
Czym jest endpoint Cloudflare /crawl?
Endpoint /crawl Cloudflare jest częścią ich Browser Rendering API, obecnie w otwartej becie. Pobiera treści ze startowego URL-a, podąża za linkami w obrębie witryny do konfigurowalnej głębokości lub limitu stron i zwraca wyniki jako HTML, Markdown lub strukturalny JSON zasilany przez Workers AI. Cloudflare pozycjonuje go jako narzędzie do trenowania modeli, budowania pipeline’ów RAG i badania lub monitorowania treści w obrębie witryny.
Endpoint działa jako podpisany agent, który domyślnie respektuje robots.txt i Cloudflare AI Crawl Control, co jest godną uwagi decyzją projektową. Ma ułatwić deweloperom przestrzeganie zasad witryn i utrudnić crawlerom ignorowanie wytycznych właścicieli stron.
Endpoint znajduje się pod adresem:
https://api.cloudflare.com/client/v4/accounts/<account_id>/browser-rendering/crawl
Do użycia potrzebujesz tokena API Cloudflare z uprawnieniem Browser Rendering Edit.
Jak to działa
Indeksowanie uruchamia się jako asynchroniczne zadanie w dwóch krokach:
- Uruchom indeksowanie żądaniem POST zawierającym startowy URL. API natychmiast zwraca identyfikator zadania.
- Odpytuj o wyniki żądaniami GET używając tego identyfikatora zadania. Gdy status zadania zmieni się z
runningnacompleted, zaindeksowane dane są gotowe.
Zadania mogą działać do siedmiu dni. Wyniki są przechowywane przez 14 dni po zakończeniu.
Co wysyłasz
Minimalnie wysyłasz URL:
curl -X POST 'https://api.cloudflare.com/client/v4/accounts/{account_id}/browser-rendering/crawl' \
-H 'Authorization: Bearer <apiToken>' \
-H 'Content-Type: application/json' \
-d '{
"url": "https://example.com"
}'
Kluczowe parametry
| Parametr | Domyślnie | Co robi |
|---|---|---|
limit |
10 | Maks. stron do zaindeksowania (do 100 000) |
depth |
100 000 | Maks. głębokość linków od startowego URL-a |
source |
all |
Skąd odkrywać URL-e: all, sitemaps lub links |
formats |
HTML | Format odpowiedzi: html, markdown lub json |
render |
true | Wykonaj JavaScript (true) lub szybkie pobieranie HTML (false) |
maxAge |
86 400 | TTL pamięci podręcznej w sekundach (maks. 604 800) |
modifiedSince |
brak | Znacznik czasu Unix: indeksuj tylko strony zmodyfikowane po tym czasie |
options.includePatterns |
brak | Indeksuj tylko URL-e pasujące do tych wzorców wieloznacznych |
options.excludePatterns |
brak | Pomiń URL-e pasujące do tych wzorców |
Co dostajesz w odpowiedzi
Każda zaindeksowana strona zwracana jest jako rekord z URL-em, statusem, treścią w wybranym formacie i podstawowymi metadanymi (kod statusu HTTP, tytuł strony, końcowy URL po przekierowaniach). Z render: true dostajesz również tagi Open Graph. Odpowiedź zawiera też browserSecondsUsed dla widoczności rozliczeń oraz cursor do paginacji wyników przekraczających 10 MB.
Oto faktyczna odpowiedź na poziomie zadania z renderowanego indeksowania 24 stron działającego sklepu Shopify:
{
"job_id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890",
"status": "completed",
"total": 24,
"finished": 24,
"browserSecondsUsed": 58.38,
"record_count": 24,
"records": [
{
"url": "https://www.example-store.com/products/premium-widget-bundle",
"status": "completed",
"metadata": {
"status": 200,
"title": "Premium Widget Bundle | Example Store",
"url": "https://www.example-store.com/products/premium-widget-bundle",
"lastModified": "",
"og:type": "product",
"og:site_name": "Example Store",
"og:title": "Premium Widget Bundle | Example Store",
"og:image": "https://www.example-store.com/cdn/shop/files/product-image.jpg",
"og:description": "Our best-selling bundle with everything you need..."
},
"markdown": "Store\n\nexample-store\n\nURL\n\nhttps://www.example-store.com\n\nCurrency\n\nUSD\n\n# Premium Widget Bundle\n\nOur best-selling bundle with everything you need..."
}
]
}
Z render: true obiekt metadata zawiera pełny zestaw pól Open Graph: type, site name, title, image URL i description. Są one pobierane z meta tagów OG strony podczas renderowania przeglądarki. Z render: false metadata zawiera tylko kod statusu HTTP, tytuł strony i końcowy URL. Żadne pola Open Graph nie są wyodrębniane.
Pole markdown zawiera całe wyjście strony, a nie tylko główną treść. Menu nawigacyjne, mega menu, stopki i powtarzające się bloki szablonów są uwzględnione w każdym rekordzie. W naszych testach średnia strona zwracała około 158 KB markdown, z czego około 90% stanowił powtarzający się szablon. Jeśli zasilasz tym LLM lub pipeline RAG, będziesz potrzebować własnej logiki ekstrakcji treści, aby usunąć szablon i wyizolować faktyczną treść strony.
Oto, co ten sam sklep zwrócił, gdy uruchomiliśmy render: false:
{
"job_id": "f9e8d7c6-b5a4-3210-fedc-ba9876543210",
"status": "completed",
"total": 266,
"finished": 266,
"browserSecondsUsed": 0,
"record_count": 256,
"records": [
{
"url": "https://www.example-store.com/products/classic-knit-sweater",
"status": "completed",
"metadata": {
"status": 200,
"title": "Classic Knit Sweater | Example Store",
"url": "https://www.example-store.com/products/classic-knit-sweater",
"lastModified": ""
},
"markdown": "Skip to content\n\nFree Shipping $150+\n\n# Classic Knit Sweater\n\nOur best-selling sweater made from premium natural fibers..."
}
]
}
Zero sekund przeglądarki, 256 rekordów z 266 stron. Metadata jest minimalna w porównaniu z wersją renderowaną: brak pól Open Graph, tylko status HTTP, tytuł strony i URL. Ale markdown nadal zawiera pełną treść strony, w tym nawigację, szczegóły produktu i stopkę. Dla serwerowo renderowanych sklepów Shopify statyczny HTML ma już wszystko, czego potrzebujesz.
Odkrywanie URL-i
Crawler odkrywa URL-e z trzech źródeł (gdy source jest ustawione na all):
- Startowy URL, który podajesz
- Linki z mapy witryny znalezione w domenie
- Linki wewnętrzne znalezione na zaindeksowanych stronach
Możesz ograniczyć to tylko do map witryn lub tylko do linków na stronach za pomocą parametru source. excludePatterns zawsze ma priorytet nad includePatterns, więc możesz rzucić szeroką sieć, a potem wyciąć sekcje, których nie potrzebujesz.
