
Apakah Endpoint Cloudflare /crawl?
Endpoint /crawl Cloudflare adalah sebahagian daripada API Browser Rendering mereka, kini dalam beta terbuka. Ia mengikis kandungan daripada URL permulaan, mengikuti pautan merentasi laman sehingga kedalaman atau had halaman yang boleh dikonfigurasikan, dan mengembalikan hasilnya sebagai HTML, Markdown, atau JSON berstruktur yang dikuasakan oleh Workers AI. Cloudflare meletakkannya sebagai alat untuk melatih model, membina saluran RAG, dan menyelidik atau memantau kandungan merentasi sesebuah laman.
Endpoint ini beroperasi sebagai ejen bertandatangan yang menghormati robots.txt dan Kawalan Rangkak AI Cloudflare secara lalai, yang merupakan pilihan reka bentuk yang ketara. Ia bertujuan memudahkan pembangun mematuhi peraturan laman web dan menyukarkan perangkak mengabaikan panduan pemilik laman.
Endpoint ini berada di:
https://api.cloudflare.com/client/v4/accounts/<account_id>/browser-rendering/crawl
Anda memerlukan token API Cloudflare dengan kebenaran Browser Rendering Edit untuk menggunakannya.
Cara Ia Berfungsi
Rangkakan berjalan sebagai tugas tak segerak dalam dua langkah:
- Mulakan rangkakan dengan permintaan POST yang mengandungi URL permulaan. API mengembalikan ID tugas serta-merta.
- Tinjau keputusan dengan permintaan GET menggunakan ID tugas tersebut. Apabila status tugas bertukar daripada
runningkepadacompleted, data rangkakan anda sudah sedia.
Tugas boleh berjalan sehingga tujuh hari. Keputusan disimpan selama 14 hari selepas selesai.
Apa yang Anda Hantar
Sekurang-kurangnya, anda hantar satu URL:
curl -X POST 'https://api.cloudflare.com/client/v4/accounts/{account_id}/browser-rendering/crawl' \
-H 'Authorization: Bearer <apiToken>' \
-H 'Content-Type: application/json' \
-d '{
"url": "https://example.com"
}'
Parameter Utama
| Parameter | Lalai | Fungsinya |
|---|---|---|
limit |
10 | Halaman maksimum untuk dirangkak (sehingga 100,000) |
depth |
100,000 | Kedalaman pautan maksimum dari URL permulaan |
source |
all |
Di mana URL ditemui: all, sitemaps, atau links |
formats |
HTML | Format respons: html, markdown, atau json |
render |
true | Laksanakan JavaScript (true) atau ambilan HTML pantas (false) |
maxAge |
86,400 | TTL cache dalam saat (maksimum 604,800) |
modifiedSince |
tiada | Cap masa Unix: hanya rangkak halaman yang diubah suai selepas masa ini |
options.includePatterns |
tiada | Hanya rangkak URL yang sepadan dengan corak wildcard ini |
options.excludePatterns |
tiada | Langkau URL yang sepadan dengan corak ini |
Apa yang Anda Dapat Kembali
Setiap halaman yang dirangkak dikembalikan sebagai rekod dengan URL, status, kandungan dalam format pilihan anda, dan metadata asas (kod status HTTP, tajuk halaman, URL akhir selepas ubah hala). Dengan render: true, anda juga mendapat tag Open Graph. Respons juga termasuk browserSecondsUsed untuk keterlihatan bil, dan cursor untuk penomboran keputusan yang melebihi 10 MB.
Berikut ialah respons peringkat tugas sebenar daripada rangkakan 24 halaman yang dirender bagi kedai Shopify langsung:
{
"job_id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890",
"status": "completed",
"total": 24,
"finished": 24,
"browserSecondsUsed": 58.38,
"record_count": 24,
"records": [
{
"url": "https://www.example-store.com/products/premium-widget-bundle",
"status": "completed",
"metadata": {
"status": 200,
"title": "Premium Widget Bundle | Example Store",
"url": "https://www.example-store.com/products/premium-widget-bundle",
"lastModified": "",
"og:type": "product",
"og:site_name": "Example Store",
"og:title": "Premium Widget Bundle | Example Store",
"og:image": "https://www.example-store.com/cdn/shop/files/product-image.jpg",
"og:description": "Our best-selling bundle with everything you need..."
},
"markdown": "Store\n\nexample-store\n\nURL\n\nhttps://www.example-store.com\n\nCurrency\n\nUSD\n\n# Premium Widget Bundle\n\nOur best-selling bundle with everything you need..."
}
]
}
Dengan render: true, objek metadata termasuk set penuh medan Open Graph: jenis, nama laman, tajuk, URL imej, dan penerangan. Ini ditarik daripada tag meta OG halaman semasa render pelayar. Dengan render: false, metadata hanya mengandungi kod status HTTP, tajuk halaman, dan URL akhir. Tiada medan Open Graph diekstrak.
Medan markdown mengandungi keseluruhan output halaman, bukan hanya kandungan utama. Menu navigasi, menu mega, pengaki, dan blok templat berulang semuanya disertakan dalam setiap rekod. Dalam ujian kami, purata halaman mengembalikan kira-kira 158 KB markdown, dengan kira-kira 90% daripadanya adalah boilerplate berulang. Jika anda menyuapkan ini ke dalam LLM atau saluran RAG, anda memerlukan logik pengekstrakan kandungan anda sendiri untuk melucutkan templat dan mengasingkan kandungan halaman sebenar.
Berikut ialah apa yang kedai sama kembalikan apabila kami menjalankan render: false:
{
"job_id": "f9e8d7c6-b5a4-3210-fedc-ba9876543210",
"status": "completed",
"total": 266,
"finished": 266,
"browserSecondsUsed": 0,
"record_count": 256,
"records": [
{
"url": "https://www.example-store.com/products/classic-knit-sweater",
"status": "completed",
"metadata": {
"status": 200,
"title": "Classic Knit Sweater | Example Store",
"url": "https://www.example-store.com/products/classic-knit-sweater",
"lastModified": ""
},
"markdown": "Skip to content\n\nFree Shipping $150+\n\n# Classic Knit Sweater\n\nOur best-selling sweater made from premium natural fibers..."
}
]
}
Sifar saat pelayar, 256 rekod daripada 266 halaman. Metadata adalah minimal berbanding versi yang dirender: tiada medan Open Graph, hanya status HTTP, tajuk halaman, dan URL. Tetapi markdown masih mengandungi kandungan halaman penuh termasuk navigasi, butiran produk, dan pengaki. Untuk kedai Shopify yang dirender pelayan, HTML statik sudah mempunyai segala yang anda perlukan.
Penemuan URL
Perangkak menemui URL melalui tiga sumber (apabila source ditetapkan kepada all):
- URL permulaan yang anda berikan
- Pautan peta laman yang ditemui pada domain
- Pautan dalaman yang ditemui pada halaman yang dirangkak
Anda boleh menghadkan ini kepada peta laman sahaja atau pautan halaman sahaja menggunakan parameter source. excludePatterns sentiasa diutamakan berbanding includePatterns, jadi anda boleh membuat jaring luas dan kemudian memotong bahagian yang anda tidak perlukan.
