hatalari goruyorsaniz, ilk adim olarak render: true deneyin.
Cloudflare /crawl bir URL listesi kabul eder mi?
Hayir. Endpoint, tek bir baslangic URL'si alir ve site haritalari, sayfa baglantilari veya her ikisi araciligiyla disa dogru tarayarak sayfalari kesfeder. Zaten bir URL listeniz varsa ve Cloudflare'in markdown donusumunu istiyorsaniz, istek basina tek tek URL kabul eden ayri /markdown veya /scrape endpoint'lerini kullanin.
Cloudflare /crawl, source all ile neden bazi sitelerde yalnizca bir sayfa buluyor?
Varsayilan source: all, hem site haritalarindan hem de sayfa baglantilarindan URL kesfeder. Baslangic URL'sinde cok az dahili baglanti varsa (minimal ana sayfalarda veya JavaScript agirlikli SPA'larda yaygindir), tarayici yalnizca baglanti kesfederek ek sayfalar bulamayabilir. Tarayicinin tam sitemap.xml'i okumasi ve listelenen tum URL'leri kesfetmesi icin source: sitemaps secenegine gecin.
Cloudflare /crawl'i tam bir tarama boru hatti ile kullanmanin en iyi yolu nedir?
Once URL'leri kesfetmek, baglanti grafigini olusturmak, yapisal verileri cikarmak, 404'leri yakalamak ve icerigi siniflandirmak icin tam tarama boru hattini (Scrapy veya esdegeri) kullanin. Ardindan yapisal meta veriler yerine gercek sayfa metnine ihtiyac duydugunuz LLM hazirligi puanlamasi, icerik kalitesi analizi veya RAG beslemesi icin temiz markdown cekmek uzere Cloudflare'in /markdown veya /scrape endpoint'lerini kullanin.
Cloudflare /crawl render false, render true'ya kiyasla ne kadar hizlidir?
Ayni 256 sayflik sitede yaptigimiz karsilastirma testinde, render: false yaklasik 5 dakikada tamamlandi. render: true ayni sayfalar icin yaklasik 25 dakika surdu. Bu 5 katlik bir hiz farkidir. Duvar saati farki, render etkinlestirildiginde sayfa basina eklenen yaklasik 5 saniyelik tarayici yurutme suresinden kaynaklanir. render: false, beta doneminde 0 $'a mal oldu. render: true, ayni tarama icin yaklasik 0,03 $'a mal oldu.
Cloudflare /crawl render true, render false'a kiyasla ne kadar fazla icerik yakalar?
256 sayflik testimizde, render: true, render: false'tan gelen 11,0 MB'ye karsi 12,5 MB markdown uretti, %14'luk bir artis. Ekstra icerik neredeyse tamamen ana sayfa ve blog dizin sayfalarindaki JavaScript ile yuklenen ogelerden geldi. Bireysel urun sayfalari ve blog makaleleri modlar arasinda neredeyse aynidir. Cogunlukla sunucu tarafindan render edilen icerge sahip siteler icin, render: false sifir maliyetle ve 5 kat daha hizli bir sekilde yararli metnin %90'indan fazlasini yakalar.
Cloudflare /crawl tum Shopify magazalarinda guvenilir bir sekilde calisiyor mu?
Magazaya ve render moduna baglidir. Bes Shopify magazasindaki testlerimizde: Store A (buyuk katalog) render: false ile %100 basari elde etti. Store B (orta olcekli giyim) her iki modda da %96 basari elde etti. Store C (saglik ve takviyeler) render: false ile 5 sayflik ornekte %40 ve 100 sayflik taramada %89 basari elde etti, ancak ilk testimiz saglam hata kurtarma eksikti ve bazi basarisizliklar kurtarilabilir olabilirdi. Store D (kucuk magaza) render: false ile 429 hatalari dondurdu ancak render: true ile %100 basari elde etti. Store E (buyuk cok kategorili, ~1.200 sayfa) render: false ile %100 basari ve kaynak engelleme optimizasyonlariyla 100 sayflik render edilmis ornekte %100 basari elde etti. Store C ve D'yi iyilestirilmis hata isleme ile yeniden test etmedik. Bir tarama stratejisine beli baglamadan once her iki modu da kendi magazanizda test edin.