Renderowanie vs. szybkie pobieranie
render: true (domyślnie) uruchamia przeglądarkę headless, wykonuje JavaScript i czeka na pełne załadowanie strony. Jest to konieczne dla aplikacji jednostronicowych i treści renderowanych przez JavaScript, ale zużywa sekundy przeglądarki, które są rozliczane.
render: false wykonuje szybkie pobieranie HTML bez wykonywania JavaScript. Podczas bety te pobierania nie są rozliczane. To właściwy wybór dla stron statycznych lub serwerowo renderowanych, gdzie treść jest już w początkowym HTML.
Rozliczenia i dostępność
Endpoint jest dostępny zarówno na planach Workers Free, jak i Paid. Renderowane indeksowania są rozliczane w ramach cennika Browser Rendering Cloudflare po 0,09 USD za godzinę przeglądarki powyżej przydzielonego limitu.
Workers Free: 10 minut czasu przeglądarki dziennie. Endpoint /crawl jest ograniczony do 5 zadań dziennie, 100 stron na indeksowanie i 6 żądań API na minutę.
Workers Paid (5 USD/miesiąc): 10 godzin czasu przeglądarki miesięcznie w cenie. Brak limitów stron na indeksowanie. 600 żądań API na minutę. Dodatkowe godziny przeglądarki kosztują 0,09 USD każda.
Indeksowania z render: false zużywają zero czasu przeglądarki. Są darmowe podczas bety, ale ostatecznie będą objęte standardowym cennikiem Workers.
Czym jest czas zegarowy?
Czas zegarowy to całkowity czas od rozpoczęcia indeksowania do jego zakończenia, mierzony tak samo, jakbyś mierzył go stoperem. Obejmuje wszystko: opóźnienia sieci, wewnętrzny czas kolejki Cloudflare, wyszukiwania DNS, czas odpowiedzi serwera i (jeśli renderowanie jest włączone) czas wykonywania przeglądarki.
Czas zegarowy różni się od czasu przeglądarki. Czas przeglądarki liczy tylko sekundy, które przeglądarka headless Cloudflare spędza na aktywnym renderowaniu stron. Indeksowanie może zużyć 22 minuty czasu przeglądarki, ale zająć 25 minut czasu zegarowego z powodu narzutu kolejki i sieci. Indeksowania bez renderowania zużywają zero czasu przeglądarki, ale nadal mają czas zegarowy z procesu pobierania i kolejkowania.
W naszych benchmarkach raportujemy oba numery, abyś mógł zobaczyć, za co płacisz (czas przeglądarki) w porównaniu z tym, jak długo faktycznie czekasz (czas zegarowy).
Drobnym drukiem
Endpoint respektuje dyrektywy robots.txt w tym crawl-delay. Identyfikuje się jako CloudflareBrowserRenderingCrawler/1.0. Nie omija CAPTCHA, wyzwań Turnstile ani innej ochrony przed botami. Jeśli indeksujesz własną witrynę i jesteś blokowany, musisz utworzyć regułę pomijania WAF, aby dodać crawler do białej listy.
Jak Cloudflare /crawl zachowuje się w pięciu sklepach Shopify
Uruchomiliśmy endpoint /crawl na pięciu działających sklepach Shopify, aby zmierzyć szybkość, wskaźnik sukcesu, koszt i interakcję crawlera z każdą witryną. Wszystkie nazwy sklepów są zanonimizowane. To prawdziwe liczby z prawdziwych indeksowań. Czasy zegarowe są przybliżonymi szacunkami. Niektóre wczesne testy używały skryptów z ograniczoną obsługą błędów, co mogło wpłynąć na raportowane wskaźniki sukcesu w niektórych sklepach. Gdzie to ma zastosowanie, zaznaczamy to poniżej.
To nie jest endpoint typu ustaw-i-zapomnij. Każdy sklep reagował inaczej na żądania endpointu. Niektóre potrzebowały blokowania zasobów, aby ukończyć renderowane indeksowanie. Inne zwracały błędy 429 w jednym trybie, ale działały dobrze w drugim. Dyrektywy crawl-delay, liczba stron i architektura sklepu zmieniały wynik. Planuj testowanie i dostrajanie ustawień dla każdej indeksowanej witryny.
Test 1: duży katalog e-commerce (Store A)
Skierowaliśmy endpoint /crawl na duży sklep Shopify z prawie 3000 stron. Treści wracały szybko, markdown był użyteczny, a endpoint nie miał problemów z pobieraniem stron produktów, stron kolekcji i treści bloga. Brak problemów z proxy, brak blokad, brak limitowania ruchu.
Przeprowadziliśmy wiele indeksowań w różnych skalach:
| Rozmiar indeksowania | Zwrócone strony | Tryb | Czas przeglądarki | Czas zegarowy |
|---|---|---|---|---|
| Próbka 20 stron | 20 / 20 (100%) | no-render | 0s | ~1 min |
| Indeksowanie 500 stron | 500 / 500 (100%) | no-render | 0s | ~18 min |
| 5 stron renderowanych | 4 / 5 (80%) | render: true | 0,9s | ~10s |
Indeksowanie bez renderowania JavaScript osiągnęło 100% sukcesu w obu skalach. Pełne renderowanie przeglądarki zwróciło 4 z 5 stron w małym teście próbnym. Przy tak małej próbce brakująca strona może być spowodowana limitem czasu przeglądarki, przejściowym błędem lub problemem po stronie skryptu.
Test 2: mały sklep Shopify (Store D, 24 strony)
Mniejszy sklep, w którym przetestowaliśmy pełny przepływ pracy:
Indeksowanie bez renderowania zwróciło błędy. Nasz początkowy test zwrócił odpowiedzi 429 przy surowym pobieraniu HTML. Nie ponowiliśmy testów tego sklepu z ulepszoną obsługą błędów, więc nie możemy potwierdzić, czy błędy 429 pochodziły z limitowania ruchu sklepu, czy z przejściowych problemów podczas testu.
Pełne renderowanie z odkrywaniem opartym na mapie witryny zakończyło się pełnym sukcesem. 24 z 24 stron zaindeksowanych, 100% ukończenia.
| Typ strony | Liczba |
|---|---|
| Produkty | 9 |
| Kolekcje | 4 |
| Strony | 3 |
| Blog/Aktualności | 5 |
| Inne (strona główna, indeks bloga) | 3 |
Ważne odkrycie: domyślny tryb odkrywania URL-i znalazł tylko 1 stronę, ponieważ strona główna miała prawie zero linków wewnętrznych. Przełączenie na odkrywanie oparte na mapie witryny znalazło wszystkie 24. Jeśli Twoja strona główna jest minimalna lub oparta na JavaScript, crawler może nie znaleźć stron samymi linkami.