Rendering vs. Ambilan Pantas
render: true (lalai) menjalankan pelayar tanpa kepala, melaksanakan JavaScript, dan menunggu halaman dimuatkan sepenuhnya. Ini diperlukan untuk aplikasi halaman tunggal dan kandungan yang dirender JavaScript, tetapi ia menggunakan saat pelayar yang dibilkan.
render: false melakukan ambilan HTML pantas tanpa melaksanakan JavaScript. Semasa beta, ambilan ini tidak dibilkan. Ini adalah pilihan yang tepat untuk laman statik atau halaman yang dirender pelayan di mana kandungan sudah ada dalam HTML awal.
Pengebilan dan Ketersediaan
Endpoint ini tersedia pada kedua-dua pelan Workers Free dan Paid. Rangkakan yang dirender dibilkan di bawah harga Browser Rendering Cloudflare pada $0.09 setiap jam pelayar melebihi peruntukan yang disertakan.
Workers Free: 10 minit masa pelayar sehari. Endpoint /crawl dihadkan kepada 5 tugas sehari, 100 halaman setiap rangkak, dan 6 permintaan API seminit.
Workers Paid ($5/bulan): 10 jam masa pelayar sebulan disertakan. Tiada had halaman setiap rangkak. 600 permintaan API seminit. Jam pelayar tambahan berharga $0.09 setiap satu.
Rangkakan render: false menggunakan sifar masa pelayar. Ia percuma semasa beta tetapi akhirnya akan berada di bawah harga standard Workers.
Apakah Masa Jam Dinding?
Masa jam dinding ialah jumlah masa berlalu dari apabila rangkakan bermula sehingga ia selesai, diukur dengan cara yang sama seperti anda menentukan masa dengan jam randik. Ia merangkumi segala-galanya: kependaman rangkaian, masa giliran dalaman Cloudflare, carian DNS, masa respons pelayan, dan (jika rendering diaktifkan) masa pelaksanaan pelayar.
Masa jam dinding berbeza daripada masa pelayar. Masa pelayar hanya mengira saat pelayar tanpa kepala Cloudflare menghabiskan masa secara aktif merender halaman. Rangkakan mungkin menggunakan 22 minit masa pelayar tetapi mengambil 25 minit masa jam dinding kerana giliran dan overhed rangkaian. Rangkakan tanpa rendering menggunakan sifar masa pelayar tetapi masih mempunyai masa jam dinding daripada proses ambil dan giliran.
Dalam penanda aras kami, kami melaporkan kedua-dua nombor supaya anda boleh melihat apa yang anda bayar (masa pelayar) berbanding berapa lama anda sebenarnya menunggu (masa jam dinding).
Butiran Terperinci
Endpoint ini menghormati arahan robots.txt termasuk crawl-delay. Ia mengenal pasti dirinya sebagai CloudflareBrowserRenderingCrawler/1.0. Ia tidak memintas CAPTCHA, cabaran Turnstile, atau perlindungan bot lain. Jika anda merangkak laman anda sendiri dan disekat, anda perlu mencipta peraturan langkau WAF untuk menyenaraikan perangkak dalam senarai dibenarkan.
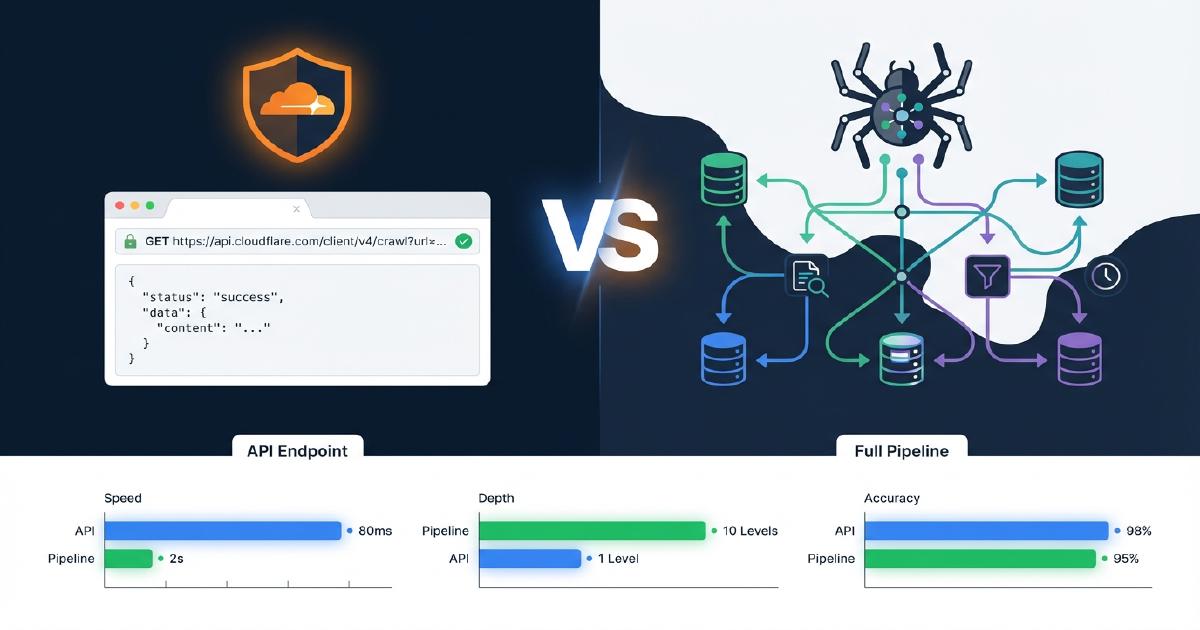
Bagaimana Cloudflare /crawl Berkelakuan Merentasi Lima Kedai Shopify
Kami menjalankan endpoint /crawl terhadap lima kedai Shopify langsung untuk mengukur kelajuan, kadar kejayaan, kos, dan bagaimana perangkak berinteraksi dengan setiap kedai. Setiap nama kedai dianonimkan. Ini adalah nombor sebenar daripada rangkakan sebenar. Masa jam dinding adalah anggaran lebih kurang. Sesetengah ujian awal menggunakan skrip dengan pengendalian ralat terhad, yang mungkin mempengaruhi kadar kejayaan yang dilaporkan pada kedai tertentu. Di mana ini berlaku, kami nyatakan di bawah.
Ini bukan endpoint yang boleh ditetapkan dan dilupakan. Setiap kedai bertindak balas secara berbeza terhadap permintaan endpoint. Sesetengah memerlukan penyekatan sumber untuk menyelesaikan rangkakan yang dirender. Yang lain mengembalikan ralat 429 pada satu mod tetapi berfungsi dengan baik pada yang lain. Arahan crawl-delay, bilangan halaman, dan seni bina kedai semuanya mengubah keputusan. Rancang untuk menguji dan menala tetapan bagi setiap laman yang anda rangkak.
Ujian 1: Katalog E-Dagang Besar (Store A)
Kami menghala endpoint /crawl ke kedai Shopify besar dengan hampir 3,000 halaman. Kandungan kembali dengan pantas, markdown boleh digunakan, dan endpoint tidak mempunyai masalah mengambil halaman produk, halaman koleksi, dan kandungan blog. Tiada masalah proksi, tiada sekatan, tiada pengehadan kadar.