500 sayflik bir Cloudflare /crawl render false icin duvar saati suresi ne kadardir?
Testimizde, 500 sayflik bir render: false taramasi yaklasik 18 dakikada %100 basari orani ile tamamlandi. Farkli bir magazadaki 256 sayflik tarama yaklasik 5 dakikada tamamlandi. 100 sayflik bir tarama yaklasik 3,5 dakikada tamamlandi. Bu duvar saati sureleri, kesin olcumler degil, yoklama araliklarına dayanan tahminlerdir. Duvar saati suresi, render: false ile sifir tarayici saniyesi kullanildigi icin, tarayici render degil, oncelikle Cloudflare'in dahili kuyruk ve HTTP getirme yukudur.
Bir Cloudflare /crawl render true kac sunucu istegi olusturur?
Sunucu log analizimizde, 25 sayflik tek bir render: true taramasi toplam 2.234 istek olusturdu: 2.071 GET ve 163 POST. Bu, gercekte render edilen sayfa basina yaklasik 89 sunucu istegidir. Isteklerin yalnizca %1,1'i gercek sayfa icerigiydi. Geri kalan %98,9'u JavaScript dosyalari (%75), analitik isaretcileri (%6,3), CSS (%4,3), izleme pikselleri (%3,4) ve odeme on yuklemeleri (%3,3) idi. Bot trafigini izliyorsaniz veya sunucu yukunu yonetiyorsaniz, render edilmis bir taramanin sunucu loglarinizda gercek sayfa isteklerinin 89 katini olusturmasini bekleyin.
Cloudflare /crawl hangi kullanici aracisini kullaniyor ve hangi IP araliginda geliyor?
Tarayici, isteklerin %100'unde kendisini CloudflareBrowserRenderingCrawler/1.0 olarak tanimlar. Loglarimizda, tum istekler 5 ABD Cloudflare veri merkezine dagilmis 104.28.x.x araliginda 23 benzersiz IP'den geldi: ATL (%38), ORD (%25), MIA (%23), EWR (%9) ve IAD (%5). Kullanici aracisi rotasyonu veya IP gizlemesi yoktur. Tarayici, tasarim geregi imzali ve tanimlanabilir bir bottur.
Cloudflare /crawl, Shopify analitiklerini ve ziyaretci sayilarini sisiyor mu?
Biz oyle olduguna inaniyoruz, ancak bunu dogrudan Shopify'in raporlamasinda dogrulamadik. render: true JavaScript'i calistirdigi icin, her sayfada Shopify'in tam analitik yiginini atesler: monorail isaretcileri, /api/collect izleme olaylari, Shop Pay odeme on yuklemeleri ve web piksel sandbox betikleri. Testimizde, 2.234 istegin 163'u Shopify analitik endpoint'lerine yapilan POST istekleriydi. Bunlar, gercek musteriler icin ateslenen ayni olaylardir. Shopify bunlari gercek oturumlar olarak sayarsa, oturum sayilariniz, sayfa goruntulemeleriniz ve donusum hunisi verileriniz sisecektir.
Sunucu loglarinda Cloudflare /crawl'i gercek tarayici trafiginden nasil ayirt edebilirsiniz?
Iki guvenilir parmak izi bosugu: Cloudflare'in tarayici render'i sec-ch-ua Client Hints basliklarini atlar (gercek bir Chrome tarayicisi bunlari her zaman gonderir) ve tum istekler gercek bir tarayicinin muzakere edecegi HTTP/2 veya HTTP/3 yerine HTTP/1.1 kullanir. Gercek Chrome ile eslesen uygun sec-fetch-dest, sec-fetch-mode ve sec-fetch-site basliklarini gonderir. Kullanici aracisi her zaman CloudflareBrowserRenderingCrawler/1.0'dir ve tum IP'ler 104.28.x.x araligindadir.