Test 3: średni sklep odzieżowy (Store B, 256 stron), z renderowaniem i bez
Nasz najbardziej szczegółowy test. Średni sklep odzieżowy z 256 indeksowalnymi stronami: produkty, kolekcje, posty blogowe i strony informacyjne. Uruchomiliśmy oba tryby na pełnej witrynie, aby zmierzyć faktyczną różnicę.
| Metryka | render: false | render: true | Różnica |
|---|---|---|---|
| Zaindeksowane strony | 256 / 266 | 256 / 266 | Tak samo |
| Całkowite wyjście markdown | 11,0 MB | 12,5 MB | +14% |
| Czas przeglądarki | 0s | 1338s (22 min) | +22 min |
| Szacowany koszt | 0 USD (beta) | ~0,03 USD | +0,03 USD |
| Czas zegarowy | ~5 min | ~25 min | 5x wolniej |
Test 4: sprzedawca suplementów zdrowotnych (Store C), częściowy sukces na dużą skalę
Duży sprzedawca produktów zdrowotnych z ogromnym katalogiem. Przeprowadziliśmy dwa indeksowania bez renderowania w różnych skalach:
| Rozmiar indeksowania | Zwrócone strony | Wskaźnik sukcesu | Czas zegarowy |
|---|---|---|---|
| Próbka 5 stron | 2 / 5 | 40% | ~25s |
| Indeksowanie 100 stron | 89 / 100 | 89% | ~3,5 min |
Częściowy wskaźnik sukcesu może wskazywać, że infrastruktura tego sklepu odrzuca niektóre żądania bez przeglądarki, ale nasz początkowy test nie miał solidnego odzyskiwania po błędach, więc niektóre z tych niepowodzeń mogły być odzyskiwalne z lepszą obsługą ponownych prób po naszej stronie. Wskaźnik sukcesu poprawił się z 40% do 89% przy większej skali. Nie ponowiliśmy testów tego sklepu z ulepszoną obsługą błędów, aby wyizolować przyczynę.
Test 5: duży sklep wielokategoriowy (Store E, ~1200 stron)
Nasz największy i najbardziej odkrywczy test. Sklep Shopify z około 1200 URL-ami rozproszonymi w czterech mapach witryn: 521 produktów, 626 kolekcji, 22 strony i 31 postów blogowych.
| Metryka | render: false | render: true (zoptymalizowane) |
|---|---|---|
| Zaindeksowane strony | 1200 / 1200 | 100 / 100 |
| Całkowite wyjście markdown | 148,5 MB | 11,3 MB |
| Czas przeglądarki | 0s | 475s (~8 min) |
| Szacowany koszt | 0 USD (beta) | ~0,012 USD |
| Czas zegarowy | ~55 min | ~12 min |
Indeksowanie bez renderowania osiągnęło 100% sukcesu na wszystkich 1200 stronach przy zerowym koszcie przeglądarki. Renderowane indeksowanie zostało uruchomione na próbce 100 stron z włączonymi optymalizacjami blokowania zasobów.
Blokowanie zasobów stanowiło różnicę między zawieszonym indeksowaniem a czystym. Bez blokowania zasobów renderowane indeksowanie zawiesiło się na 99 ze 100 stron na czas nieokreślony i zużyło 649 sekund czasu przeglądarki na te 99 stron. Włączenie blokowania zasobów (obrazy, media, czcionki, arkusze stylów) z warunkiem oczekiwania domcontentloaded ukończyło wszystkie 100 stron w 475 sekund, co stanowi 27% redukcję czasu przeglądarki bez zawieszania.
Crawl-delay w robots.txt powodował widoczne przestoje. Plik robots.txt Store E określa 10-sekundowy crawl-delay dla niektórych botów. W naszych danych z odpytywania bez renderowania pojawiało się to jako wielominutowe plateau, gdzie liczba stron się zatrzymywała, a następnie wznawiała. Crawler Cloudflare respektuje dyrektywy crawl-delay, co bezpośrednio wydłuża czas zegarowy na witrynach, które je ustawiają.
Co endpoint /crawl faktycznie akceptuje
Endpoint przyjmuje jeden startowy URL, a nie listę. Odkrywa strony, podążając za linkami z tego URL-a przez mapy witryn, linki na stronach lub oba źródła. Jeśli masz już listę URL-i z indeksowania Scrapy i chcesz użyć Cloudflare do konwersji na markdown, musisz użyć oddzielnych endpointów /markdown lub /scrape indywidualnie dla każdego URL-a.
Co Cloudflare /crawl faktycznie robi po stronie serwera?
Pobraliśmy pełne logi serwera podczas w pełni renderowanego indeksowania Store D (25 stron), aby przeanalizować rzeczywisty ślad ruchu. Wyniki ujawniają fundamentalne różnice między indeksowaniem renderowanym przeglądarką a tradycyjnym indeksowaniem botów, z niezamierzonymi skutkami ubocznymi dla analityki, obciążenia serwera i monitorowania ruchu botów.
| Metryka | Wartość |
|---|---|
| User-Agent | CloudflareBrowserRenderingCrawler/1.0 (100% trafień) |
| Okno indeksowania | 134 sekundy (~2 minuty) |
| Szczytowa przepustowość | 82 żądania/sekundę |
| Unikalne IP | 23, w 5 centrach danych Cloudflare |
| Żądania GET | 2071 |
| Żądania POST | 163 |
| Łączne żądania | 2234 |
| Faktycznie zrenderowane strony | ~25 |
| Żądań na stronę | ~89x wzmocnienie |
Ile ruchu faktycznie generuje w pełni renderowane Cloudflare /crawl?
Największe odkrycie: tylko 1,1% z 2234 żądań stanowiła faktyczna treść strony. Pozostałe 98,9% to JavaScript, CSS, beacony analityczne, piksele śledzące i preloady checkout uruchomione przez przeglądarkę ładującą każdą stronę tak, jak zrobiłby to prawdziwy użytkownik.
Nierobotyzowany bot, taki jak Amazonbot czy ChatGPT-User, generuje 1 żądanie na stronę. Renderer przeglądarki Cloudflare generuje 89.
Czy Cloudflare /crawl zawyża analitykę Shopify?
163 żądania POST w naszych logach to wyłącznie endpointy analityczne i śledzące Shopify uruchamiane podczas indeksowania. To te same zdarzenia, które uruchamiają się, gdy prawdziwy klient odwiedza Twój sklep. Z perspektywy Shopify Analytics crawler Cloudflare wygląda jak odwiedzający przeglądający każdą stronę w Twoim sklepie w 2 minuty.
Jak szybko Cloudflare /crawl uderza w Twój serwer?
Wszystkie 2234 żądania trafiły w 134-sekundowym oknie. Szczytowa przepustowość osiągnęła 82 żądania na sekundę. Crawler zrenderował całą 25-stronicową witrynę w nieco ponad 2 minuty, ale serwer widział ciągłą falę ruchu, która nie wygląda jak organiczne wzorce przeglądania.
Dla małych sklepów jest to do zarządzania. Dla większych sklepów z tysiącami stron wzmocnienie żądań (89x na stronę) w połączeniu z ciągłą przepustowością może stworzyć znaczne obciążenie serwera źródłowego, szczególnie jeśli jesteś na współdzielonym hostingu lub masz agresywne limitowanie ruchu.
Skąd pochodzi Cloudflare /crawl?
Indeksowanie było rozproszone w 5 centrach danych Cloudflare w USA:
| Centrum danych | % żądań | Lokalizacja |
|---|---|---|
| ATL | 38% | Atlanta |
| ORD | 25% | Chicago |
| MIA | 23% | Miami |
| EWR | 9% | Newark |
| IAD | 5% | Washington DC |
To nie jeden serwer wysyłający żądania. Cloudflare rozprasza obciążenie renderowania w swojej sieci brzegowej. Wszystkie 23 IP mieściły się w zakresie 104.28.x.x, a user-agent to CloudflareBrowserRenderingCrawler/1.0 na każdym pojedynczym żądaniu.