Kami menjalankan beberapa rangkakan pada skala berbeza:
| Saiz Rangkak | Halaman Dikembalikan | Mod | Masa Pelayar | Masa Jam Dinding |
|---|---|---|---|---|
| Sampel 20 halaman | 20 / 20 (100%) | tanpa render | 0s | ~1 min |
| Rangkakan 500 halaman | 500 / 500 (100%) | tanpa render | 0s | ~18 min |
| 5 halaman dirender | 4 / 5 (80%) | render: true | 0.9s | ~10s |
Rangkakan tanpa rendering JavaScript mencapai 100% kejayaan pada kedua-dua skala. Rendering pelayar penuh mengembalikan 4 daripada 5 halaman dalam ujian sampel kecil. Pada sampel sekecil itu, satu halaman yang hilang boleh jadi tamat masa pelayar, ralat sementara, atau isu skrip.
Ujian 2: Kedai Shopify Kecil (Store D, 24 halaman)
Sebuah kedai yang lebih kecil di mana kami menguji aliran kerja penuh:
Rangkakan tanpa rendering mengembalikan ralat. Ujian awal kami mengembalikan respons 429 pada ambilan HTML biasa. Kami belum menguji semula kedai ini dengan pengendalian ralat yang lebih baik, jadi kami tidak dapat mengesahkan sama ada 429 tersebut berasal daripada pengehadan kadar kedai atau daripada isu sementara semasa ujian.
Rendering penuh dengan penemuan berasaskan peta laman adalah kejayaan sepenuhnya. 24 daripada 24 halaman dirangkak, 100% penyelesaian.
| Jenis Halaman | Bilangan |
|---|---|
| Produk | 9 |
| Koleksi | 4 |
| Halaman | 3 |
| Blog/Berita | 5 |
| Lain-lain (laman utama, indeks blog) | 3 |
Satu penemuan penting: mod penemuan URL lalai hanya menemui 1 halaman kerana laman utama mempunyai hampir tiada pautan dalaman. Bertukar kepada penemuan berasaskan peta laman menemui semua 24. Jika laman utama anda adalah minimalis atau berat JavaScript, perangkak mungkin tidak menemui halaman melalui pautan sahaja.
Ujian 3: Kedai Pakaian Sederhana (Store B, 256 halaman), Dengan dan Tanpa Rendering
Ujian kami yang paling terperinci. Sebuah kedai pakaian sederhana dengan 256 halaman boleh indeks: produk, koleksi, catatan blog, dan halaman maklumat. Kami menjalankan kedua-dua mod pada keseluruhan laman untuk mengukur perbezaan sebenar.
| Metrik | render: false | render: true | Perbezaan |
|---|---|---|---|
| Halaman dirangkak | 256 / 266 | 256 / 266 | Sama |
| Jumlah output markdown | 11.0 MB | 12.5 MB | +14% |
| Masa pelayar | 0s | 1,338s (22 min) | +22 min |
| Anggaran kos | $0 (beta) | ~$0.03 | +$0.03 |
| Masa jam dinding | ~5 min | ~25 min | 5x lebih perlahan |
Ujian 4: Peruncit Kesihatan & Suplemen (Store C), Kejayaan Separa pada Skala
Sebuah peruncit produk kesihatan besar dengan katalog yang besar. Kami menjalankan dua rangkakan tanpa rendering pada skala berbeza:
| Saiz Rangkak | Halaman Dikembalikan | Kadar Kejayaan | Masa Jam Dinding |
|---|---|---|---|
| Sampel 5 halaman | 2 / 5 | 40% | ~25s |
| Rangkakan 100 halaman | 89 / 100 | 89% | ~3.5 min |
Kadar kejayaan separa boleh menunjukkan bahawa infrastruktur kedai ini menggugurkan sesetengah permintaan bukan pelayar, tetapi ujian awal kami kekurangan pemulihan ralat yang teguh, jadi sesetengah kegagalan ini mungkin boleh dipulihkan dengan pengendalian cuba semula yang lebih baik di pihak kami. Kadar kejayaan meningkat daripada 40% kepada 89% pada skala yang lebih besar. Kami belum menguji semula kedai ini dengan pengendalian ralat yang lebih baik untuk mengasingkan punca.
Ujian 5: Kedai Pelbagai Kategori Besar (Store E, ~1,200 halaman)
Ujian kami yang terbesar dan paling mendedahkan. Sebuah kedai Shopify dengan kira-kira 1,200 URL yang diedarkan merentasi empat peta laman: 521 produk, 626 koleksi, 22 halaman, dan 31 catatan blog.
| Metrik | render: false | render: true (dioptimumkan) |
|---|---|---|
| Halaman dirangkak | 1,200 / 1,200 | 100 / 100 |
| Jumlah output markdown | 148.5 MB | 11.3 MB |
| Masa pelayar | 0s | 475s (~8 min) |
| Anggaran kos | $0 (beta) | ~$0.012 |
| Masa jam dinding | ~55 min | ~12 min |
Rangkakan tanpa render mencapai 100% kejayaan merentasi semua 1,200 halaman dengan sifar kos pelayar. Rangkakan yang dirender dijalankan pada sampel 100 halaman dengan pengoptimuman penyekatan sumber diaktifkan.
Penyekatan sumber membuat perbezaan antara rangkakan yang tersekat dan rangkakan yang bersih. Tanpa menyekat sumber, rangkakan yang dirender tersekat pada 99 daripada 100 halaman selama-lamanya dan menggunakan 649 saat masa pelayar untuk 99 halaman tersebut. Mengaktifkan penyekatan sumber (imej, media, fon, lembaran gaya) dengan syarat tunggu domcontentloaded menyelesaikan semua 100 halaman dalam 475 saat, pengurangan 27% dalam masa pelayar tanpa sebarang tersekat.
Crawl-delay dalam robots.txt mencipta kesesakan yang ketara. robots.txt Store E menentukan crawl-delay 10 saat untuk bot tertentu. Dalam data tinjauan tanpa render kami, ini muncul sebagai dataran pelbagai minit di mana kiraan halaman terhenti sebelum menyambung semula. Perangkak Cloudflare menghormati arahan crawl-delay, yang secara langsung memanjangkan masa jam dinding pada laman yang menetapkannya.
Apa yang Endpoint /crawl Sebenarnya Terima
Endpoint ini menerima satu URL permulaan, bukan senarai. Ia menemui halaman dengan merangkak keluar dari URL tersebut melalui peta laman, pautan halaman, atau kedua-duanya. Jika anda sudah mempunyai senarai URL daripada rangkakan Scrapy dan mahu menggunakan Cloudflare untuk penukaran markdown, anda perlu memanggil endpoint /markdown atau /scrape yang berasingan secara individu bagi setiap URL.
Apa yang Cloudflare /crawl Sebenarnya Lakukan di Bahagian Pelayan?
Kami menarik log pelayan penuh semasa rangkakan yang dirender sepenuhnya bagi Store D (25 halaman) untuk menganalisis jejak trafik sebenar. Keputusan mendedahkan perbezaan asas antara rangkakan yang dirender pelayar dan rangkakan bot tradisional, dengan kesan sampingan yang tidak dijangka untuk analitik, beban pelayan, dan pemantauan trafik bot.
| Metrik | Nilai |
|---|---|
| User-Agent | CloudflareBrowserRenderingCrawler/1.0 (100% daripada hits) |
| Tetingkap rangkak | 134 saat (~2 minit) |
| Daya pemprosesan puncak | 82 permintaan/saat |
| IP Unik | 23, merentasi 5 pusat data Cloudflare |
| Permintaan GET | 2,071 |
| Permintaan POST | 163 |
| Jumlah permintaan | 2,234 |
| Halaman sebenar dirender | ~25 |
| Permintaan setiap halaman | ~89x penggandaan |
Berapa Banyak Trafik yang Sebenarnya Dijana oleh Rangkakan Cloudflare /crawl yang Dirender Sepenuhnya?