Jaki fingerprint przeglądarki zostawia Cloudflare /crawl?
Renderer wysyła poprawne nagłówki Sec-Fetch, które naśladują prawdziwą przeglądarkę Chrome:
| Nagłówek | Wartość | Prawdziwy Chrome? |
|---|---|---|
sec-fetch-dest |
script, document itp. |
Tak, pasuje |
sec-fetch-mode |
cors, navigate |
Tak, pasuje |
sec-fetch-site |
same-origin, cross-site |
Tak, pasuje |
sec-ch-ua (Client Hints) |
Nie wysyłany | Nie, prawdziwy Chrome to wysyła |
| Wersja HTTP | HTTP/1.1 | Nie, prawdziwy Chrome negocjuje HTTP/2 lub HTTP/3 |
Dwie luki w fingerprincie wyróżniają się: renderer pomija nagłówki sec-ch-ua Client Hints (prawdziwa przeglądarka Chrome zawsze je wysyła), a wszystkie żądania używają HTTP/1.1 zamiast HTTP/2 lub HTTP/3. Jeśli budujesz reguły wykrywania botów, to wiarygodne sygnały do odróżnienia renderera przeglądarki Cloudflare od faktycznego ruchu użytkowników.
Jak Cloudflare /crawl wypada w porównaniu z innymi botami AI w logach serwera?
Porównaliśmy indeksowanie Cloudflare z innymi botami, które trafiały w ten sam sklep w tym samym 12-godzinnym oknie:
Amazonbot i ChatGPT-User pobierają surowy HTML: jedno żądanie, jedna strona, brak wykonywania JavaScript. AhrefsBot indeksuje mapy witryn do odkrywania. Renderer przeglądarki Cloudflare wykonuje pełną witrynę Shopify na każdej stronie, uruchamiając każdy skrypt, piksel i preload, jakby prawdziwy klient przeglądał sklep.
Szybkość i koszt Cloudflare /crawl: pełny benchmark
Każde indeksowanie, które przeprowadziliśmy, w jednej tabeli. Wszystkie sklepy zanonimizowane, wszystkie liczby z prawdziwych testów. Czasy zegarowe są przybliżone. Wskaźniki sukcesu dla Store C i D mogły być dotknięte ograniczoną obsługą błędów w naszych początkowych skryptach testowych.
| Sklep | Strony | Tryb | Wskaźnik sukcesu | Czas przeglądarki | Czas zegarowy | Koszt |
|---|---|---|---|---|---|---|
| A: Duży e-commerce | 500 / 500 | no-render | 100% | 0s | ~18 min | 0 USD |
| B: Średnia odzież | 256 / 266 | no-render | 96% | 0s | ~5 min | 0 USD |
| C: Zdrowie i suplementy | 89 / 100 | no-render | 89% | 0s | ~3,5 min | 0 USD |
| D: Mały Shopify | 24 / 24 | render: true | 100% | 58s | ~2 min | ~0,002 USD |
| E: Duży wielokategoriowy | 1200 / 1200 | no-render | 100% | 0s | ~55 min | 0 USD |
Jak szybki jest Cloudflare /crawl z renderowaniem vs. bez?
Najczystsze porównanie pochodzi z Store B, gdzie uruchomiliśmy oba tryby na dokładnie tych samych 256 stronach:
Wzorzec we wszystkich jedenastu indeksowaniach jest spójny: indeksowanie bez renderowania jest dramatycznie szybsze. Czas zegarowy bez renderowania to głównie wewnętrzny narzut kolejki i pobierania Cloudflare. Pełne renderowanie dodaje około 5 sekund czasu przeglądarki na stronę ponad tę bazową wartość.
Ile kosztuje w pełni renderowane indeksowanie Cloudflare na stronę?
Cennik Browser Rendering Cloudflare opiera się na godzinach przeglądarki, czyli czasie, który ich przeglądarka headless spędza na aktywnym renderowaniu Twoich stron. Indeksowanie bez renderowania zużywa zero godzin przeglądarki i jest darmowe podczas bety.
Plan Workers Free: 10 minut czasu przeglądarki dziennie. Endpoint /crawl jest dodatkowo ograniczony do 5 zadań indeksowania dziennie, z maksymalnie 100 stronami na indeksowanie.
Plan Workers Paid (5 USD/miesiąc): 10 godzin czasu przeglądarki miesięcznie w cenie. Powyżej tego płacisz 0,09 USD za dodatkową godzinę przeglądarki. Brak limitów stron na indeksowanie. Do 600 żądań API na minutę.
Oto, ile faktycznie kosztowały nasze testowe indeksowania przy 0,09 USD/godz.:
| Indeksowanie | Zużyty czas przeglądarki | Koszt przy 0,09 USD/godz. |
|---|---|---|
| Store D: 24 strony renderowane | 58 sekund | ~0,002 USD |
| Store B: 256 stron renderowanych | 1338 sekund (~22 min) | ~0,03 USD |
| Katalog 3000 stron (szacunkowy) | ~4 godziny | ~0,36 USD |
Przy około 5 sekundach czasu przeglądarki na stronę wszystkie te koszty mieszczą się w 10 godzinach zawartych w planie płatnym. Renderowane indeksowanie 3000 stron zużyłoby około 4 z Twoich 10 wliczonych godzin, co oznacza, że możesz przeprowadzić dwa pełne indeksowania miesięcznie, zanim zapłacisz cokolwiek ponad bazowe 5 USD. Indeksowanie bez renderowania jest darmowe i nie zużywa czasu przeglądarki na żadnym planie.
Kiedy pominąć renderowanie, a kiedy użyć pełnego renderowania w Cloudflare /crawl?
Podsumowanie
Dla większości sklepów Shopify z serwerowo renderowaną treścią indeksowanie bez renderowania daje ponad 90% użytecznej treści przy zerowym koszcie w ułamku czasu.
Czego nauczyliśmy się testując Cloudflare /crawl na sklepach Shopify
Po przeprowadzeniu 11 indeksowań na 5 działających sklepach Shopify i przeanalizowaniu pełnych logów serwera, oto odkrycia, które mają największe znaczenie.
90% treści przychodzi bez renderowania
Dla sklepów Shopify ze standardowymi serwerowo renderowanymi stronami indeksowanie bez renderowania JavaScript przechwytywało ponad 90% użytecznej treści. 14% wzrost treści z pełnego renderowania pochodził prawie wyłącznie z elementów ładowanych JavaScript na stronach głównych i stronach indeksowych. Poszczególne strony produktów i artykuły blogowe były niemal identyczne w obu trybach. O ile Twój sklep nie jest zbudowany jako aplikacja jednostronicowa, prawdopodobnie nie potrzebujesz pełnego renderowania.
Pełne renderowanie tworzy 89-krotny mnożnik ruchu
Renderowanie 25 stron wygenerowało 2234 żądania serwera. Tylko 25 z nich stanowiło faktyczną treść strony. Pozostałe 98,9% to pliki JavaScript (75%), beacony analityczne (6,3%), CSS (4,3%), piksele śledzące (3,4%) i preloady checkout (3,3%). Każda renderowana strona uruchamia pełny stos Shopify po stronie klienta, jakby prawdziwy klient przeglądał witrynę.
Twoja analityka Shopify jest prawdopodobnie zawyżana
Renderowane indeksowania uruchamiają pełny stos analityczny Shopify: beacony monorail, zdarzenia śledzące, preloady Shop Pay i skrypty web-pixel. Uważamy, że Shopify Analytics liczy je jako prawdziwe sesje użytkowników. Jeśli tak jest, pojedyncze renderowane indeksowanie mogłoby zawyżyć liczbę sesji, odsłon i dane lejka konwersji. Nie potwierdziliśmy tego bezpośrednio w raportach Shopify, ale logi serwera pokazują wszystkie te same zdarzenia analityczne, które uruchamiałyby się dla prawdziwego klienta.
Pełne renderowanie może ominąć limity ruchu sklepu
Store D zwracał błędy 429 na każdej stronie bez renderowania. Przełączenie na pełne renderowanie w tym samym sklepie dało 100% sukcesu. Jeśli napotykasz limity ruchu bez renderowania, pełne renderowanie jest rozwiązaniem.
Odkrywanie przez mapę witryny jest bardziej niezawodne niż odkrywanie przez linki
Domyślne odkrywanie przez linki nie znalazło prawie nic w Store D, ponieważ strona główna miała bardzo mało linków wewnętrznych. Przełączenie na odkrywanie przez mapę witryny znalazło wszystkie 24 strony. Zawsze używaj odkrywania przez mapę witryny.
Crawler pochodzi z 5 centrów danych w USA
Cloudflare rozprasza obciążenie renderowania w swojej sieci brzegowej. Nasze indeksowanie pochodziło z 23 unikalnych IP w Atlanta (38%), Chicago (25%), Miami (23%), Newark (9%) i Washington DC (5%). Wszystkie IP mieszczą się w zakresie 104.28.x.x.
Dwie luki w fingerprincie identyfikują go jako bota
Renderer pomija nagłówki sec-ch-ua Client Hints (prawdziwy Chrome zawsze je wysyła) i używa HTTP/1.1 zamiast HTTP/2 lub HTTP/3. Jeśli budujesz reguły wykrywania botów, to wiarygodne sygnały.
Renderowanie może faktycznie zwrócić mniej treści
W Store E indeksowanie bez renderowania zwróciło 6,8% więcej treści na stronę niż renderowane indeksowanie. Blokowanie obrazów, czcionek i arkuszy stylów w celu optymalizacji czasu przeglądarki uniemożliwiło również niektórym skryptom JavaScript wypełnianie dynamicznych elementów. Statyczny HTML miał już wszystko. Dla serwerowo renderowanych sklepów Shopify renderowanie nie gwarantuje przechwycenia większej ilości treści.
Blokowanie zasobów zapobiega zawieszonym indeksowaniom
Bez blokowania zasobów renderowane indeksowanie w Store E zawiesiło się na 99 ze 100 stron i nigdy się nie ukończyło. Włączenie blokowania obrazów, mediów, czcionek i arkuszy stylów z warunkiem oczekiwania domcontentloaded ukończyło wszystkie 100 stron i zmniejszyło czas przeglądarki o 27%. Jeśli Twoje renderowane indeksowania zawieszają się przed ukończeniem, blokowanie zasobów jest rozwiązaniem.
robots.txt crawl-delay wydłuża czas zegarowy
Plik robots.txt Store E określa 10-sekundowy crawl-delay. W naszych danych z odpytywania bez renderowania pojawiało się to jako wielominutowe plateau, gdzie liczba stron się zatrzymywała, a następnie wznawiała. Crawler Cloudflare respektuje dyrektywy crawl-delay, więc witryny z agresywnymi opóźnieniami będą miały znacznie dłuższe czasy zegarowe, niż sugerowałaby sama liczba stron.
Koszt jest niski, ale plan darmowy ma ograniczenia
Renderowanie 256 stron kosztowało około 0,03 USD przy 0,09 USD za godzinę przeglądarki. Renderowanie 24 stron kosztowało około 0,002 USD. Plan Workers Free ogranicza czas przeglądarki do 10 minut dziennie z maksymalnie 5 zadaniami indeksowania i 100 stronami na indeksowanie. Plan Workers Paid (5 USD/miesiąc) obejmuje 10 godzin czasu przeglądarki miesięcznie bez limitów na indeksowanie. Renderowane indeksowanie 3000 stron zużyłoby około 4 z tych 10 wliczonych godzin, więc większość sklepów mieści się wygodnie na planie płatnym bez dodatkowych opłat. Indeksowanie bez renderowania zużywa zero czasu przeglądarki i jest darmowe na obu planach podczas bety.
Zalety
Szybkość
Strony pobierane niemal natychmiast w porównaniu z wielogodzinnym indeksowaniem Scrapy z autothrottle. Brak kolejkowania, brak opóźnień uprzejmościowych, brak czekania na pająka przetwarzającego tysiące żądań w rozsądnym tempie.
Wyjście Markdown
Endpoint zwraca gotową konwersję HTML-na-Markdown dla każdej strony. Jest to bezpośrednio przydatne do zasilania LLM, pipeline’ów RAG i analizy treści bez żadnego przetwarzania końcowego. Pomijasz całą warstwę ekstrakcji i przechodzisz prosto do czystego tekstu. Dla zespołów budujących aplikacje AI na treściach witryn eliminuje to krok z pipeline’u.
Opcja trybu renderowania
Ustawienie render: true wykonuje JavaScript i automatycznie wyodrębnia metadane Open Graph (og:title, og:description, og:image, og:site_name). Dla witryn z dużą ilością JavaScript, gdzie treść jest renderowana po stronie klienta, to jest różnica między zobaczeniem prawdziwej strony a zobaczeniem pustej powłoki.
Brak problemów z proxy i limitowaniem ruchu
Cloudflare obsługuje zabezpieczenia anti-bot i limitowanie ruchu na własnej infrastrukturze. Nie musisz zarządzać pulami proxy, rotować user-agentów ani radzić sobie z CAPTCHA. Jedno wywołanie API.
Indeksowanie przyrostowe
Parametry modifiedSince i maxAge pozwalają pomijać strony, które się nie zmieniły lub zostały niedawno pobrane. Dla cyklicznych indeksowań, gdzie monitorujesz zmiany treści, oszczędza to zarówno czas, jak i koszt, przetwarzając tylko strony, które są faktycznie nowe lub zaktualizowane.
Prostota
Jedno wywołanie API. Odpowiedź JSON. Brak kodu pająka, brak middleware, brak pipeline’ów elementów, brak plików ustawień.
Dobrze zachowujący się bot domyślnie
Crawler jest podpisanym agentem, który respektuje robots.txt, crawl-delay i Cloudflare AI Crawl Control. Identyfikuje się jako CloudflareBrowserRenderingCrawler/1.0 i nie może omijać ochrony przed botami ani CAPTCHA. Otrzymujesz etyczną zgodność z indeksowaniem bez budowania logiki samodzielnie.