Penemuan terbesar: hanya 1.1% daripada 2,234 permintaan adalah kandungan halaman sebenar. 98.9% yang lain adalah JavaScript, CSS, beacon analitik, piksel penjejak, dan pramuat checkout yang dicetuskan oleh pelayar yang memuatkan setiap halaman seperti pelawat sebenar.
Bot yang tidak dirender seperti Amazonbot atau ChatGPT-User menjana 1 permintaan setiap halaman. Pelayar renderer Cloudflare menjana 89.
Adakah Cloudflare /crawl Menginflasikan Analitik Shopify?
163 permintaan POST dalam log kami adalah sepenuhnya endpoint analitik dan penjejakan Shopify yang dicetuskan semasa rangkakan. Ini adalah peristiwa yang sama yang dicetuskan apabila pelanggan sebenar melawat kedai anda. Dari perspektif Shopify Analytics, perangkak Cloudflare kelihatan seperti pelawat yang melayari setiap halaman di kedai anda dalam 2 minit.
Seberapa Pantas Cloudflare /crawl Memukul Pelayan Anda?
Semua 2,234 permintaan mendarat dalam tetingkap 134 saat. Daya pemprosesan puncak mencapai 82 permintaan sesaat. Perangkak merender keseluruhan laman 25 halaman dalam hanya lebih 2 minit, tetapi pelayan melihat letupan trafik berterusan yang tidak kelihatan seperti corak pelayaran organik langsung.
Untuk kedai kecil, ini boleh diurus. Untuk kedai yang lebih besar dengan beribu-ribu halaman, penggandaan permintaan (89x setiap halaman) digabungkan dengan daya pemprosesan berterusan boleh mencipta beban yang bermakna pada pelayan asal, terutamanya jika anda berada pada pelan hosting berkongsi atau mempunyai pengehadan kadar yang agresif.
Dari Mana Cloudflare /crawl Datang?
Rangkakan diedarkan merentasi 5 pusat data Cloudflare di AS:
| Pusat Data | % Permintaan | Lokasi |
|---|---|---|
| ATL | 38% | Atlanta |
| ORD | 25% | Chicago |
| MIA | 23% | Miami |
| EWR | 9% | Newark |
| IAD | 5% | Washington DC |
Ini bukan satu pelayan yang membuat permintaan. Cloudflare mengedarkan beban kerja rendering merentasi rangkaian tepinya. Semua 23 IP berada dalam julat 104.28.x.x, dan ejen pengguna adalah CloudflareBrowserRenderingCrawler/1.0 pada setiap permintaan.
Apakah Cap Jari Pelayar yang Ditinggalkan oleh Cloudflare /crawl?
Renderer menghantar pengepala Sec-Fetch yang betul yang meniru pelayar Chrome sebenar:
| Pengepala | Nilai | Chrome Sebenar? |
|---|---|---|
sec-fetch-dest |
script, document, dll. |
Ya, sepadan |
sec-fetch-mode |
cors, navigate |
Ya, sepadan |
sec-fetch-site |
same-origin, cross-site |
Ya, sepadan |
sec-ch-ua (Client Hints) |
Tidak dihantar | Tidak, Chrome sebenar menghantar ini |
| Versi HTTP | HTTP/1.1 | Tidak, Chrome sebenar berunding HTTP/2 atau HTTP/3 |
Dua jurang cap jari menonjol: renderer tidak menghantar pengepala Client Hints sec-ch-ua langsung (pelayar Chrome sebenar sentiasa menghantar ini), dan semua permintaan menggunakan HTTP/1.1 dan bukannya HTTP/2 atau HTTP/3. Jika anda membina peraturan pengesanan bot, ini adalah isyarat yang boleh dipercayai untuk membezakan renderer pelayar Cloudflare daripada trafik pelawat sebenar.
Bagaimana Cloudflare /crawl Berbanding dengan Bot AI Lain dalam Log Pelayan?
Kami membandingkan rangkakan Cloudflare dengan bot lain yang memukul kedai yang sama dalam tetingkap 12 jam yang sama:
Amazonbot dan ChatGPT-User mengambil HTML mentah: satu permintaan, satu halaman, tiada pelaksanaan JavaScript. AhrefsBot merangkak peta laman untuk penemuan. Pelayar renderer Cloudflare melaksanakan kedai Shopify penuh pada setiap halaman, mencetuskan setiap skrip, piksel, dan pramuat seolah-olah pelanggan sebenar sedang melayari.
Kelajuan dan Kos Cloudflare /crawl: Penanda Aras Penuh
Setiap rangkakan yang kami jalankan, dalam satu jadual. Semua kedai dianonimkan, semua nombor daripada ujian sebenar. Masa jam dinding adalah lebih kurang. Kadar kejayaan untuk Store C dan D mungkin telah terjejas oleh pengendalian ralat terhad dalam skrip ujian awal kami.
| Kedai | Halaman | Mod | Kadar Kejayaan | Masa Pelayar | Masa Jam Dinding | Kos |
|---|---|---|---|---|---|---|
| A: E-Dagang Besar | 500 / 500 | tanpa render | 100% | 0s | ~18 min | $0 |
| B: Pakaian Sederhana | 256 / 266 | tanpa render | 96% | 0s | ~5 min | $0 |
| C: Kesihatan & Suplemen | 89 / 100 | tanpa render | 89% | 0s | ~3.5 min | $0 |
| D: Kedai Kecil Shopify | 24 / 24 | render: true | 100% | 58s | ~2 min | ~$0.002 |
| E: Pelbagai Kategori Besar | 1,200 / 1,200 | tanpa render | 100% | 0s | ~55 min | $0 |
Seberapa Pantas Cloudflare /crawl Dengan vs. Tanpa Rendering?
Perbandingan paling jelas datang daripada Store B, di mana kami menjalankan kedua-dua mod pada 256 halaman yang sama:
Corak merentasi semua sebelas rangkakan adalah konsisten: rangkakan tanpa rendering jauh lebih pantas. Masa jam dinding tanpa rendering kebanyakannya adalah overhed giliran dan ambilan dalaman Cloudflare. Rendering penuh menambah kira-kira 5 saat masa pelayar setiap halaman di atas garis dasar tersebut.
Berapakah Kos Rangkakan Cloudflare yang Dirender Sepenuhnya Setiap Halaman?
Harga Browser Rendering Cloudflare berdasarkan jam pelayar, masa yang dihabiskan pelayar tanpa kepala mereka secara aktif merender halaman anda. Rangkakan tanpa rendering menggunakan sifar jam pelayar dan percuma semasa beta.
Pelan Workers Free: 10 minit masa pelayar sehari. Endpoint /crawl dihadkan lagi kepada 5 tugas rangkak sehari, dengan maksimum 100 halaman setiap rangkak.
Pelan Workers Paid ($5/bulan): 10 jam masa pelayar sebulan disertakan. Melebihi itu, anda membayar $0.09 setiap jam pelayar tambahan. Tiada had setiap rangkak pada endpoint /crawl. Sehingga 600 permintaan API seminit.
Berikut ialah kos sebenar rangkakan ujian kami pada kadar $0.09/jam:
| Rangkakan | Masa Pelayar Digunakan | Kos pada $0.09/jam |
|---|---|---|
| Store D: 24 halaman dirender | 58 saat | ~$0.002 |
| Store B: 256 halaman dirender | 1,338 saat (~22 min) | ~$0.03 |
| Katalog 3,000 halaman (anggaran) | ~4 jam | ~$0.36 |
Pada kira-kira 5 saat masa pelayar setiap halaman, semua kos ini berada dalam 10 jam yang disertakan pada pelan berbayar. Rangkakan 3,000 halaman yang dirender akan menggunakan kira-kira 4 daripada 10 jam yang disertakan, bermakna anda boleh menjalankan dua rangkakan penuh sebulan sebelum membayar apa-apa melebihi asas $5. Rangkakan tanpa rendering adalah percuma dan tiada kos masa pelayar pada kedua-dua pelan.
Bilakah Anda Patut Melangkau Rendering vs. Menggunakan Rendering Penuh pada Cloudflare /crawl?
Kesimpulan
Untuk kebanyakan kedai Shopify dengan kandungan yang dirender pelayan, rangkakan tanpa rendering mendapatkan lebih 90% kandungan berguna pada kos sifar dalam sebahagian kecil masa.
Apa yang Kami Pelajari daripada Menguji Cloudflare /crawl pada Kedai Shopify
Selepas menjalankan 11 rangkakan merentasi 5 kedai Shopify langsung dan menganalisis log pelayan penuh, ini adalah penemuan yang paling penting.
90% Kandungan Datang Tanpa Rendering
Untuk kedai Shopify dengan halaman standard yang dirender pelayan, rangkakan tanpa rendering JavaScript menangkap lebih 90% kandungan berguna. Peningkatan kandungan 14% daripada rendering penuh datang hampir keseluruhannya daripada elemen yang dimuatkan JavaScript pada laman utama dan halaman indeks. Halaman produk individu dan artikel blog hampir sama. Melainkan kedai anda dibina sebagai aplikasi halaman tunggal, anda mungkin tidak memerlukan rendering penuh.
Rendering Penuh Mencipta Pengganda Trafik 89x
Merender 25 halaman menjana 2,234 permintaan pelayan. Hanya 25 daripadanya adalah kandungan halaman sebenar. 98.9% yang lain adalah fail JavaScript (75%), beacon analitik (6.3%), CSS (4.3%), piksel penjejak (3.4%), dan pramuat checkout (3.3%). Setiap halaman yang dirender mencetuskan timbunan bahagian klien Shopify sepenuhnya seolah-olah pelanggan sebenar sedang melayari.
Analitik Shopify Anda Berkemungkinan Diinflasikan
Rangkakan yang dirender mencetuskan timbunan analitik penuh Shopify: beacon monorail, peristiwa penjejakan, pramuat Shop Pay, dan skrip web-pixel. Kami percaya ini bermakna Shopify Analytics mengira ini sebagai sesi pelawat sebenar. Jika itu benar, satu rangkakan yang dirender boleh menginflasikan kiraan sesi, paparan halaman, dan data corong penukaran anda. Kami belum mengesahkan ini secara langsung dalam pelaporan Shopify, tetapi log pelayan menunjukkan semua peristiwa analitik yang sama dicetuskan seperti yang berlaku untuk pelanggan sebenar.
Rendering Penuh Boleh Memintas Had Kadar Kedai
Store D mengembalikan ralat 429 pada setiap halaman tanpa rendering. Bertukar kepada rendering penuh pada kedai yang sama menghasilkan 100% kejayaan. Jika anda menghadapi had kadar tanpa rendering, rendering penuh adalah penyelesaian anda.
Penemuan Peta Laman Lebih Boleh Dipercayai Berbanding Penemuan Pautan
Penemuan berasaskan pautan lalai hampir tidak menemui apa-apa pada Store D kerana laman utama mempunyai sangat sedikit pautan dalaman. Bertukar kepada penemuan berasaskan peta laman menemui semua 24 halaman. Sentiasa gunakan penemuan peta laman.
Perangkak Datang daripada 5 Pusat Data AS
Cloudflare mengedarkan beban kerja rendering merentasi rangkaian tepinya. Rangkakan kami datang daripada 23 IP unik merentasi Atlanta (38%), Chicago (25%), Miami (23%), Newark (9%), dan Washington DC (5%). Semua IP berada dalam julat 104.28.x.x.
Dua Jurang Cap Jari Mengenal Pastinya sebagai Bot
Renderer tidak menghantar pengepala Client Hints sec-ch-ua (Chrome sebenar sentiasa menghantar ini) dan menggunakan HTTP/1.1 dan bukannya HTTP/2 atau HTTP/3. Jika anda membina peraturan pengesanan bot, ini adalah isyarat yang boleh dipercayai.
Rendering Sebenarnya Boleh Mengembalikan Kurang Kandungan
Pada Store E, rangkakan tanpa render mengembalikan 6.8% lebih kandungan setiap halaman berbanding rangkakan yang dirender. Menyekat imej, fon, dan lembaran gaya untuk mengoptimumkan masa pelayar juga menghalang sesetengah JavaScript daripada mengisi elemen dinamik. HTML statik sudah mempunyai segalanya. Untuk kedai Shopify yang dirender pelayan, rendering tidak dijamin menangkap lebih banyak kandungan.
Penyekatan Sumber Mencegah Rangkakan Tersekat
Tanpa penyekatan sumber, rangkakan yang dirender pada Store E tersekat pada 99 daripada 100 halaman dan tidak pernah selesai. Mengaktifkan penyekatan untuk imej, media, fon, dan lembaran gaya dengan syarat tunggu domcontentloaded menyelesaikan semua 100 halaman dan mengurangkan masa pelayar sebanyak 27%. Jika rangkakan yang dirender anda berhenti sebelum selesai, penyekatan sumber adalah penyelesaiannya.
robots.txt Crawl-Delay Memanjangkan Masa Jam Dinding
robots.txt Store E menentukan crawl-delay 10 saat. Dalam data tinjauan tanpa render kami, ini muncul sebagai dataran pelbagai minit di mana kiraan halaman terhenti sebelum menyambung semula. Perangkak Cloudflare menghormati arahan crawl-delay, jadi laman dengan kelewatan agresif akan mempunyai masa jam dinding yang jauh lebih panjang daripada yang dicadangkan oleh bilangan halaman sahaja.
Kos Rendah Tetapi Pelan Percuma Mempunyai Had
Merender 256 halaman menelan kos kira-kira $0.03 pada kadar $0.09 setiap jam pelayar. Merender 24 halaman menelan kos kira-kira $0.002. Pelan Workers Free mengehadkan masa pelayar pada 10 minit sehari dengan maksimum 5 tugas rangkak dan 100 halaman setiap rangkak. Pelan Workers Paid ($5/bulan) termasuk 10 jam masa pelayar sebulan tanpa had setiap rangkak. Rangkakan 3,000 halaman yang dirender akan menggunakan kira-kira 4 daripada 10 jam yang disertakan, jadi kebanyakan kedai selesa pada pelan berbayar tanpa lebihan. Rangkakan tanpa rendering menggunakan sifar masa pelayar dan percuma pada kedua-dua pelan semasa beta.