Czego endpoint Cloudflare Crawl nie obsługuje
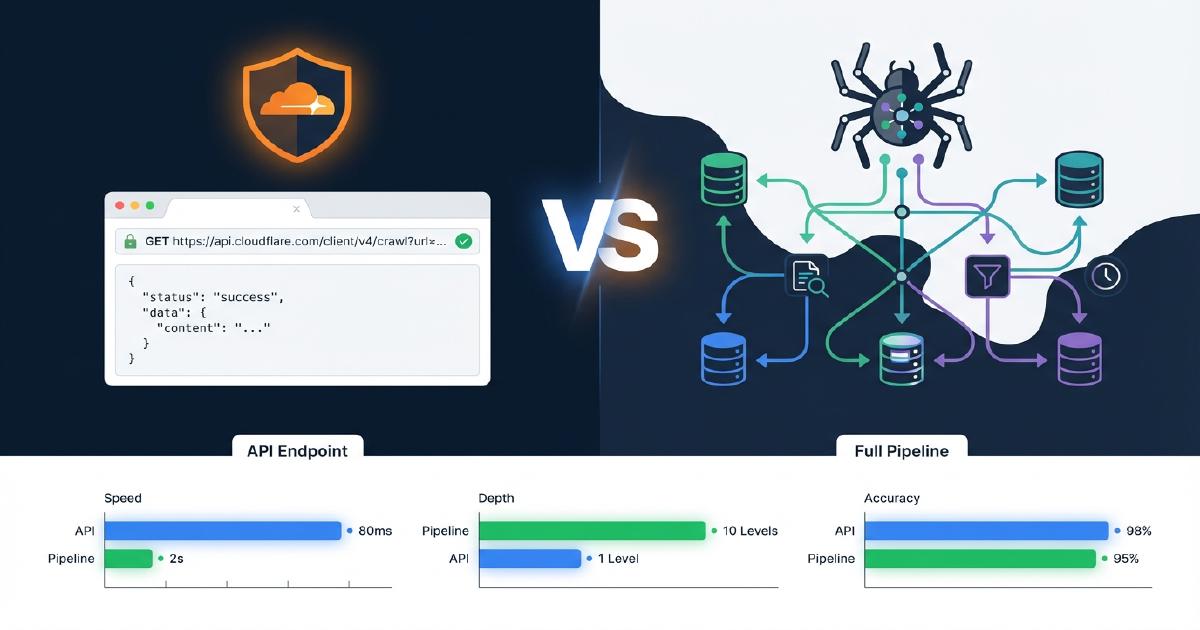
Czym różni się Cloudflare /crawl od pełnego pipeline indeksowania?
Poniższa tabela pokazuje dokładnie, które możliwości są obecne w endpoincie /crawl Cloudflare w porównaniu z produkcyjnym pipeline Scrapy. Opiera się to na naszych rzeczywistych testach na sklepach Shopify.
| Możliwość | Cloudflare /crawl | Pipeline Scrapy |
|---|---|---|
| Pobieranie treści (HTML/Markdown) | Tak | Tak |
| Renderowanie JavaScript | Tak (render: true) |
Tak (Splash/Playwright) |
| Odkrywanie linków / spidering | Tak (płaska lista) | Tak (pełny graf indeksowania) |
| Mapowanie linków nadrzędnych i podrzędnych | Nie | Tak |
| Wykrywanie stron osieroconych | Nie | Tak |
| Śledzenie łańcuchów przekierowań | Nie | Tak |
| Ekstrakcja JSON-LD | Nie | Tak |
| Ekstrakcja Microdata | Nie | Tak |
| Walidacja schematów + raportowanie problemów | Nie | Tak |
| Kody statusu inne niż 200 (404, 403) | Nie | Tak (przechwycono 2547 błędów 404 w naszym teście) |
| Limit URL-i | 100 000 | Brak |
Jakie dane strukturalne wyodrębnia Cloudflare /crawl?
Z render: false, żadne. Brak parsowania JSON-LD, Microdata ani OpenGraph.
Z render: true, tylko podstawowe tagi OG (og:title, og:description, og:image, og:site_name). JSON-LD i znaczniki schema.org nie są parsowane, wyodrębniane ani walidowane.
Dla porównania, nasz pipeline Scrapy generuje schemas_found, issues (brakujący contactPoint, address itp.), top_level_schemas i nested_schemas dla każdego URL-a. Możesz zobaczyć, które strony mają schemat Product, którym brakuje znaczników Organization i które mają błędy walidacji, które mogłyby powodować, że systemy AI źle odczytują treść.
Jakie kody statusu HTTP zwraca Cloudflare /crawl?
Tylko odpowiedzi 200. Nasze indeksowanie Scrapy tej samej witryny przechwyciło 2547 błędów 404, plus odpowiedzi 403 i błędy połączenia. Wykrywanie 404 jest kluczowe dla analizy stron widmo, naprawy uszkodzonych linków i mapowania przekierowań. Bez tego brakuje Ci stron, które aktywnie tracą wartość linków i dezorientują crawlery AI.
Ile URL-i może przetworzyć Cloudflare /crawl?
Do 100 000 na zadanie. To obejmuje większość witryn, ale duże katalogi e-commerce z setkami tysięcy stron produktów, wariantów URL-i i filtrowanych stron kolekcji przekroczą ten limit. Scrapy nie ma wbudowanego limitu URL-i.
Czy Cloudflare /crawl ma błąd rozwiązywania URL-i?
Znaleźliśmy 233 z 908 linków na jednej stronie produktu z uszkodzonymi ścieżkami. Konwerter markdown rozwiązuje względne URL-e względem URL-a strony niepoprawnie, tworząc podwójne URL-e jak /products/slug//www.example.com/.... To potwierdzony błąd w konwerterze Cloudflare, który wpływa na każdą dalszą analizę linków.
Ile szablonu jest w wyjściu markdown Cloudflare /crawl?
Średnia strona zwracała 158 KB markdown. Około 90% to powtarzające się treści szablonu: pełna nawigacja, mega menu i stopka w każdym rekordzie. Dla analizy treści oznacza to ciężką pracę deduplikacji, a dla zużycia tokenów LLM koszt szybko rośnie. Potrzebujesz własnej logiki ekstrakcji treści ponad markdown, aby wyizolować faktyczną treść strony.
Czego Cloudflare /crawl nie klasyfikuje?
Nie ma oznaczania typów treści. Strony produktów, strony kolekcji, posty blogowe i strony główne wracają jako niezróżnicowane rekordy. Scrapy klasyfikuje każdy URL według typu, co jest niezbędne do zrozumienia pokrycia indeksowania według kategorii stron i do identyfikacji, które typy treści priorytetyzują boty AI.
Jakich funkcji finalizacji brakuje w Cloudflare /crawl?
Brak zrzutów ekranu stron widmo. Brak porównania renderowania JavaScript (co widzi bot vs. co widzi przeglądarka). Brak analizy botów AI w robots.txt. Brak raportu jakości indeksowania. Brak manifestu klienta. Brak synchronizacji CDN. Dane Cloudflare to tylko surowa treść. Każdy element pipeline raportowania i analizy musiałby być zbudowany osobno.