Kelebihan
Kelajuan
Halaman diambil hampir serta-merta berbanding rangkakan Scrapy berbilang jam dengan autothrottle. Tiada beratur, tiada kelewatan kesopanan, tiada menunggu spider anda bekerja melalui beribu-ribu permintaan pada kadar yang sopan.
Output Markdown
Endpoint mengembalikan HTML-ke-Markdown yang telah ditukar untuk setiap halaman. Ini berguna secara langsung untuk pengambilan LLM, saluran RAG, dan analisis kandungan tanpa sebarang pasca pemprosesan. Anda melangkau keseluruhan lapisan pengekstrakan dan terus kepada teks bersih. Untuk pasukan yang membina aplikasi AI di atas kandungan laman web, ini menghapuskan satu langkah daripada saluran.
Pilihan Mod Render
Menetapkan render: true melaksanakan JavaScript dan mengekstrak metadata Open Graph secara automatik (og:title, og:description, og:image, og:site_name). Untuk laman berat JavaScript di mana kandungan dirender bahagian klien, ini adalah perbezaan antara melihat halaman sebenar dan melihat kerangka kosong.
Tiada Masalah Proksi atau Had Kadar
Cloudflare mengendalikan langkah anti-bot dan pengehadan kadar pada infrastruktur mereka sendiri. Anda tidak perlu menguruskan kolam proksi, memutar ejen pengguna, atau menangani CAPTCHA. Satu panggilan API.
Rangkakan Bertambah
Parameter modifiedSince dan maxAge membolehkan anda melangkau halaman yang tidak berubah atau baru diambil. Untuk rangkakan berulang di mana anda memantau perubahan kandungan, ini menjimatkan masa dan kos dengan hanya memproses halaman yang benar-benar baharu atau dikemas kini.
Kesederhanaan
Satu panggilan API. Respons JSON. Tiada kod spider, tiada middleware, tiada saluran item, tiada fail tetapan.
Bot yang Berkelakuan Baik secara Lalai
Perangkak adalah ejen bertandatangan yang menghormati robots.txt, crawl-delay, dan Kawalan Rangkak AI Cloudflare. Ia mengenal pasti dirinya sebagai CloudflareBrowserRenderingCrawler/1.0 dan tidak boleh memintas perlindungan bot atau CAPTCHA. Anda mendapat pematuhan rangkakan beretika tanpa membina logik sendiri.
Apa yang Tidak Disokong oleh Endpoint Cloudflare Crawl
Bagaimanakah Cloudflare /crawl Berbeza daripada Saluran Rangkak Penuh?
Jadual di bawah menunjukkan dengan tepat keupayaan mana yang ada dalam endpoint /crawl Cloudflare berbanding saluran Scrapy pengeluaran. Ini berdasarkan ujian sebenar kami terhadap kedai Shopify.
| Keupayaan | Cloudflare /crawl | Saluran Scrapy |
|---|---|---|
| Pengambilan kandungan (HTML/Markdown) | Ya | Ya |
| Rendering JavaScript | Ya (render: true) |
Ya (Splash/Playwright) |
| Penemuan pautan / rangkakan | Ya (senarai rata) | Ya (graf rangkak penuh) |
| Pemetaan pautan ibu bapa-anak | Tidak | Ya |
| Pengesanan halaman yatim | Tidak | Ya |
| Penjejakan rantai ubah hala | Tidak | Ya |
| Pengekstrakan JSON-LD | Tidak | Ya |
| Pengekstrakan Microdata | Tidak | Ya |
| Pengesahan skema + pelaporan isu | Tidak | Ya |
| Kod status bukan 200 (404, 403) | Tidak | Ya (menangkap 2,547 404 dalam ujian kami) |
| Had URL | 100,000 | Tiada |
Apakah Data Berstruktur yang Diekstrak oleh Cloudflare /crawl?
Dengan render: false, tiada. Tiada JSON-LD, tiada Microdata, tiada penghuraian OpenGraph.
Dengan render: true, tag OG asas sahaja (og:title, og:description, og:image, og:site_name). JSON-LD dan markup schema.org tidak dihurai, diekstrak, atau disahkan.
Sebagai perbandingan, saluran Scrapy kami menghasilkan schemas_found, issues (contactPoint hilang, address, dll.), top_level_schemas, dan nested_schemas untuk setiap URL. Anda boleh melihat halaman mana yang mempunyai skema Product, mana yang kekurangan markup Organization, dan mana yang mempunyai ralat pengesahan yang akan menyebabkan sistem AI salah membaca kandungan.
Kod Status HTTP Manakah yang Dikembalikan oleh Cloudflare /crawl?
Hanya respons 200. Rangkakan Scrapy kami terhadap laman yang sama menangkap 2,547 ralat 404, serta respons 403 dan ralat sambungan. Pengesanan 404 adalah kritikal untuk analisis halaman hantu, pembaikan pautan rosak, dan pemetaan ubah hala. Tanpanya, anda kehilangan halaman yang secara aktif membocorkan ekuiti pautan dan mengelirukan perangkak AI.
Berapa Banyak URL yang Boleh Diproses oleh Cloudflare /crawl?
Sehingga 100,000 setiap tugas. Ini meliputi kebanyakan laman, tetapi katalog e-dagang besar dengan ratusan ribu halaman produk, URL varian, dan halaman koleksi bertapis akan melebihi had. Scrapy tidak mempunyai had URL sedia ada.
Adakah Cloudflare /crawl Mempunyai Pepijat Resolusi URL?
Kami menemui 233 daripada 908 pautan pada satu halaman produk mempunyai laluan rosak. Penukar markdown menyelesaikan URL relatif terhadap URL halaman secara tidak betul, menghasilkan URL laluan berganda seperti /products/slug//www.example.com/.... Ini adalah pepijat yang disahkan dalam penukar Cloudflare yang mempengaruhi mana-mana analisis pautan hiliran.
Berapa Banyak Boilerplate dalam Output Markdown Cloudflare /crawl?
Purata halaman mengembalikan 158 KB markdown. Kira-kira 90% adalah kandungan templat berulang: navigasi penuh, menu mega, dan pengaki pada setiap rekod. Untuk analisis kandungan ini bermakna kerja penyahduplikasian yang berat, dan untuk penggunaan token LLM kos bertambah dengan cepat. Anda memerlukan logik pengekstrakan kandungan anda sendiri di atas markdown untuk mengasingkan kandungan halaman sebenar.
Apa yang Cloudflare /crawl Tidak Kelaskan?
Tiada penandaan jenis kandungan. Halaman produk, halaman koleksi, catatan blog, dan laman utama semuanya kembali sebagai rekod yang tidak dibezakan. Scrapy mengelaskan setiap URL mengikut jenis, yang penting untuk memahami liputan rangkakan mengikut kategori halaman dan untuk mengenal pasti jenis kandungan yang diutamakan oleh bot AI.
Ciri Finalisasi Apa yang Tiada daripada Cloudflare /crawl?
Tiada tangkapan skrin halaman hantu. Tiada perbandingan rendering JavaScript (apa yang dilihat bot berbanding apa yang dilihat pelayar). Tiada analisis bot AI robots.txt. Tiada laporan kualiti rangkakan. Tiada manifes klien. Tiada penyegerakan CDN. Data Cloudflare adalah kandungan mentah sahaja. Setiap bahagian saluran pelaporan dan analisis perlu dibina secara berasingan.
Berapakah Kos Cloudflare /crawl untuk Laman Besar?
Merentasi ujian kami, render: true secara purata kira-kira 5 saat pelaksanaan pelayar setiap halaman. Rangkakan 256 halaman menggunakan 1,338 saat pelayar (22 minit) dan menelan kos kira-kira $0.03 pada kadar $0.09 setiap jam pelayar. Rangkakan 24 halaman menggunakan 58 saat pelayar dan menelan kos kira-kira $0.002. Ekstrapolasi kepada katalog 3,000 halaman: kira-kira 4 jam masa pelayar. Pelan Workers Free dihadkan pada 10 minit masa pelayar sehari, 5 tugas rangkak sehari, dan 100 halaman setiap rangkak. Pelan Workers Paid ($5/bulan) termasuk 10 jam masa pelayar sebulan tanpa had setiap rangkak, jadi rangkakan 3,000 halaman akan menggunakan kira-kira 4 daripada 10 jam yang disertakan. render: false menggunakan sifar masa pelayar dan percuma semasa beta pada kedua-dua pelan.
Kesimpulan Akhir
Endpoint rangkak Cloudflare sangat baik untuk:
- Tangkapan kandungan pantas apabila anda memerlukan teks halaman dengan cepat
- Markdown sedia LLM untuk saluran RAG dan pengambilan kandungan
- Semakan halaman ad-hoc di mana anda tahu URL tepat yang anda perlukan
- Tarikan kandungan seluruh laman yang pantas apabila anda memerlukan teks markdown tanpa membina spider
Ia tidak boleh menggantikan saluran rangkak penuh kerana nilai saluran tersebut terletak pada:
- Graf rangkak penuh dengan topologi pautan, pengesanan yatim, dan liputan 404
- Pengekstrakan dan pengesahan data berstruktur (JSON-LD, Microdata, OpenGraph)
- Pengelasan kandungan mengikut jenis halaman
- Keseluruhan saluran finalisasi termasuk analisis halaman hantu, perbandingan rendering JavaScript, laporan skema, dan pemarkahan kesediaan LLM
Pendekatan Hibrid Terbaik
Gunakan Cloudflare sebagai sumber data pelengkap. Selepas rangkakan penuh mengenal pasti URL anda, gunakan output markdown Cloudflare untuk menyuap pemarkahan kesediaan LLM atau analisis kualiti kandungan di mana anda memerlukan teks halaman sebenar dan bukannya metadata berstruktur. Saluran rangkak menemui dan mengelaskan. Endpoint Cloudflare menyampaikan teks bersih untuk halaman yang penting.
Mahu melihat saluran rangkak penuh beraksi?
Jadualkan PanggilanSoalan Lazim
Ciri audit laman web manakah yang tidak disokong oleh Cloudflare /crawl?
Cloudflare /crawl tidak menyokong: pembinaan graf rangkak penuh, pemetaan pautan ibu bapa-anak, pengesanan halaman yatim, penjejakan rantai ubah hala, pengekstrakan JSON-LD atau Microdata, pengesahan skema, penangkapan kod status bukan 200 (404, 403), pengelasan jenis kandungan, pengukuran saiz bait halaman, pengesanan halaman hantu, perbandingan rendering JS vs HTML, analisis bot AI robots.txt, atau rujukan silang pautan balik. Ia adalah pengambil kandungan, bukan alat audit laman.
Bagaimanakah Cloudflare /crawl berbeza daripada Scrapy untuk rangkakan e-dagang?
Cloudflare /crawl mengambil kandungan dengan pantas tanpa infrastruktur untuk diurus. Scrapy membina graf rangkak lengkap dengan topologi pautan, mengekstrak dan mengesahkan data berstruktur (JSON-LD, Microdata, OpenGraph), menangkap semua kod status HTTP termasuk 404, mengelaskan halaman mengikut jenis kandungan, dan menyuap saluran hiliran untuk analisis halaman hantu, laporan skema, dan pemarkahan kesediaan LLM. Cloudflare memberi anda teks halaman; Scrapy memberi anda seni bina laman penuh.
Apakah had URL tepat untuk Cloudflare /crawl?
100,000 URL setiap tugas rangkak. limit lalai ialah 10, jadi anda mesti menetapkannya secara eksplisit. depth maksimum juga 100,000. Untuk laman yang melebihi 100K halaman, Scrapy atau perangkak lain tanpa had URL sedia ada diperlukan.
Adakah Cloudflare /crawl mengekstrak JSON-LD atau mengesahkan markup skema?
Tidak. Dengan render: false, tiada data berstruktur diekstrak langsung. Dengan render: true, hanya tag Open Graph asas dikembalikan (og:title, og:description, og:image, og:site_name). JSON-LD, Microdata, dan markup schema.org tidak dihurai, diekstrak, atau disahkan dalam kedua-dua mod.
Berapakah kos Cloudflare /crawl untuk merender laman besar?
Merentasi ujian kami, render: true secara purata kira-kira 5 saat masa pelayar setiap halaman. Laman 256 halaman menggunakan 1,338 saat pelayar (22 minit) dan menelan kos kira-kira $0.03 pada kadar $0.09 setiap jam pelayar. Laman 24 halaman menggunakan 58 saat dan menelan kos kira-kira $0.002. Ekstrapolasi kepada katalog 3,000 halaman: kira-kira 4 jam masa pelayar. Pelan Workers Free dihadkan pada 10 minit sehari, 5 tugas rangkak sehari, dan 100 halaman setiap rangkak, jadi rangkakan dirender besar memerlukan Pelan Workers Paid ($5/bulan), yang termasuk 10 jam masa pelayar sebulan tanpa had setiap rangkak. render: false menggunakan sifar masa pelayar dan percuma semasa beta pada kedua-dua pelan.
Adakah Cloudflare /crawl mempunyai pepijat resolusi URL yang diketahui?
Ya. Dalam ujian kami, 233 daripada 908 pautan pada satu halaman produk mempunyai laluan rosak. Penukar markdown menambah URL halaman di hadapan laluan relatif seperti //www.example.com/cdn/..., menghasilkan URL laluan berganda yang rosak. Ini mempengaruhi mana-mana analisis graf pautan hiliran atau audit pautan dalaman yang dibina daripada output markdown.
Mengapa Cloudflare /crawl dengan render false mengembalikan ralat 429 pada sesetengah kedai Shopify?
render: false melakukan pengambilan HTML mentah tanpa pelayar tanpa kepala. Dalam salah satu ujian kami, render: false mengembalikan ralat 429 manakala render: true berfungsi dengan 100% kejayaan pada kedai yang sama. Kami belum menguji semula ini dengan pengendalian ralat yang lebih baik, jadi 429 mungkin disebabkan oleh pengehadan kadar kedai, isu API sementara, atau gabungan kedua-duanya. Jika anda melihat ralat 429 tanpa rendering, cuba render: true sebagai langkah pertama.
Adakah Cloudflare /crawl menerima senarai URL?
Tidak. Endpoint ini menerima satu URL permulaan dan menemui halaman dengan merangkak keluar melalui peta laman, pautan halaman, atau kedua-duanya. Jika anda sudah mempunyai senarai URL dan mahukan penukaran markdown Cloudflare, gunakan endpoint /markdown atau /scrape yang berasingan, yang menerima URL individu setiap permintaan.