Ile kosztuje Cloudflare /crawl dla dużych witryn?
W naszych testach render: true wymagał średnio około 5 sekund wykonywania przeglądarki na stronę. Indeksowanie 256 stron zużyło 1338 sekund przeglądarki (22 minuty) i kosztowało około 0,03 USD przy 0,09 USD za godzinę przeglądarki. Indeksowanie 24 stron zużyło 58 sekund i kosztowało około 0,002 USD. Ekstrapolując na katalog 3000 stron: około 4 godziny czasu przeglądarki. Plan Workers Free jest ograniczony do 10 minut czasu przeglądarki dziennie, 5 zadań indeksowania dziennie i 100 stron na indeksowanie. Plan Workers Paid (5 USD/miesiąc) obejmuje 10 godzin czasu przeglądarki miesięcznie bez limitów na indeksowanie, więc indeksowanie 3000 stron zużyłoby około 4 z tych 10 wliczonych godzin. render: false zużywa zero czasu przeglądarki i jest darmowy podczas bety na obu planach.
Podsumowanie
Endpoint crawl Cloudflare jest świetny do:
- Szybkich migawek treści, gdy potrzebujesz tekstu strony natychmiast
- Markdown gotowego dla LLM do pipeline’ów RAG i przetwarzania treści
- Ad-hoc sprawdzania stron, gdy znasz dokładne URL-e, których potrzebujesz
- Szybkiego pobierania treści z całej witryny, gdy potrzebujesz tekstu markdown bez budowania pająka
Nie może zastąpić pełnego pipeline indeksowania, ponieważ wartość pipeline leży w:
- Pełnym grafie indeksowania z topologią linków, wykrywaniem stron osieroconych i pokryciem 404
- Ekstrakcji i walidacji danych strukturalnych (JSON-LD, Microdata, OpenGraph)
- Klasyfikacji treści według typu strony
- Całym pipeline finalizacji, w tym analiza stron widmo, porównanie renderowania JavaScript, raporty schematów i ocena gotowości LLM
Najlepsze podejście hybrydowe
Używaj Cloudflare jako uzupełniającego źródła danych. Po pełnym indeksowaniu, które zidentyfikuje Twoje URL-e, użyj wyjścia markdown Cloudflare do zasilania oceny gotowości LLM lub analizy jakości treści, gdy potrzebujesz faktycznego tekstu strony, a nie metadanych strukturalnych. Pipeline indeksowania odkrywa i klasyfikuje. Endpoint Cloudflare dostarcza czysty tekst dla stron, które się liczą.
Chcesz zobaczyć pełny pipeline indeksowania w akcji?
Umów rozmowęNajczęściej zadawane pytania
Które funkcje audytu stron nie są obsługiwane przez Cloudflare /crawl?
Cloudflare /crawl nie obsługuje: budowania pełnego grafu indeksowania, mapowania linków nadrzędnych i podrzędnych, wykrywania stron osieroconych, śledzenia łańcuchów przekierowań, ekstrakcji JSON-LD lub Microdata, walidacji schematów, przechwytywania kodów statusu innych niż 200 (404, 403), klasyfikacji typów treści, pomiaru rozmiaru stron w bajtach, wykrywania stron widmo, porównania renderowania JS z HTML, analizy botów AI w robots.txt ani krzyżowego porównywania linków zwrotnych. To narzędzie do pobierania treści, a nie narzędzie do audytu stron.
Czym różni się Cloudflare /crawl od Scrapy w indeksowaniu e-commerce?
Cloudflare /crawl szybko pobiera treści bez konieczności zarządzania infrastrukturą. Scrapy buduje kompletny graf indeksowania z topologią linków, wyodrębnia i waliduje dane strukturalne (JSON-LD, Microdata, OpenGraph), przechwytuje wszystkie kody statusu HTTP w tym 404, klasyfikuje strony według typu treści i zasila dalszy pipeline do analizy stron widmo, raportów schematów i oceny gotowości LLM. Cloudflare daje tekst strony; Scrapy daje pełną architekturę witryny.
Jaki jest dokładny limit URL-i dla Cloudflare /crawl?
100 000 URL-i na zadanie indeksowania. Domyślny limit to 10, więc musisz go ustawić jawnie. Maksymalna depth to również 100 000. Dla witryn przekraczających 100 tys. stron wymagany jest Scrapy lub inny crawler bez wbudowanego limitu URL-i.
Czy Cloudflare /crawl wyodrębnia JSON-LD lub waliduje znaczniki schema?
Nie. Z render: false nie są wyodrębniane żadne dane strukturalne. Z render: true zwracane są tylko podstawowe tagi Open Graph (og:title, og:description, og:image, og:site_name). JSON-LD, Microdata i znaczniki schema.org nie są parsowane, wyodrębniane ani walidowane w żadnym trybie.
Ile kosztuje Cloudflare /crawl przy renderowaniu dużych witryn?
W naszych testach render: true wymagał średnio około 5 sekund czasu przeglądarki na stronę. Witryna o 256 stronach zużyła 1338 sekund przeglądarki (22 minuty) i kosztowała około 0,03 USD przy 0,09 USD za godzinę przeglądarki. Witryna o 24 stronach zużyła 58 sekund i kosztowała około 0,002 USD. Ekstrapolując na katalog 3000 stron: około 4 godziny czasu przeglądarki. Plan Workers Free jest ograniczony do 10 minut dziennie, 5 zadań indeksowania dziennie i 100 stron na indeksowanie, więc duże renderowane indeksowania wymagają planu Workers Paid (5 USD/miesiąc), który obejmuje 10 godzin czasu przeglądarki miesięcznie bez limitów na indeksowanie. render: false zużywa zero czasu przeglądarki i jest darmowy podczas bety na obu planach.
Czy Cloudflare /crawl ma znany błąd rozwiązywania URL-i?
Tak. W naszym teście 233 z 908 linków na jednej stronie produktu miało zniekształcone ścieżki. Konwerter markdown dodaje URL strony przed ścieżkami względnymi jak //www.example.com/cdn/..., tworząc uszkodzone podwójne URL-e. Wpływa to na każdą dalszą analizę grafu linków lub audyt linkowania wewnętrznego oparty na wyjściu markdown.
Dlaczego Cloudflare /crawl z render false zwraca błędy 429 w niektórych sklepach Shopify?
render: false wykonuje surowe pobieranie HTML bez przeglądarki headless. W jednym z naszych testów render: false zwracał błędy 429, podczas gdy render: true działał ze 100% skutecznością w tym samym sklepie. Nie ponowiliśmy testów z ulepszoną obsługą błędów, więc błędy 429 mogły być spowodowane limitowaniem ruchu przez sklep, przejściowymi problemami API lub ich kombinacją. Jeśli widzisz błędy 429 bez renderowania, spróbuj render: true jako pierwszy krok.
Czy Cloudflare /crawl akceptuje listę URL-i?
Nie. Endpoint przyjmuje jeden startowy URL i odkrywa strony, podążając za linkami przez mapy witryn, linki na stronach lub oba źródła. Jeśli masz już listę URL-i i chcesz konwersji markdown od Cloudflare, użyj oddzielnych endpointów /markdown lub /scrape, które przyjmują pojedyncze URL-e na żądanie.