Mengapa Cloudflare /crawl dengan source all hanya menemui satu halaman pada sesetengah laman?
source: all lalai menemui URL daripada kedua-dua peta laman dan pautan halaman. Jika URL permulaan mempunyai sangat sedikit pautan dalaman (biasa pada laman utama minimalis atau SPA berat JavaScript), perangkak mungkin tidak menemui halaman tambahan melalui penemuan pautan sahaja. Tukar kepada source: sitemaps untuk memastikan perangkak membaca sitemap.xml penuh dan menemui semua URL yang disenaraikan.
Apakah cara terbaik menggunakan Cloudflare /crawl dengan saluran rangkak penuh?
Gunakan saluran rangkak penuh (Scrapy atau setara) dahulu untuk menemui URL, membina graf pautan, mengekstrak data berstruktur, menangkap 404, dan mengelaskan kandungan. Kemudian gunakan endpoint /markdown atau /scrape Cloudflare untuk menarik markdown bersih bagi pemarkahan kesediaan LLM, analisis kualiti kandungan, atau pengambilan RAG di mana anda memerlukan teks halaman sebenar dan bukannya metadata berstruktur.
Berapa kali lebih pantas Cloudflare /crawl render false berbanding render true?
Dalam ujian langsung kami pada laman 256 halaman yang sama, render: false selesai dalam kira-kira 5 minit. render: true mengambil masa kira-kira 25 minit untuk halaman yang sama. Itu perbezaan kelajuan 5x. Jurang masa jam dinding datang daripada kira-kira 5 saat pelaksanaan pelayar yang ditambah setiap halaman apabila rendering diaktifkan. render: false menelan kos $0 semasa beta. render: true menelan kos kira-kira $0.03 untuk rangkakan yang sama.
Berapa banyak kandungan tambahan yang ditangkap oleh Cloudflare /crawl render true berbanding render false?
Dalam ujian 256 halaman kami, render: true menghasilkan 12.5 MB markdown berbanding 11.0 MB daripada render: false, peningkatan 14%. Kandungan tambahan datang hampir keseluruhannya daripada elemen yang dimuatkan JavaScript pada laman utama dan halaman indeks blog. Halaman produk individu dan artikel blog hampir sama antara kedua-dua mod. Untuk laman dengan kandungan yang kebanyakannya dirender pelayan, render: false menangkap lebih 90% teks berguna pada kos sifar dan kelajuan 5x lebih pantas.
Adakah Cloudflare /crawl berfungsi dengan boleh dipercayai pada semua kedai Shopify?
Ia bergantung pada kedai dan mod render. Dalam ujian kami merentasi lima kedai Shopify: Store A (katalog besar) mencapai 100% kejayaan dengan render: false. Store B (pakaian sederhana) mencapai 96% kejayaan dengan kedua-dua mod. Store C (kesihatan dan suplemen) mencapai 40% pada sampel 5 halaman dan 89% pada rangkakan 100 halaman dengan render: false, walaupun ujian awal kami kekurangan pemulihan ralat yang teguh dan sesetengah kegagalan mungkin boleh dipulihkan. Store D (kedai kecil) mengembalikan ralat 429 dengan render: false tetapi mencapai 100% dengan render: true. Store E (pelbagai kategori besar, ~1,200 halaman) mencapai 100% kejayaan dengan render: false dan 100% pada sampel 100 halaman yang dirender dengan pengoptimuman penyekatan sumber. Kami belum menguji semula Store C dan D dengan pengendalian ralat yang lebih baik. Uji kedua-dua mod pada kedai khusus anda sebelum menetapkan strategi rangkak.
Berapakah masa jam dinding untuk rangkakan Cloudflare /crawl 500 halaman dengan render false?
Dalam ujian kami, rangkakan 500 halaman render: false selesai dalam kira-kira 18 minit dengan kadar kejayaan 100%. Rangkakan 256 halaman pada kedai berbeza selesai dalam kira-kira 5 minit. Rangkakan 100 halaman selesai dalam kira-kira 3.5 minit. Masa jam dinding ini adalah anggaran berdasarkan selang tinjauan, bukan ukuran tepat. Masa jam dinding terutamanya adalah overhed giliran dan ambilan HTTP dalaman Cloudflare, bukan rendering pelayar, kerana tiada saat pelayar digunakan dengan render: false.
Berapa banyak permintaan pelayan yang dijana oleh Cloudflare /crawl render true?
Dalam analisis log pelayan kami, satu rangkakan render: true bagi 25 halaman menjana 2,234 jumlah permintaan: 2,071 GET dan 163 POST. Itu kira-kira 89 permintaan pelayan bagi setiap halaman sebenar yang dirender. Hanya 1.1% permintaan adalah kandungan halaman sebenar. Baki 98.9% adalah fail JavaScript (75%), beacon analitik (6.3%), CSS (4.3%), piksel penjejak (3.4%), dan pramuat checkout (3.3%). Jika anda memantau trafik bot atau menguruskan beban pelayan, jangkakan rangkakan yang dirender menjana 89x bilangan permintaan halaman sebenar dalam log pelayan anda.
Apakah ejen pengguna yang digunakan oleh Cloudflare /crawl dan dari julat IP manakah ia datang?
Perangkak mengenal pasti dirinya sebagai CloudflareBrowserRenderingCrawler/1.0 pada 100% permintaan. Dalam log kami, semua permintaan datang daripada 23 IP unik dalam julat 104.28.x.x yang diedarkan merentasi 5 pusat data Cloudflare AS: ATL (38%), ORD (25%), MIA (23%), EWR (9%), dan IAD (5%). Tiada putaran ejen pengguna atau penyamaran IP. Perangkak ini adalah bot bertandatangan dan boleh dikenal pasti secara reka bentuk.
Adakah Cloudflare /crawl menginflasikan analitik Shopify dan kiraan pelawat?
Kami percaya ya, tetapi belum mengesahkannya secara langsung dalam pelaporan Shopify. Kerana render: true melaksanakan JavaScript, ia mencetuskan timbunan analitik penuh Shopify pada setiap halaman: beacon monorail, peristiwa penjejakan /api/collect, pramuat checkout Shop Pay, dan skrip kotak pasir web-pixel. Dalam ujian kami, 163 daripada 2,234 permintaan adalah permintaan POST ke endpoint analitik Shopify. Ini adalah peristiwa yang sama yang dicetuskan untuk pelanggan sebenar. Jika Shopify mengira ini sebagai sesi sebenar, kiraan sesi, paparan halaman, dan data corong penukaran anda akan diinflasikan.
Bagaimanakah anda boleh mengesan Cloudflare /crawl dalam log pelayan berbanding trafik pelayar sebenar?
Dua jurang cap jari yang boleh dipercayai: renderer pelayar Cloudflare tidak menghantar pengepala Client Hints sec-ch-ua (pelayar Chrome sebenar sentiasa menghantar ini), dan semua permintaan menggunakan HTTP/1.1 dan bukannya HTTP/2 atau HTTP/3 yang akan dirunding oleh pelayar sebenar. Ia menghantar pengepala sec-fetch-dest, sec-fetch-mode, dan sec-fetch-site yang betul yang sepadan dengan Chrome sebenar. Ejen pengguna sentiasa CloudflareBrowserRenderingCrawler/1.0 dan semua IP berada dalam julat 104.28.x.x.