Dlaczego Cloudflare /crawl z source all znajduje tylko jedną stronę na niektórych witrynach?
Domyślne source: all odkrywa URL-e zarówno z map witryn, jak i linków na stronach. Jeśli startowy URL ma bardzo mało linków wewnętrznych (częste na minimalnych stronach głównych lub SPA opartych na JavaScript), crawler może nie znaleźć dodatkowych stron samym odkrywaniem linków. Przełącz na source: sitemaps, aby upewnić się, że crawler odczyta pełny sitemap.xml i odkryje wszystkie wymienione URL-e.
Jaki jest najlepszy sposób użycia Cloudflare /crawl z pełnym pipeline indeksowania?
Najpierw użyj pełnego pipeline indeksowania (Scrapy lub odpowiednik) do odkrywania URL-i, budowania grafu linków, wyodrębniania danych strukturalnych, przechwytywania 404 i klasyfikacji treści. Następnie użyj endpointów /markdown lub /scrape Cloudflare do pobrania czystego markdown do oceny gotowości LLM, analizy jakości treści lub przetwarzania RAG, gdy potrzebujesz faktycznego tekstu strony, a nie metadanych strukturalnych.
O ile szybszy jest Cloudflare /crawl render false w porównaniu z render true?
W naszym bezpośrednim teście na tej samej witrynie o 256 stronach render: false ukończył się w około 5 minut. render: true zajął około 25 minut dla tych samych stron. To 5-krotna różnica w szybkości. Różnica w czasie zegarowym wynika z około 5 sekund wykonywania przeglądarki dodawanych na stronę, gdy renderowanie jest włączone. render: false kosztował 0 USD podczas bety. render: true kosztował około 0,03 USD za to samo indeksowanie.
Ile dodatkowej treści przechwytuje Cloudflare /crawl render true w porównaniu z render false?
W naszym teście 256 stron render: true wygenerował 12,5 MB markdown w porównaniu z 11,0 MB z render: false, co stanowi 14% wzrost. Dodatkowa treść pochodziła prawie wyłącznie z elementów ładowanych JavaScript na stronie głównej i stronach indeksów bloga. Poszczególne strony produktów i artykuły blogowe były niemal identyczne w obu trybach. Dla witryn z głównie serwerowo renderowaną treścią render: false przechwytuje ponad 90% użytecznego tekstu przy zerowym koszcie i 5-krotnie szybszym działaniu.
Czy Cloudflare /crawl działa niezawodnie we wszystkich sklepach Shopify?
To zależy od sklepu i trybu renderowania. W naszych testach na pięciu sklepach Shopify: Store A (duży katalog) osiągnął 100% sukcesu z render: false. Store B (średnia odzież) osiągnął 96% sukcesu w obu trybach. Store C (zdrowie i suplementy) osiągnął 40% na próbce 5 stron i 89% na indeksowaniu 100 stron z render: false, choć nasz początkowy test nie miał solidnego odzyskiwania po błędach i niektóre niepowodzenia mogły być odzyskiwalne. Store D (mały sklep) zwracał błędy 429 z render: false, ale osiągnął 100% z render: true. Store E (duży wielokategoriowy, ~1200 stron) osiągnął 100% sukcesu z render: false i 100% na 100-stronicowej renderowanej próbce z optymalizacjami blokowania zasobów. Nie ponowiliśmy testów Store C i D z ulepszoną obsługą błędów. Przetestuj oba tryby w swoim konkretnym sklepie przed podjęciem decyzji o strategii indeksowania.
Jaki jest czas zegarowy dla Cloudflare /crawl 500 stron z render false?
W naszym teście indeksowanie 500 stron z render: false ukończyło się w około 18 minut ze 100% skutecznością. Indeksowanie 256 stron w innym sklepie ukończyło się w około 5 minut. Indeksowanie 100 stron ukończyło się w około 3,5 minuty. Te czasy zegarowe są szacunkami opartymi na interwałach odpytywania, a nie precyzyjnymi pomiarami. Czas zegarowy to głównie wewnętrzny narzut kolejki i pobierania HTTP Cloudflare, a nie renderowanie przeglądarki, ponieważ z render: false nie są zużywane żadne sekundy przeglądarki.
Ile żądań serwera generuje Cloudflare /crawl render true?
W naszej analizie logów serwera jedno indeksowanie render: true 25 stron wygenerowało 2234 żądania łącznie: 2071 GET i 163 POST. To około 89 żądań serwera na faktycznie zrenderowaną stronę. Tylko 1,1% żądań stanowiła faktyczna treść strony. Pozostałe 98,9% to pliki JavaScript (75%), beacony analityczne (6,3%), CSS (4,3%), piksele śledzące (3,4%) i preloady checkout (3,3%). Jeśli monitorujesz ruch botów lub zarządzasz obciążeniem serwera, oczekuj, że renderowane indeksowanie wygeneruje 89-krotnie więcej żądań niż faktyczna liczba stron w logach serwera.
Jakiego user-agenta używa Cloudflare /crawl i z jakiego zakresu IP pochodzi?
Crawler identyfikuje się jako CloudflareBrowserRenderingCrawler/1.0 w 100% żądań. W naszych logach wszystkie żądania pochodziły z 23 unikalnych IP w zakresie 104.28.x.x, rozłożonych na 5 centrów danych Cloudflare w USA: ATL (38%), ORD (25%), MIA (23%), EWR (9%) i IAD (5%). Nie ma rotacji user-agenta ani maskowania IP. Crawler jest z założenia podpisanym, identyfikowalnym botem.
Czy Cloudflare /crawl zawyża analitykę Shopify i liczbę odwiedzających?
Uważamy, że tak, ale nie potwierdziliśmy tego bezpośrednio w raportach Shopify. Ponieważ render: true wykonuje JavaScript, uruchamia pełny stos analityczny Shopify na każdej stronie: beacony monorail, zdarzenia śledzące /api/collect, preloady checkout Shop Pay i skrypty web-pixel sandbox. W naszym teście 163 z 2234 żądań to żądania POST do endpointów analitycznych Shopify. To te same zdarzenia, które uruchamiają się dla prawdziwych klientów. Jeśli Shopify liczy je jako prawdziwe sesje, Twoje liczby sesji, odsłon i dane lejka konwersji byłyby zawyżone.
Jak wykryć Cloudflare /crawl w logach serwera w porównaniu z prawdziwym ruchem przeglądarki?
Dwie wiarygodne luki w fingerprincie: renderer przeglądarki Cloudflare pomija nagłówki sec-ch-ua Client Hints (prawdziwa przeglądarka Chrome zawsze je wysyła), a wszystkie żądania używają HTTP/1.1 zamiast HTTP/2 lub HTTP/3, które negocjowałaby prawdziwa przeglądarka. Wysyła poprawne nagłówki sec-fetch-dest, sec-fetch-mode i sec-fetch-site, które pasują do prawdziwego Chrome. User-agent to zawsze CloudflareBrowserRenderingCrawler/1.0, a wszystkie IP mieszczą się w zakresie 104.28.x.x.